华为最强云端AI芯片商用,性能超英伟达

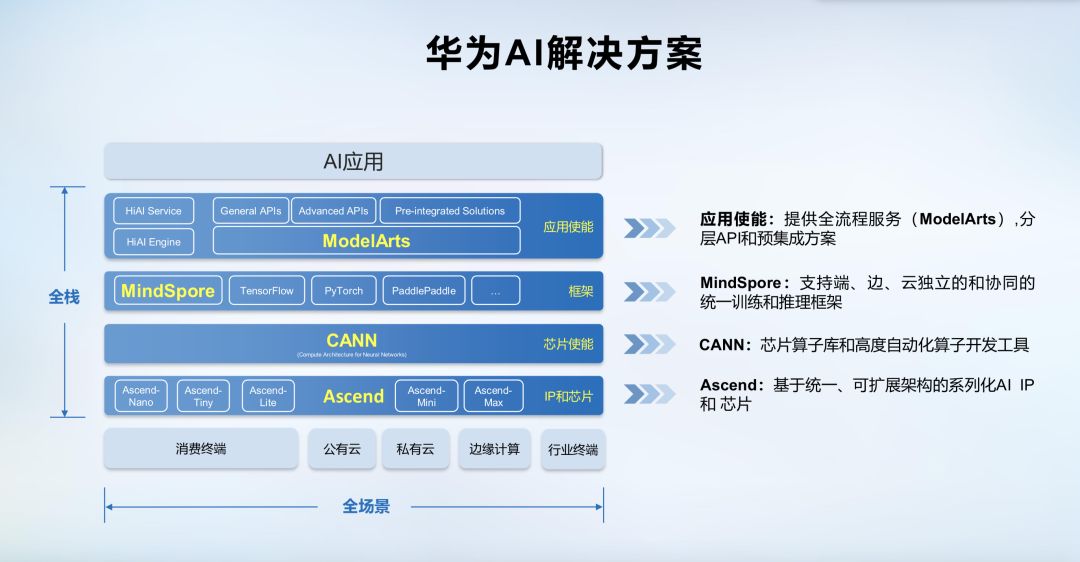
在去年10月10日的2018华为全联接大会(HUAWEI CONNECT)上,华为轮值CEO徐直军公布了华为全栈全场景AI解决方案,并正式宣布了两款AI芯片:算力最强的昇腾910和最具能效的昇腾310。经过近一年的时间。今天(8月23日),华为正式宣布昇腾910成功商用,同时推出全场景AI计算框架MindSpore。
最强AI芯片昇腾910
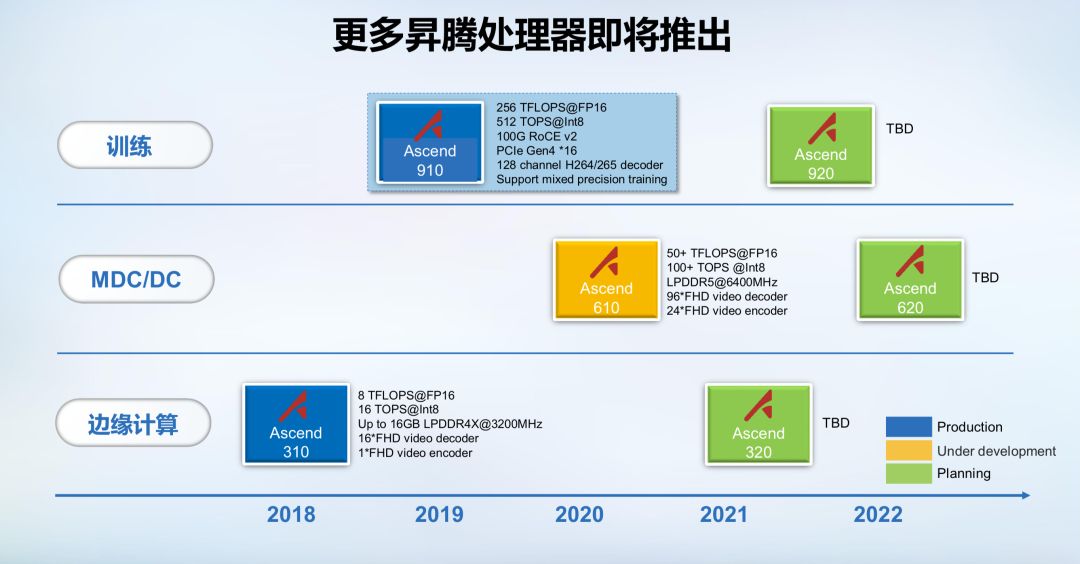
跟之前公布的参数一样,昇腾910是目前单芯片计算密度最大的芯片,采用7nm 增强版 EUV 工艺,单 Die 内建 32 颗达芬奇核心,半精度 (FP16)算力达到256 Tera-FLOPS,整数精度 (INT8) 算力达到512 Tera-OPS,最大功耗为350W。支持128通道 全高清 视频解码器- H.264/265。

另外根据华为此前公布昇腾910的性能与谷歌TPU v2、谷歌TPU v3、英伟达V100对比数据来看,昇腾910的算力比Nvidia 的 V100 还要高出一倍,计算力远超谷歌及英伟达。
现场,徐直军先介绍了华为AI解决方案,以及基于昇腾310的产品和云服务的广泛应用。
接着,徐直军说:“我宣布,算力最强的AI处理器 Ascend 910 正式推出。去年10月,我们发布了Ascend 910的技术规格,今天我向大家介绍最新的实际测试结果。”
半精度 (FP16)算力达到256 Tera-FLOPS
整数精度 (INT8) 算力达到512 Tera-OPS
而且,达到规格算力所需功耗仅310W,明显低于设计规格的350W。
高算力、高集成度、高速互联,便共同铸造了 业界最强大的 AI 处理器 —— 昇腾 910。

基于达芬奇架构的 AI 核是计算核心。除了标量和矢量计算单元,AI 核集成了 3D 立方体计算引擎,能够在一个时钟周期内完成 4096 的乘加运算。

与 CPU 和 GPU 相比,有两个数量级的提升,昇腾 910 集成了 32 个立方体计算引擎,能够输出 256TFLOPS。

它不仅是一颗强大的 AI 计算处理器,而且还是一个高度集成的片上系统,集成了 CPU、DVPP 以及任务管理器。
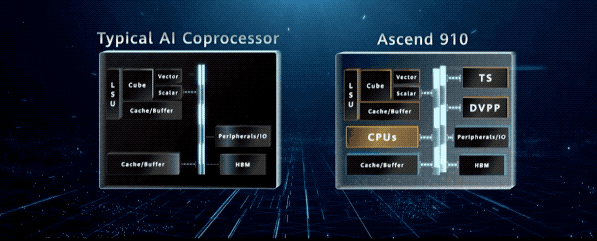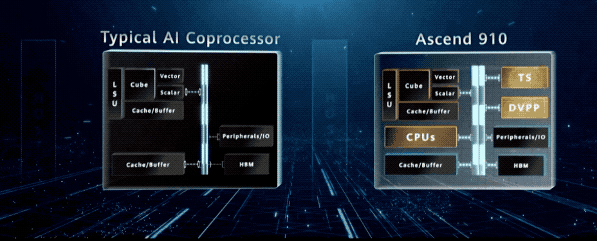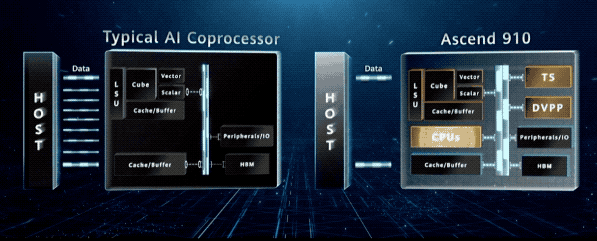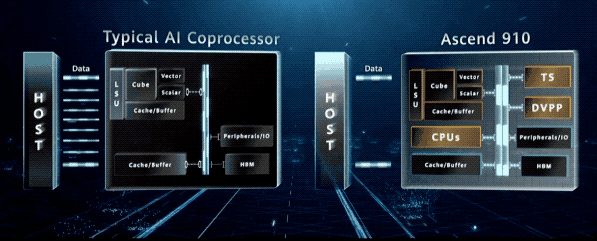
这些单元给昇腾 910 提供了一种 “自治” 能力,使其可以独立完成整个 AI 的训练流程,最小化与 Host 的交互,从而充分发挥其算力。
创建一个强大的训练系统不仅需要芯片自身强大的算力,高效的通信机制也是必不可少的。

昇腾 910 集成了 HCCS、PCIe 和 RoCE 三种高速接口。

其中,自研的 HCCS 可以提供单接口 240Gbps 的传输。

也正是采用了最新的 PCIe,使得吞吐量比上一代翻倍。

而芯片上集成的 RoCE 接口,则为多节点间提供了高效的数据交互的互联方案,这些互联技术大幅提升了构建训练系统的性能和灵活性。
最后,现场有记者问道,昇腾 910 售价多少呢?毕竟我们知道英伟达的 GPU 和谷歌的 TPU 都有定价。
徐直军笑道:“售价具体还没定出来,但肯定不会比他们(英伟达 GPU和谷歌 TPU)高。”
此外,徐直军还发布了全场景AI计算框架 MindSpore,并宣布“MindSpore将在2020年Q1开源”!

徐直军表示:能否大大降低AI应用开发的门槛,能否实现AI将无处不在,能否在任何场景下确保用户隐私得到尊重和保护,这些都与AI计算框架息息相关。
在去年HC会上,华为提出:AI框架应该是开发态友好(例如显着减少训练时间和成本)和运行态高效(例如最少资源和最高能效比),更重要的是,要能适应每个场景包括端、边缘和云。
一年后的今天,全场景AI计算框架MindSpore在这三个方面都取得了显著的进展:在原生适应每个场景包括端,边缘和云,并能够按需协同的基础上,通过实现AI算法即代码,使开发态变得更加友好,显著减少模型开发时间,降低了模型开发门槛。
MindSpore如何做到更快更高效?
MindSpore秉承“AI算法即代码”理念,提供一系列的关键技术,例如MindSpore自动微分,采用Source 2 Source方式实现,在性能和可编程性上,明显优于业界图和运算符重载方式。能够实现任意算子的微分表达和编译优化,同时实现反向算子自动生成,极大地方便了模型开发。



编辑:芯智讯-林子 来源:新智元
Xilinx推出全球最大FPGA:拥有900万个系统逻辑单元,350亿个晶体管!
行业交流、合作请加微信:icsmart01
芯智讯官方交流群:221807116
 扫一扫下载订阅号助手,用手机发文章
扫一扫下载订阅号助手,用手机发文章 
朋友会在“发现-看一看”看到你“在看”的内容