特斯拉自动驾驶FSD芯片NPU详解

特斯拉的FSD芯片是在年度IEEE Hot Chips大会上众多出色的演讲之一。特斯拉在今年4月首次公开了其全自驾(FSD)芯片。在最近的“ Hot Chips 31”会议上,特斯拉对芯片的一些关键组件提供了更多的解析。
特斯拉工程师为FSD芯片和平台制定了许多主要目标。他们希望在功率范围内尽可能多地封装TOPS。出于安全原因,芯片的主要设计要点是批量使用一个芯片时,更好的提高芯片的利用率。值得注意的是,FSD芯片随附了一组用于通用处理的CPU和一个用于后处理的轻量级GPU,这不在本文的讨论范围之内。
NPU
尽管芯片上的大多数逻辑都使用经过行业验证的IP块来降低风险并加快开发周期,但Tesla FSD芯片上的神经网络加速器(NPU)是由Tesla硬件团队完全定制设计的。它们也是FSD芯片上最大的组件,也是最重要的逻辑部分。
特斯拉谈论的一个有趣的花絮是仿真。在开发过程中,特斯拉希望通过运行自己的内部神经网络来验证其NPU性能。因为他们没有尽早进行仿真,所以需要借助于使用开源的Verilator验证模拟器,其运行速度比商业模拟器快50倍。“我们广泛使用Verilator来证明我们的设计非常出色,”特斯拉自动驾驶硬件高级总监Venkataramanan说。
每个FSD芯片内部有两个相同的NPU –在物理上彼此相邻集成。当被问及拥有两个NPU实例而不是一个更大的单元的原因时,特斯拉指出,每个NPU的大小都是物理设计(时序,面积,布线)的最佳选择。
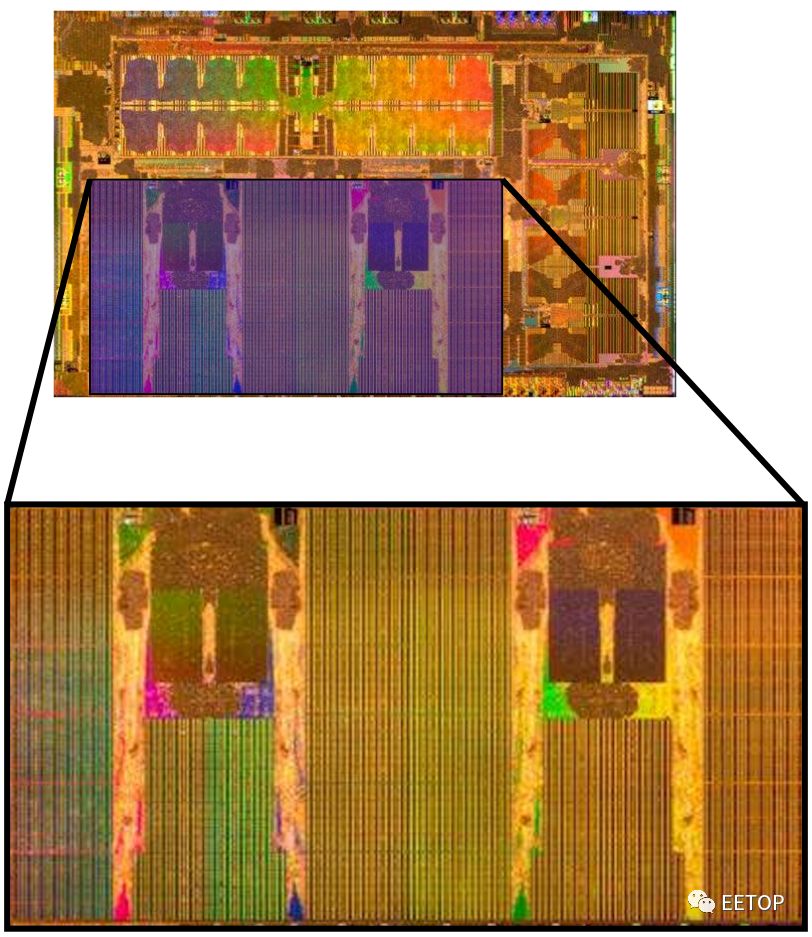
指令集(ISA)
NPU是具有乱序内存子系统的有序计算机。总体设计有点像是一种状态机。指令集比较简单,只有8条指令:DMA Read,DMA Write,Convolution,Deconvolution,Inner-product,Scale,Eltwidth,Stop。NPU只是运行这些命令,直到碰到停止命令为止。还有一个额外的参数slots ,可以更改指令的属性(例如,卷积运算的不同变体)。有一个标志slots ,用于数据依赖性处理。还有另一个扩展slots 。该slots 存储了整个微程序命令序列,每当有一些复杂的后处理时,这些序列就会发送到SIMD单元。因为这,指令从32字节一直到非常长的256字节不等。稍后将更详细地讨论SIMD单元。
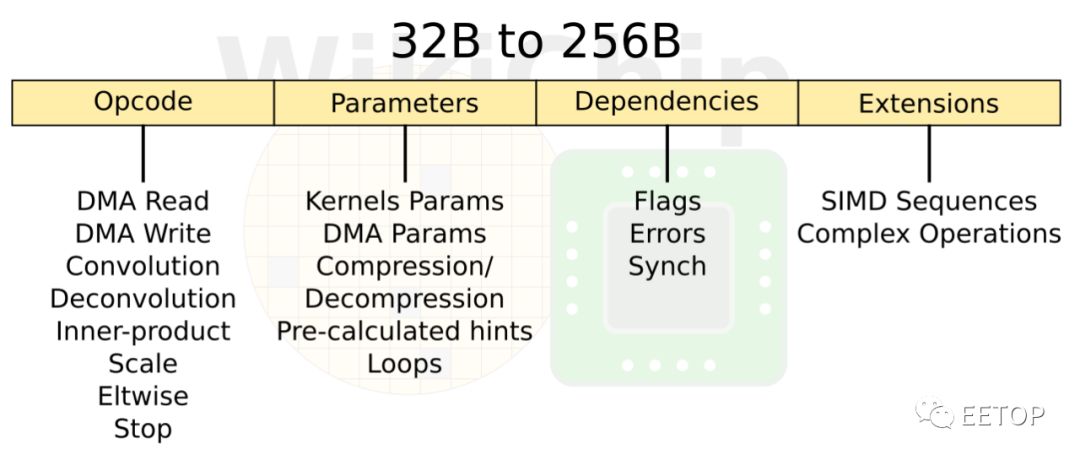
初始操作
NPU的程序最初驻留在内存中。它们被带入NPU,并存储在命令队列中。NPU本身是一个非常花哨的状态机,旨在显着减少控制开销。来自命令队列的命令连同需要从中获取数据的一组地址一起解码为原始操作-包括权重和数据。例如,如果传感器是新拍摄的图像传感器照片,则输入缓冲区地址将指向该位置。一切都存储在NPU内部的超大缓存中,不需要与DRAM交换数据。
高速缓存的容量为32 MB,有一个完善的bank仲裁程序,与一些编译器提示一起,用于减少bank冲突。每个周期中,最多可以将256个字节的数据读取到数据缓冲区中,并且最多可以将128个字节的权重读取到权重缓冲区中。根据步幅,NPU可能在操作开始之前将多条线路带入数据缓冲区,以实现更好的数据重用。每个NPU的组合读取带宽为384B/周期,其本地缓存的峰值读取带宽为786GB/s。特斯拉表示,这使他们能够非常接近维持其MAC所需的理论峰值带宽,通常利用率至少为80%,而很多时候则要达到更高的利用率。
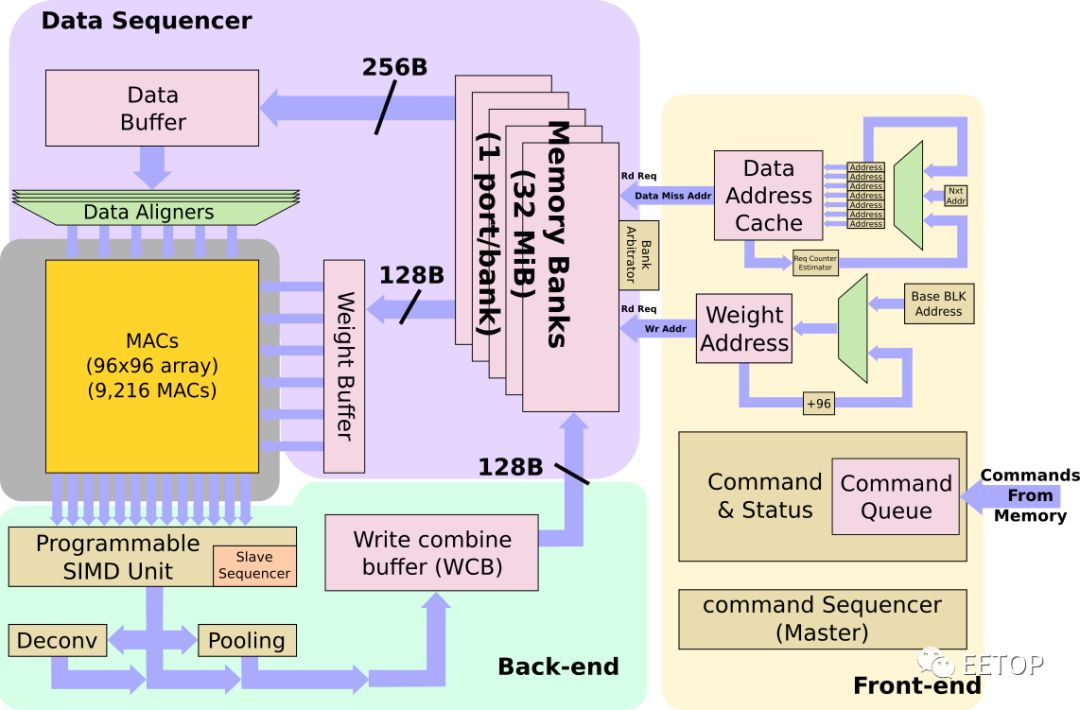
MAC阵列
CNN的主要操作当然是卷积,占特斯拉软件在NPU上执行的所有操作的98.1%,而反卷积又占1.6%。在优化MAC上花费了大量的精力。
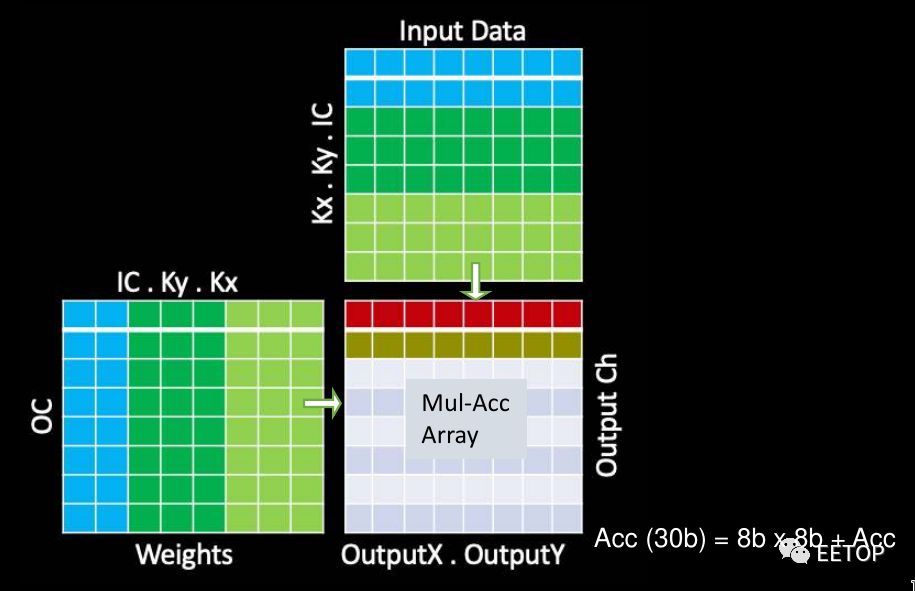
MAC阵列中的数据重用很重要,否则,即使每秒1 TB的带宽也无法满足要求。在某些设计中,为了提高性能,可以一次处理多个图像。但是,由于出于安全原因,延迟是其设计的关键属性,因此它们必须尽快处理单个图像。特斯拉在这里做了许多其他优化。NPU通过合并输出通道中X和Y维度上的输出像素,在多个输出通道上并行运行。这样一来,他们可以并行处理工作,并同时处理96个像素。换句话说,当它们作用于通道中的所有像素时,所有输入权重将被共享。此外,它们还交换输出通道和输入通道循环(请参见下图的代码段)。这使它们能够依次处理所有输出通道,共享所有输入激活,而无需进一步的数据移动。这是带宽需求的另一个很好的降低。
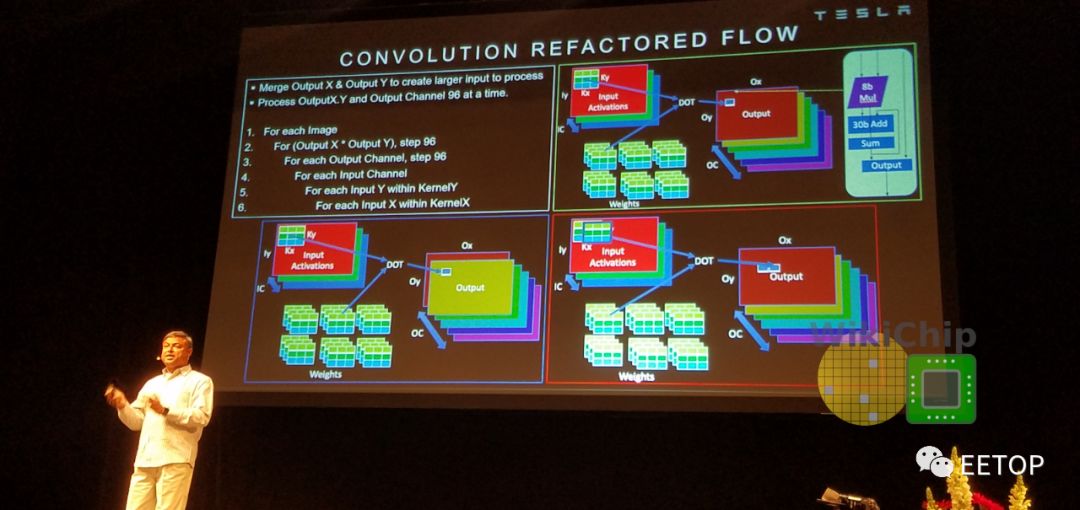
通过上述优化,可以简化MAC阵列操作。每个阵列包括9,216个MAC,并排列在96 x 96的独立单周期MAC反馈环路的单元中(请注意,这不是脉动阵列,单元间没有数据移位)。为了简化其设计并降低功耗,它们的MAC由8x8位整数乘法和32位整数加法组成。特斯拉自己的模型在发送给客户时都经过了预先量化,因此芯片只将所有数据和权重存储为8位整数。
在每个周期中,将在整个MAC阵列中广播输入数据的底行和权重的最右列。每个单元独立执行适当的乘法累加运算。在下一个循环中,将输入数据向下推一行,而将权重网格向右推一行。在整个数组中广播输入数据的最底行和权重的最右列,重复此过程。单元继续独立执行其操作。全点积卷积结束时,MAC阵列一次向下移动一行96个元素,这也是SIMD单元的吞吐量。
NPU本身实际上可以在2 GHz以上的频率上运行,尽管特斯拉根据2 GHz时钟引用了所有数字,所以大概是生产时钟。在2 GHz的频率下,每个NPU可获得36.86 teraOPS(Int8)的最高计算性能。NPU的总功耗为7.5 W,约占FSD功耗预算的21%。这使它们的性能功率效率约为4.9 TOPs / W,这是我们迄今为止在出货芯片中看到的最高功率效率之一–与英特尔最近宣布的NNP-I(Spring Hill)推理加速器配合使用。尽管特斯拉NPU在实际中的通用性有点疑问。请注意,每个芯片上有两个NPU,它们消耗的总功率预算略超过40%。
SIMD单元
从MAC阵列,将一行压入SIMD单元。SIMD单元是可编程执行单元,旨在为Tesla提供一些额外的灵活性。为此,SIMD单元为诸如sigmoid, tanh, argmax和其他各种功能提供支持。它带有自己丰富的指令集,这些指令由从机指令定序器执行。从指令定序器从前面描述的指令的扩展槽中获取操作。特斯拉表示,它支持在普通CPU中可以找到的大多数典型指令。除此之外,SIMD单元还配备了可执行归一化,缩放和饱和的点状量化单元。
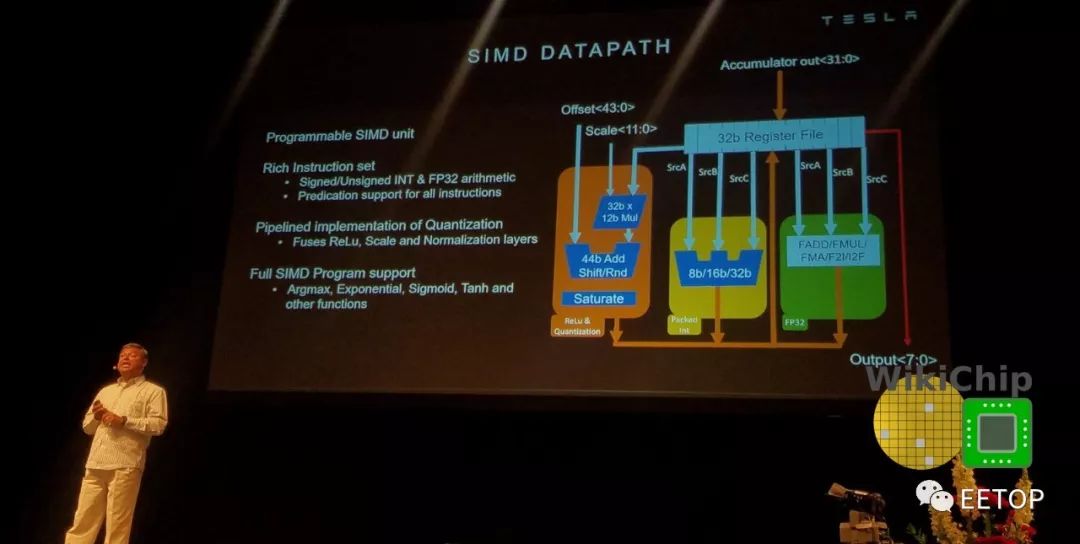

总而言之,特斯拉实现了其性能目标。FSD计算机(HW 3.0)与上一代产品(HW 2.5)相比,性能提高了21倍,而功耗仅提高了25%。

由于时间所限,翻译水平有限,如需更详细了解请查看英文原版:
https://fuse.wikichip.org/news/2707/inside-teslas-neural-processor-in-the-fsd-chip/
 扫一扫下载订阅号助手,用手机发文章
扫一扫下载订阅号助手,用手机发文章 
朋友会在“发现-看一看”看到你“在看”的内容