ACL2019 | 刘群团队,如何有效改善文本攻击?
本文由AI研习社用户刘旺旺投稿,来稿见文末联系方式。

作者 | 刘旺旺
单位 | 视源电子科技(CVTE)助理研究员(NLP方向)
编辑 | 唐里
来源:ACL2019
链接:https://arxiv.org/pdf/1906.02448.pdf
代码:
https://github.com/danishpruthi/Adversarial-Misspellings
一.动机
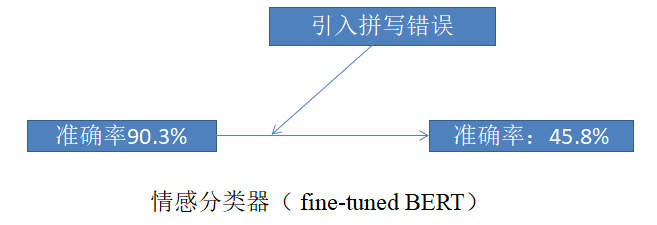
文本攻防已经成为一个研究方向。如图所示,基于fine-tuned BERT的情感分类器的准确率可以达到90.3%,但是一旦输入文本中引入拼写错误(对正确单词中的字母做一次交换,替换,插入或删除),模型的正确率下降至45.8%。
二.解决方法
在下游任务(例如情感分类)之前,引入单词识别模型,提高下游任务模型的鲁棒性。假设单词识别模型是W,下游分类任务模型是C,首先,输入样本经过单词识别器W,还原错误单词为对应的正确单词,然后,将W处理过的样本作为C的输入(其中C 与W分开训练)。

图一 处理流程
单词识别模型 ScRNN Model[1]
输入:将一个单词分为三个部分,首字母,尾字母以及中间字母,每个字母用one-hot表示。假如,句子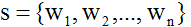 ,其中单词可以表示为三个部分的拼接(1)首字母:
,其中单词可以表示为三个部分的拼接(1)首字母: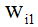 (2)尾字母:
(2)尾字母: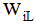 (3)中间字母求和:
(3)中间字母求和: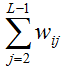
备用策略:当ScRNN Model也不能识别出单词(输出UNK时),探索了三种备用策略(1)Pass-through传递:单词识别器按原样传递单词(可能拼错了)至下游任务;(2)Neutral退到中性词: 使用类似于单词a, the等代替, 因为这样的词在不同的类别中分布相同;(3)Background使用background model: 使用更大的、较少专门化的语料库训练更通用的单词识别模型。
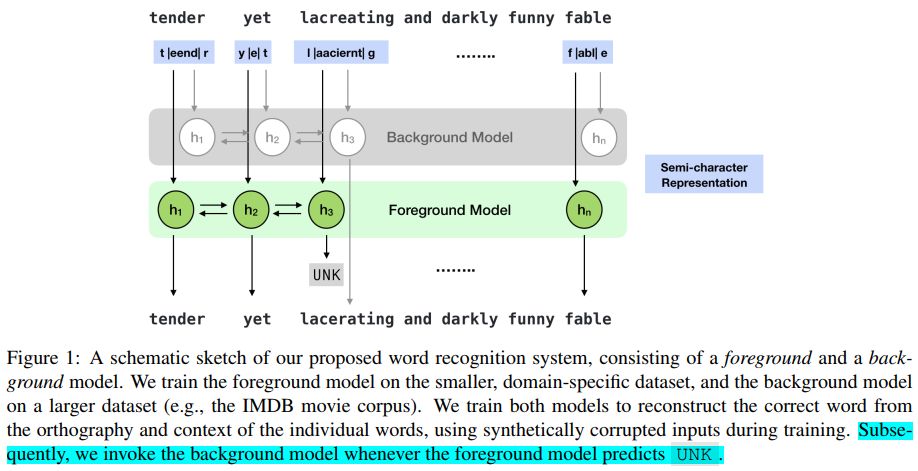
图二 第三种备用策略的示意图
下游分类模型使用BiLSTM + softmax或者fine-tuned BERT
三.实验结果
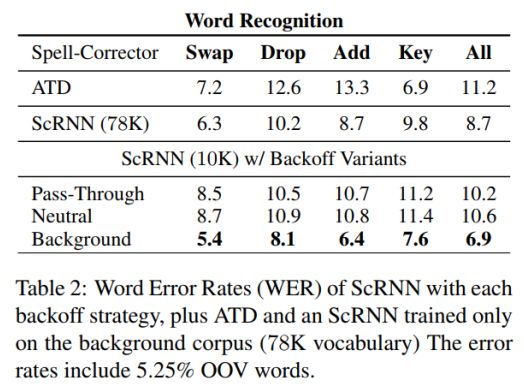
单词识别器
引入拼写错误至数据集SST,训练并测试单词识别模型改正单词的能力。引入的拼写错误类别有以下几种:
Swap:交换单词中的两个字母;
Drop:删除单词中的一个字母 ;
Add:在单词中增加一个字母;
Key: 使用键盘上相邻的字母替换原有字母;
All:以上四种类型都包括。
对每个长度大于4的单词引入错误,并且不改变单词的首字母和尾字母。单词识别器的单词错误率WER作为评价指标。ATD是一个开源的拼写纠错器。其中,使用Background备用策略的单词识别模型,单词错误率WER最低。
下游分类器
两个分类任务:sentiment analysis,paraphrase detection
两种结构:BiLSTM + softmax,Fine-tuned BERT
四种不同的输入:Word-only,Char-only,Word+Char,word-piece
实验设置如下,探索不同粒度的输入,以及不同模型,对于拼写错误输入的鲁棒性。
BiLSTM + softmax: Word-only,Char-only,Word+Char
Fine-tuned BERT: word-piece
下表中,BERT + DA 以及 BERT + Adv 是基于先前别人提出的两种处理对抗样本的的方法。(1) data augmentation (DA) 使用数据扩充的方法,将引入噪声(拼写错误)的数据作为训练集训练模型,然后再用真实的数据进行微调;(2) adversarial training (Adv) 在用真实数据训练好的模型的基础上,用对抗样本进行微调,首先随机选择对抗样本,进行预测,将预测不正确的样本继续做训练,迭代进行,直到验证集上的准确率不上升。
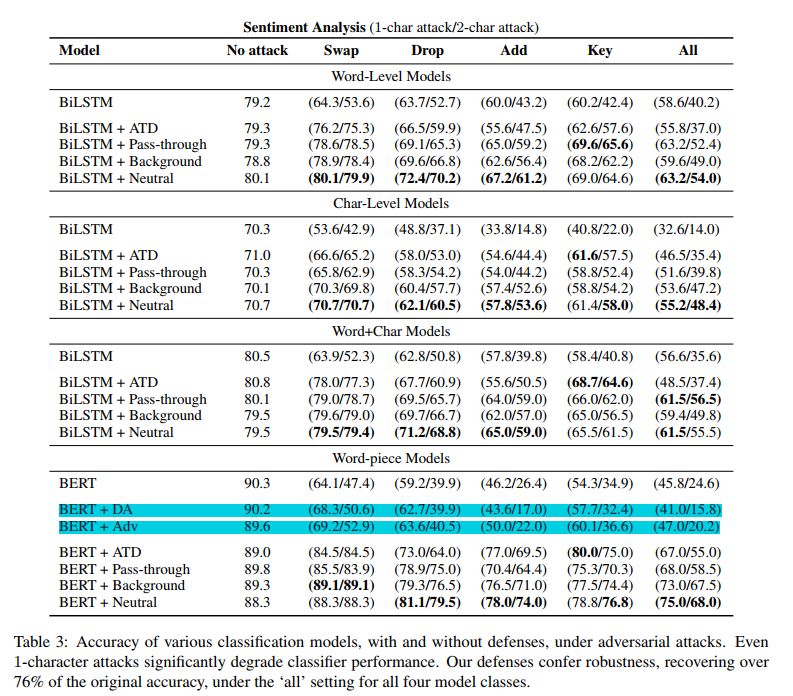
实验表明,论文提出的方法的准确率比先前的策略要高。总体来看,可得出结论:
模型鲁棒性:word-only > word+char > char-only > word-piece
(通过对比No attack列和其他列的差值,差值越小代表越不容易受攻击)
攻击能力:add > key > drop > swap (准确率下降的越多代表攻击能力越高)
并且,总体来看,单词识别的后备策略中退到中性词的结果最好,这也表明并不是WER越低,下游任务模型就越稳定。
四.结果分析
分析什么样的模型比较稳定
模型的稳定性包括两个方面:单词错误率WER 和 模型的敏感度(Sensitivity)
给定集合中的一个句子s,A(s)表示攻击类型A下的n个扰动集合,W单词识别模型,V为将字符串映射到下游分类器的输入表示形式的函数(word, char , word-piece),#u(.)输入表示与s不一致的句子个数,模型的敏感度(Sensitivity)可表示为 :
:
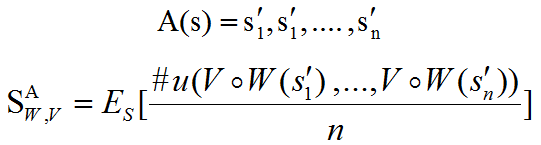
通俗点说:模型的敏感度就是原始输入句子引入拼写错误后,经过单词识别模型,再经过下游任务输入映射之后,和原来句子表示不一样的句子个数占比。
单词识别的后备策略中退到中性词的策略模型的敏感度较低,所以对下游任务有较好的效果。
五.结论及意义
更多文本攻防的论文可点击下方阅读原文访问。
[1] Keisuke Sakaguchi, Kevin Duh, Matt Post, and Benjamin Van Durme. 2017. Robsut wrod reocginiton via semi-character recurrent neural network. In Association for the Advancement of Artificial Intelligence (AAAI).
![]()
邮箱:jiawei@leiphone.com
微信:jiawei1066

张钹院士:人工智能的魅力就是它永远在路上 | CCAI 2019

更多文本攻防论文,请点击「阅读原文」
 扫一扫下载订阅号助手,用手机发文章
扫一扫下载订阅号助手,用手机发文章 
朋友会在“发现-看一看”看到你“在看”的内容