李飞飞的又一位得意门生走向了教学岗位:昨天,刚刚毕业的斯坦福博士朱玉可(Yuke Zhu)宣布即将在 2020 年秋季加入德克萨斯大学奥斯汀分校(The University of Texas at Austin)任助理教授。
作为斯坦福视觉与学习实验室的成员,朱玉可师从李飞飞与 Silvio Savarese 教授。他因在 SURREAL 机器人框架研究中的贡献而被人所熟知。此外,朱玉可还作为共同第一作者获得了国际机器人顶会 ICRA 2019 的最佳论文奖。
朱玉可在 Twitter 上发布的信息:本人已于 2019 年 8 月取得斯坦福大学博士学位,并将于 2020 年秋季加入德克萨斯大学奥斯汀分校(UT-Austin)担任计算机科学助理教授。我非常期待与那些对 AI+机器人学充满热情和积极性的优秀学生共同进步。如果有兴趣加入我的实验室,请发邮件给我。
根据朱玉可的个人主页,他的科研兴趣是为能够理解并与现实世界交互的通用机器人构建智能。研究将融合机器人、计算机视觉和机器学习等诸多领域,并致力于开发用于通用机器人自治的感知和控制方法和机制。
在斯坦福大学,他与李飞飞和 Silvio Savarese 教授(李飞飞的丈夫)一起在斯坦福视觉与学习实验室工作。同时,他也是斯坦福人工智能和机器人研究小组(Stanford People, AI & Robots Group,PAIR)成员。
今年 6 月,朱玉可在斯坦福大学的博士论文答辩后,与李飞飞等人合影。
虽然朱玉可还没有开始任教,但你很可能已经听过他讲课了。在斯坦福大学期间,朱玉可还参与了一些课程的教学工作——其中包括著名的 CS 231N:视觉识别中的卷积神经网络。此外还有 CS 131、CS 193C、CS 431 等。
朱玉可的求学履历可谓豪华。本科阶段,他参与了联合培养项目,取得了浙江大学和加拿大西蒙弗雷泽大学(Simon Fraser University,简称 SFU)的双学位,并在所有学生中成绩排名第一。
朱玉可曾荣获浙江省第八届 ACM 大学生程序设计竞赛金牌、浙江大学第十一届大学生程序设计竞赛一等奖以及加拿大西蒙弗雷泽大学第八届年度冬季程序设计竞赛第一名。
他硕士和博士研究生均就读于斯坦福大学,师从计算机视觉大牛李飞飞,于今年 8 月取得博士学位。
自 2011 年起,朱玉可曾先后在加拿大西蒙弗雷泽大学视觉与媒体实验室(Vision and Media Lab)、推特、Snap、艾伦人工智能研究所、DeepMind 等公司和科研机构担任研究实习生。此外,自进入斯坦福大学攻读硕博研究生起,朱玉可就担任了教学助理和助理研究员。
在斯坦福大学攻读博士期间,朱玉可曾有多篇论文被各类人工智能大会接收,并获得过一些奖项。目前,朱玉可有 1 篇论文被 ECCV 接收,另外还有 3 篇 ICCV,5 篇 CVPR 和 3 篇 ICRA。
其实早在本科学习期间,他的论文《Graphical Model-based Learning in High Dimensional Feature Spaces》就被 AAAI 2013 接收了。
今年 5 月,在加拿大蒙特利尔举行的机器人顶级会议 ICRA 大会公布了最佳论文奖项,来自斯坦福大学李飞飞组的研究《Making Sense of Vision and Touch: Self-Supervised Learning of Multimodal Representations for Contact-Rich Tasks》获得了最佳论文。
该研究有关在非结构化环境中执行需要大量接触的操纵任务。通过自监督学习感知输入的紧凑、多模态表征,然后使用表征提升策略学习的样本效率。研究者在植入任务上评估了新方法,其结果表明该方法对于外部扰动具备稳健性,同时可以泛化至不同的几何、配置和间隙(clearances)。研究者们还展示了新方法在模拟环境中和真实机器人上的结果。
朱玉可在李飞飞夫妇带领的斯坦福大学计算机视觉与学习实验室的一个团队中也扮演着重要角色。
该团队开发了两个机器人学习框架——RoboTurk 和 SURREAL,能够让机器人快速学习抓握、分拣等基础技能。其中,RoboTurk 是一个快速众包制造大规模机器人控制数据集的平台,可以让机器人研究者快速收集数据,打造机器人界的「ImageNet」,以填补这一领域缺乏数据集的空白。有了数据集,还需要鲁棒的算法。为此,李飞飞团队开发了分布式强化学习训练框架 SURREAL,用来加速学习过程,而朱玉可正是这一项目背后的一作之一。

可复现性一直都是深度强化学习和机器人研究中的一大挑战,朱玉可等人设计的 SURREAL 作为一个开源框架,可以在严格的评估和可复现研究中发挥重要作用。SURREAL 是一个可扩展的框架,支持当前最先进的分布式强化学习算法。他们设计了一个原则性的分布式学习平台,既能适应策略上的学习,也能适应政策外的学习。他们还证明了 SURREAL 算法在智能体性能和学习效率方面都优于原有的开源实现。
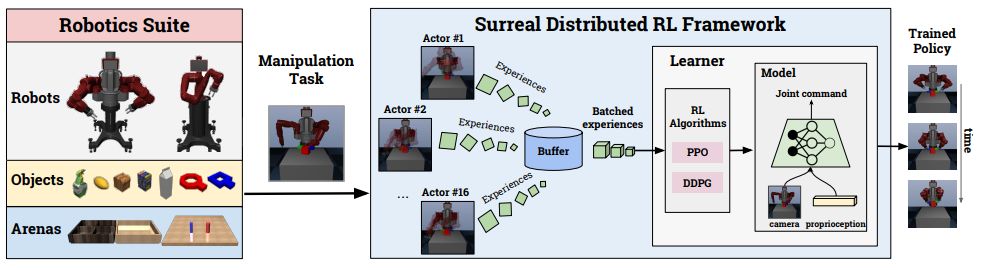
SURREAL 是一个开源的框架,旨在促进机器人操纵可复现深度强化学习研究。
✄------------------------------------------------加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com投稿或寻求报道:content@jiqizhixin.com广告 & 商务合作:bd@jiqizhixin.com



 扫一扫下载订阅号助手,用手机发文章
扫一扫下载订阅号助手,用手机发文章 
朋友会在“发现-看一看”看到你“在看”的内容