Apache Beam实战指南 | 结合Hive设计数据处理流程

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
关于 Apache Beam 实战指南系列文章
随着大数据 2.0 时代悄然到来,大数据从简单的批处理扩展到了实时处理、流处理、交互式查询和机器学习应用。近年来涌现出诸多大数据应用组件,如 HBase、Hive、Kafka、Spark、Flink 等。开发者经常要用到不同的技术、框架、API、开发语言和 SDK 来应对复杂应用的开发,这大大增加了选择合适工具和框架的难度,开发者想要将所有的大数据组件熟练运用几乎是一项不可能完成的任务。
面对这种情况,Google 在 2016 年 2 月宣布将大数据流水线产品(Google DataFlow)贡献给 Apache 基金会孵化,2017 年 1 月 Apache 对外宣布开源 Apache Beam,2017 年 5 月迎来了它的第一个稳定版本 2.0.0。在国内,大部分开发者对于 Beam 还缺乏了解,社区中文资料也比较少。InfoQ 期望通过 Apache Beam 实战指南系列文章 推动 Apache Beam 在国内的普及。
大数据处理其实经常被很多人低估,缺乏正确的处理体系,其实,如果没有高质量的数据处理流程,人工智能将只有人工而没有智能。现在的趋势是数据体量不断上涨,团队却低估了规模所带来的复杂度。大数据领域泰斗级人物 Jesse Anderson 曾做过研究,一个组织架构比较合理的人工智能团队,数据处理工程师需要占团队总人数的 4/5,然而很多团队还没有认识到这点。大数据处理涉及大量复杂因素,而 Apache Beam 恰恰可以降低数据处理的难度,它是一个概念产品,所有使用者都可以根据它的概念继续拓展。
Apache Beam 提供了一套统一的 API 来处理两种数据处理模式(批和流),让我们只需要将注意力专注于数据处理的算法上,而不用再花时间去维护两种数据处理模式上的差异。
ETL 是大数据处理流程中常见的过程,用来描述将数据从源端抽取(Extract)、转换(Transform)、加载(Load)至端的过程,下面将通过一个 ETL 案例介绍如何基于 Beam 构建数据处理流程。在这个案例中,数据源为 Hive,本文会概括地介绍 Beam 常用处理流程,让大家更容易感知 Beam 的特性,中间也会穿插原理介绍和感悟,通过把整个数据流水线(Pipeline)处理流程打通,帮助读者了解用 Beam 做大数据处理的优势。
在本文的案例中,我们假设 Hive 中有两张数据源表,两个表数据格式一样,我们要做的是:按照日期增量,新版本根据字段修改老版本的数据,再增量一部分新的数据,最后生成一张结果表。这个案例可以把常用的 Beam 数据处理方法的 80% 概括出来,让大家更容易地理解 Beam 数据处理流程。
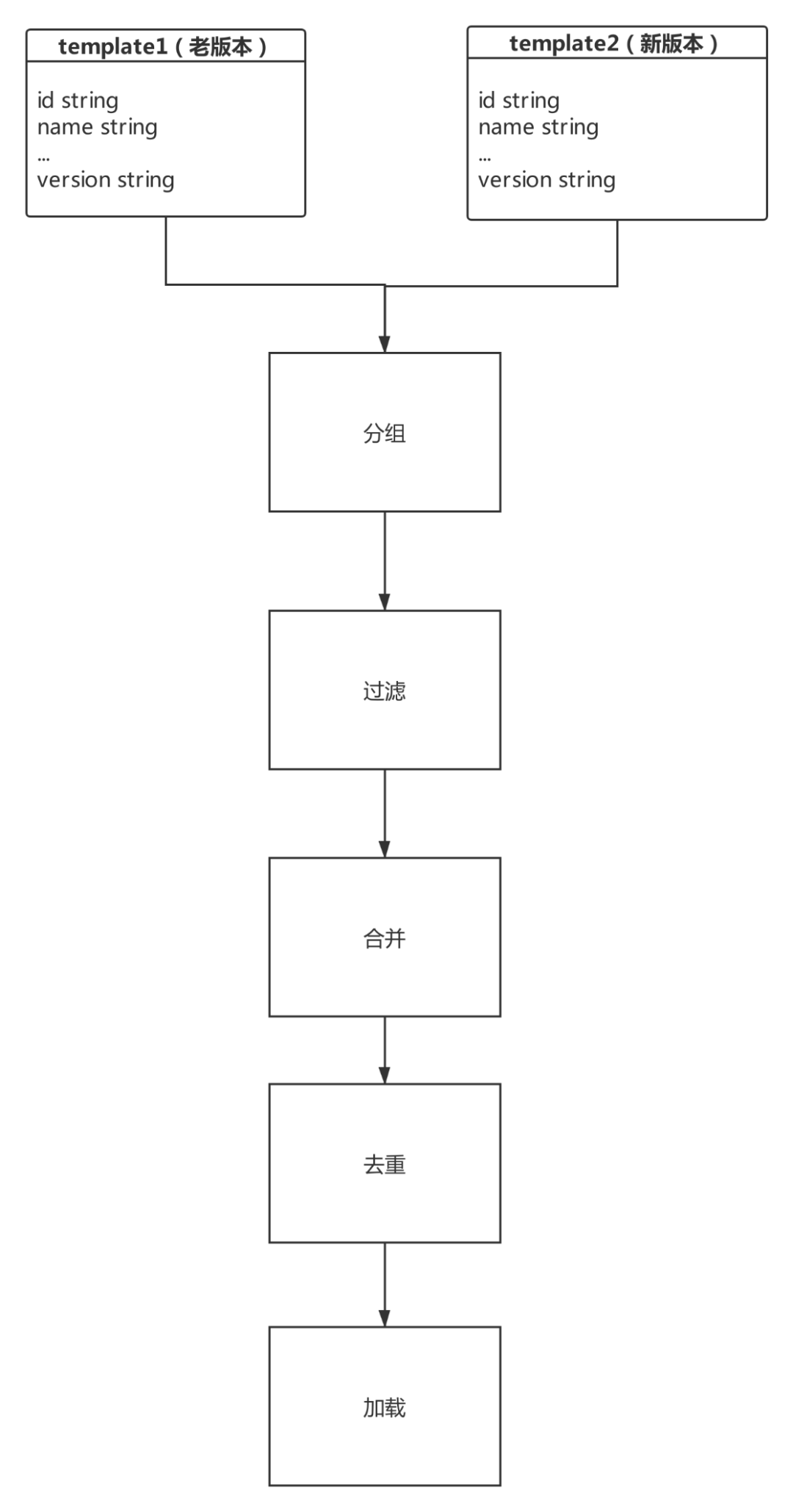
架构流程图
准备好源数据(ODS)两张版本表。 分组,分成两个标记集合(PCollection)。 过滤,旧的集合根据新版本(PCollection)标识字段过滤修改旧版本数据。 合并,旧版本数据合并新版本数据,生成集合(PCollection)。 去重,合并生成 PCollection,根据版本字段去重。 加载,转存成一张结果表。
Hive 是一款数据仓库软件,通过 SQL 使得分布式存储系统中的大数据集(Hdfs 等等)的读、写和管理变得更容易。
Hive 的两个客户端:
CliDriver 是 SQL 本地直接编译,然后访问 MetaStore,提交作业,是重客户端。 BeeLine 是把 SQL 提交给 HiveServer2,由 HiveServer2 编译,然后访问 MetaStore,提交作业,是轻客户端。HiveServer2 和 MetaStore 一般在不同进程中。HiveServer2 用来访问数据的,MetaStore 用来访问元数据。
Apache Beam 对 Hive 支持依赖情况
Beam sdks 中的 io 包,JdbcIO 和 HCatalogIO 都可以操作 Hive,这两种 API 的区别对应上述 HiveServer2 和 MetaStore,JdbcIO 可以支持更复杂的操作。案例中 Beam 版本为 2.9,2.6 版本以后都比较稳定。
Apache Beam 启动
// 这个 PipelineOptions 有很多种,可以自己设定引擎,可以自定义 PipelineOptions 对象,接收字符串数组转换为 PipelineOptions 对象。
PipelineOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(SparkPipelineOptions.class);
Pipeline pipeline = Pipeline.create(options);
// 业务代码…
// 启动
pipeline.run().waitUntilFinish();
JdbcIO 提取 Hive 数据
PCollection<Row> t1 = pipeline.apply(JdbcIO.<Row>read().withDataSourceConfiguration(JdbcIO.DataSourceConfiguration
.create(cpds)).withCoder(SchemaCoder.of(type)).withQuery("select * from template1").withRowMapper(new JdbcIO.RowMapper<Row>() {...}));
PCollection<Row> t2 = pipeline.apply(JdbcIO.<Row>read().withDataSourceConfiguration(JdbcIO.DataSourceConfiguration
.create(cpds)).withCoder(SchemaCoder.of(type)).withQuery("select * from template2").withRowMapper(new JdbcIO.RowMapper<Row>() {...}));
获取两个版本的数据集,PCollection 是可并行计算数据集,都有 Coders 通信编码,没有固定大小(有限集和无限集都可以标识),无序(分布式的原因),不可变性。
注意:
JdbcIO.DataSourceConfiguration 可以传参连接信息,也可以传 dataSource 对象,直接传 Hive URL 信息等连接不上,本案例中传的连接池对象必须先序列化。
JdbcIO 源码中,连接关系型数据库没有问题,在连接 Hive 时映射 HivePreparedStatement 预处理对象,这个对象有些没有实现的方法会被自动调用,比如 executeBatch,没有批量操作的实现,修改源码或者屏蔽错误都行,不影响后续操作。
HCatalogIO 提取 Hive 数据
Map<String, String> configProperties = new HashMap<String, String>();
configProperties.put("hive.metastore.uris","thrift://ip:9083");
PCollection<HCatRecord> collection = pipeline
.apply(HCatalogIO.read()
.withConfigProperties(configProperties)
.withDatabase("default")
.withTable(""));
注意:使用 HCatalogIO 需要注意 Beam 版本,在 Beam 源码中有个 Hive 版本,比如案例中使用的版本是 Beam2.9 Hive1.2, 因为 Hive1.2 以后才可以用 HCatalogIO 对象,不然会报错,缺少方法。
上述提取流程生成了两个 PCollection,单靠数据集合无法构成一个数据处理框架,Beam 中数据处理的最基本单元是 Transform。Beam 提供了最常见的 Transform 接口,比如 ParDo、GroupByKey,其中 ParDo 更为常用。
ParDo 就是 Parallel Do 的意思,表达的是很通用的数据处理操作;GroupByKey 的意思是把一个 Key/Value 的数据集按 Key 归并。
注意:可以用 ParDo 来实现 GroupByKey,一种简单的方法就是放一个全局的哈希表,然后 ParDo 里把一个一个元素插进这个哈希表里。但这样的实现方法其实无法使用,因为你的数据量可能完全无法放进一个内存哈希表。
使用 ParDo 时,需要继承它提供 DoFn 类,可以把 DoFn 看作 ParDo 的一部分, Transform 是一个概念方法,里面包含一些转换操作。
DoFn 的模板:
static class DoFnTest<T> extends DoFn<T,T>{
@Setup
public void setUp(){...}
@StartBundle
public void startBundle(){...}
@ProcessElement
public void processElement( ProcessContext c) {...}
@FinishBundle
public void finishBundle(){...}
@Teardown
public void teardown(){...}
}
处理某个 Transform 的时候,数据是序列化的(PCollection),Pipeline 注册的流水线会将这个 Transform 的输入数据集 PCollection 里面元素分割成不同的 Bundle,再将这些 Bundle 分发给不同的 Worker 来处理。Beam 数据流水线具体会分配多少个 Worker,以及将一个 PCollection 分割成多少个 Bundle 都是随机的,具体跟执行引擎有关,设计到不同引擎的动态资源分配,可以自行查阅资料。
Transform 调用 DoFn 时,@Setup 初始化资源,@Teardown 处理实例调用完以后,清除资源,防止泄露。@StartBundle 方法跟 Bundle 有关,在 Bundle 中每个输入元素上调用 @ProcessElement(类似 map 输入每行数据),如果提供 DoFn 的 @FinishBundle 调用它,(Bundle 中数据流完)调用完成 @FinishBundle 之后,下次调用 @StartBundle 之前,框架不会再次调用 @ProcessElement 或 @FinishBundle。
如果处理 Bundle 的中间出现错误,一个 Bundle 里面的元素因为任意原因导致处理失败了,则这整个 Bundle 里面都必须重新处理。
在多步骤 Transform 中,如果一个 Bundle 元素发生错误了,则这个元素所在的整个 Bundle 以及与这个 Bundle 有关联的所有 Bundle 都必须重新处理。
数据处理示例
static class generate extends PTransform<PCollectionList<Row>,PCollection<Row>>{
private final String version;
public generate(String version) {
this.version = version;
}
@Override
public PCollection<Row> expand(PCollectionList<Row> input) {
// 旧版本
PCollection<Row> p1 = null;
// 新版本
PCollection<Row> p2 = null;
// 分组
List<PCollection<Row>> all = input.getAll();
for(PCollection<Row> p:all){
if(p.getName().equals("l1")){
p1 = p;
}else if(p.getName().equals("l2")){
p2 = p;
}
}
// 过滤
// 视图
PCollectionView<Iterable<Row>> v2 = p2.apply(View.asIterable());
// 过滤出老版本数据加上修改完的数据
PCollection<Row> f1=p1.apply(ParDo.of(new DoFn<Row, Row>() {
@ProcessElement
public void processElement(@Element Row row1, OutputReceiver<Row> out, ProcessContext c) {
Iterable<Row> rows = c.sideInput(v2);
Row element = c.element();
Iterator<Row> iterator = rows.iterator();
boolean status =true;
while (iterator.hasNext()){
Row next = iterator.next();
String version2 = next.getString(version);
String version1 = element.getString(version);
if(version1.equals(version2)){
// 新版修改数据输出
out.output(next);
status = false;
}
}
if(status){
out.output(element);
}
}
}).withSideInputs(v2));
// 合并
PCollection<Row> mergeds = PCollectionList.of(f1).and(p2).apply(Flatten.<Row>pCollections());
// 去重
PCollection<Row> result = mergeds.apply(Distinct.withRepresentativeValueFn(new SerializableFunction<Row, String>() {
@Override
public String apply(Row input) {
return input.getString(version);
}
}).withRepresentativeType(TypeDescriptor.of(String.class)));
return result;
}
}
案例中使用自定义 PTransform 把多个 DoFn 方法操作合并在一个 Transform,注册到 Pipeline 中运行。
Beam 编程范式是基于函数的,实体对象间相互转换少,中间结果落地的数据类型可以用 Beam 包中的 Row 等,如果要使用自定义对象注意序列化,因为项目是在分布式环境下运行,需要编码通信。
把老版本 PCollection 和新版本 PCollection 合并成 PCollectionList,调用这个自定义 Transform。 设定构造函数,参数 version 代表根据这个字段名称合并。 分组,根据 PCollection 的名称,名称自定义,可以拆分成老版本 p1(PCollection), 和新版本 p2(PCollection)。 过滤,先根据新版本数据 PCollection,生成 PCollectionView,这个 PCollectionView 是不可变视图。sideInput 特性把视图输入 DoFn 中调用,根据 Transform 的 version 版本字段名称比较是否存在新版本数据,最后这个 DoFn 两个出口输出数据,一个是输出修改数据,一个输出老版本但不再修改列表的数据 。 注意:DoFn 是无状态的,它有局限,比如 DoFn 引入共享变量,需要不断调用,如果数据在数据库中,得不断连接库,Beam 不仅会把处理函数分发到不同线程、进程,也会分发到不同的机器上,很可能引发服务器 QPS 过高。Beam 提供共享状态 Side input/output,在上述案例中,我把新版本数据视图递进 DoFn 中,根据 ProcessContext 获取这个集合(Iterable rows = c.sideInput(v2))。
合并,根据 Flatten 合并 PCollection,底层源码遍历 PCollectionList 集合,根据 Bundle 的 WindowingStrategy 特定集合属性,合并同类 Bundle,合并成 PCollection。 去重,如果基本类型可以直接 Distinct.create(),我这里根据 version 字段去重,自定义输出标识,Distinct 源码根据标识 Combine 分组合并,判断分组后 PaneInfo 对象信息。
补充:
PCollection 意思是可并行计算的数据,懒加载的,跟 Spark 的 RDD 相似。
不要过度优化代码,比如把操作都放在一个 DoFn 中,因为 Pipeline 最后运算有自己的优化策略,拆分出来 Transform 会被 Beam 的优化器合并操作。
JdbcIO 保存数据
Result.apply(JdbcIO.<Row>write().withDataSourceConfiguration(
JdbcIO.DataSourceConfiguration.create(cpds)).withStatement(sql)
.withPreparedStatementSetter(
(element, statement) -> {
statement.executeUpdate();
}));
PCollection 通信类型保持一致,可以批量插入,放到 withPreparedStatementSetter 操作。
HCatalogIO 保存数据
Result.apply(HCatalogIO.write()
.withConfigProperties(configProperties)
.withDatabase("default")
.withTable("")
.withPartition(partitionValues) // 分区,可以不传
.withBatchSize(1024L)) // 批量保存,默认 1024L
PCollection 通信类型保持一致。
案例中使用的 pom 文件
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<spark.version>2.1.1</spark.version>
<hadoop.version>2.7.3</hadoop.version>
<beam.version>2.9.0</beam.version>
<scala.compat.version>2.11</scala.compat.version>
<hive.version>1.2.0</hive.version>
</properties>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-spark</artifactId>
<version>${beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>${beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>${beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-hcatalog</artifactId>
<version>${beam.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-hadoop-common</artifactId>
<version>${beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-hadoop-file-system</artifactId>
<version>${beam.version}</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-jdbc</artifactId>
<version>${beam.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-avatica</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive.hcatalog</groupId>
<artifactId>hive-hcatalog-core</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-common</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.5.3</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.13</version>
</dependency>
<dependency>
<groupId>com.google.auto.value</groupId>
<artifactId>auto-value-annotations</artifactId>
<version>1.6</version>
</dependency>
运行
Pipeline 调用注册生成的流水线,根据设定不同引擎,可以做到到处运行。
补充
自定义 I/O 连接器可以有以下方法:ParDo 和 GroupBy 来模拟读取数据的逻辑;继承 BoundedSource 抽象类来实现一个子类读取逻辑;如果读取数据是无界的,继承 UnboundedSource 抽象类来实现一个子类去实现读取逻辑。官方推荐第一种方法。
大数据处理有自己的设计模式,常见的有复制模式、过滤模式、分离模式(判断条件,分离集合)、合并模式,在上述案例中用 Beam 操作数据处理穿插用了这些设计模式。
其实这些大数据处理引擎就是大数据处理框架本身,Beam 做了抽象,可以轻松切换不同的引擎,通过统一 API 降低学习成本,大数据工程师就可以更加专心去应对架构的复杂度(性能、扩展、可用、安全、成本等等),不必担心迁移问题。正如我开篇说的 Beam 是一个概念产品,所有人都是用户,Beam 提供了很多灵活的自定义操作,使用时需要对一些扩展包源码熟悉。上述案例覆盖了 Beam 常用的数据处理方法的 80%,Beam 的离线和实时处理方法是可以复用的。本文在此抛砖引玉,未来 Beam 的易用性会越来越高,希望能有更多人来使用。
李孟,目前就职于知因智慧数据科技有限公司,负责数据中台数据引擎基础架构设计和中间件开发,专注云计算大数据方向。最后感谢张海涛老师审核,我也是 Apache Beam 社区一员,想加入社区可以添加微信号 cyrjkj。
系列文章传送门:
系列文章第一篇 《Apache Beam 实战指南 | 基础入门》 系列文章第二篇 《Apache Beam 实战指南 | 手把手教你玩转 KafkaIO 与 Flink》 系列文章第三篇 《Apache Beam 实战指南 | 手把手教你玩转大数据存储 HdfsIO》 系列文章第四篇 《Apache Beam 实战指南 | 如何结合 ClickHouse 打造“AI 微服务”?》 系列文章第五篇 《Apache Beam 实战指南 | 大数据管道 (pipeline) 设计及实战》


你也「在看」吗?👇
 扫一扫下载订阅号助手,用手机发文章
扫一扫下载订阅号助手,用手机发文章 
朋友会在“发现-看一看”看到你“在看”的内容