 From: IBM Research 编译: T.R
From: IBM Research 编译: T.R
近年来随着深度学习的发展,对于声音和语言风格更为有效的学习实现了更为逼真和自然的语音合成输出。然而要达到高质量的语音合成效果,大多数TTS(Text-to-Speech)系统依赖于大规模和复杂的神经网络,它们的训练过程复杂计算量大,即使在GPU的帮助下很多模型还无法做到高质量的实时语音合成。为了解决这一问题,IBM AI的研究人员基于模块化的架构结合有效的信号处理实现了高质量并具有灵活适应性的实时语音合成系统。
这一架构主要分为三个主要的神经网络,分别负责语音的不同方面,使得独立训练合成模型的每一方面成为可能。此外事先训练号的模型可以在少量样本的调优下就能得到与目标人声高度近似的说话风格,方便地适应新的语音和风格为商用和个性化使用奠定了坚实基础。
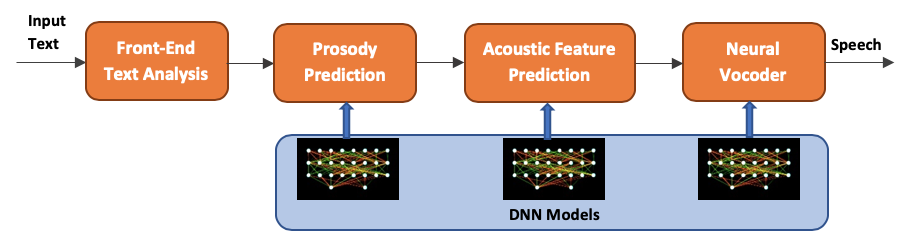
在模型的最前端是特定语言的前处理模块,将输入文字转换为语言特征序列,而后依次送入韵律预测、声学特征预测和语音编码等网络模块中进行处理。
1. 韵律预测
在每个TTS单元内韵律特征可以被标示为四维韵律向量:持续时间、初始、终止、能量(log-含义)。这些特征在训练中进行学习,所以在合成时可以通过前端处理的文本特征直接预测得到。韵律对于语音合成十分重要,它不仅关系到声音的自然和生动性,同时也是个人语言风格的直接体现。为了适应多种目标声音,模型通过变分自编码器来提供韵律自适应能力。
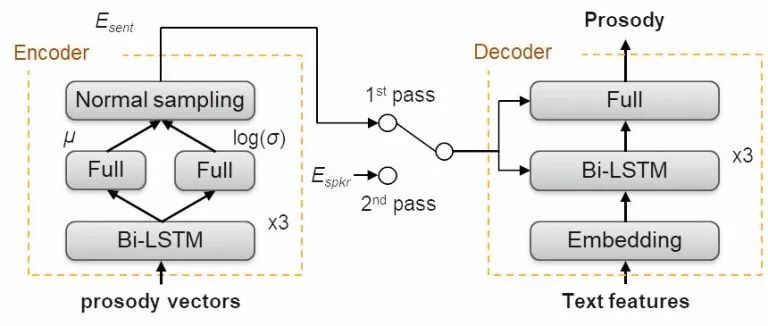
训练和微调时的韵律生成器,可以在论文中找到详细的分析
2. 声学特征预测
声学特征向量为语音提供了频谱特征表达,在针对真实音频约10ms长的帧进行处理。声学特征的表达在训练时获得,在合成语音时可以从语音标签和韵律特征中直接预测得到。
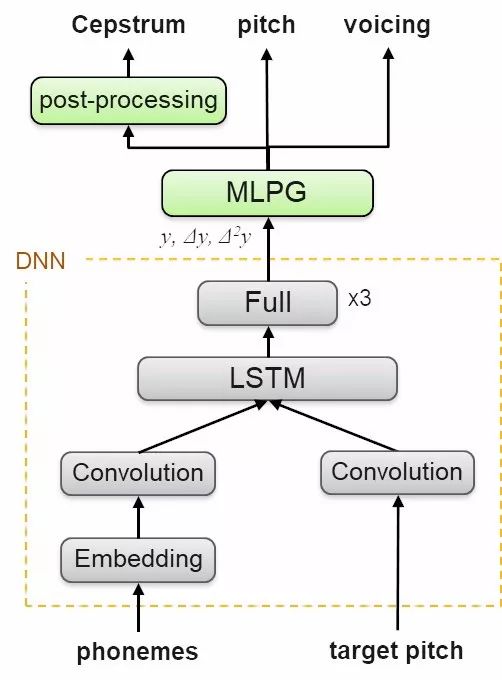
深度学习模型在训练或微调数据集上生成声音表达,这一基于卷积和循环网络的架构可以从语音序列和片段模式中抽取局部上下文信息和时间相关的模式特征。深度网络基于一阶和二阶倒数来预测神学特征,随后还利用最大似然估计和共振提升滤波器来得到更为动听的音色。
3. 神经语音合成器
神经语音合成器将用于从声学特征中合成实际的语音样本。合成器基于说话人的自然语音样本和对应特征进行训练。值得一提的是,系统中首次使用了新型的轻量级高质量神经语音合成器LPCNet,它是一种结合了RNN和线性预测的WaveRNN变种模型,将深度学习和数字信号处理技术结合起来,大幅度地提升了语音和质量和性能。它的特别之处在于不是直接预测复杂的语音信号,而是预测相对简单的声门声道残差信号,随后利用LPC滤波器转换为最终的语音输出。
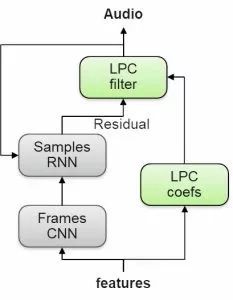
LPCNet 神经音频解码器的架构
模型性能与实验结果
在前面几个模块的通力协作下,研究人员构建了高质量的语音合成系统。除了可以合成高质量的人声外,这一系统还具有很强的适应性,利用较短的目标样本就可以训练出与目标说话人高度相似的语音结果。
针对特定目标说话人的语音适应性,可以利用小样本的目标语音对上述三个模块网络进行微调,实验显示了针对目标说话人样本尽心微调后系统输出的语音质量和相似性。下图显示了听音的测试效果,包括了男性女性时长从5分钟到20分钟的样本。
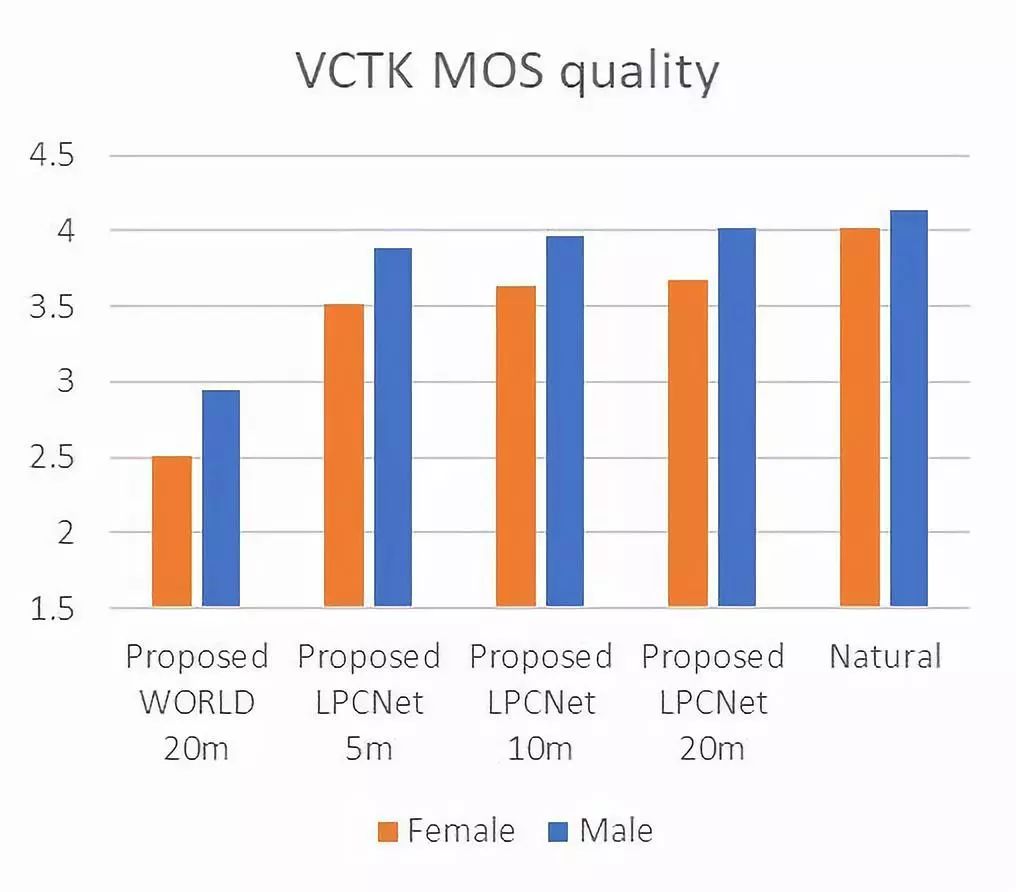
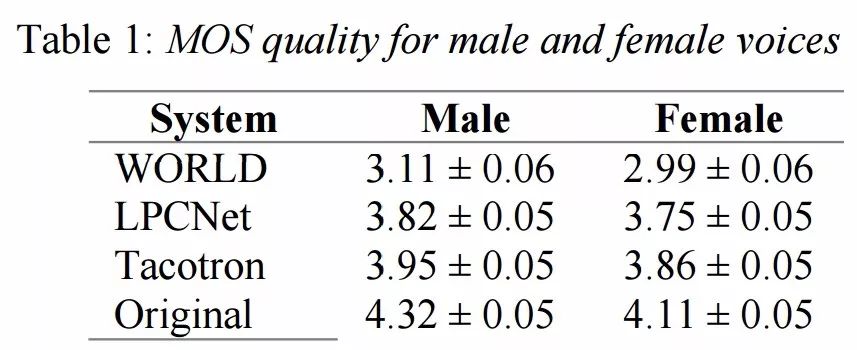
针对合成质量,使用了人工评测的平均主观意见分(MOS,1-5评级)对比合成语音与VCTK数据集中的真实语音质量。下图显示了合成语音系统在测评中水平,已经十分接近自然人声的效果。
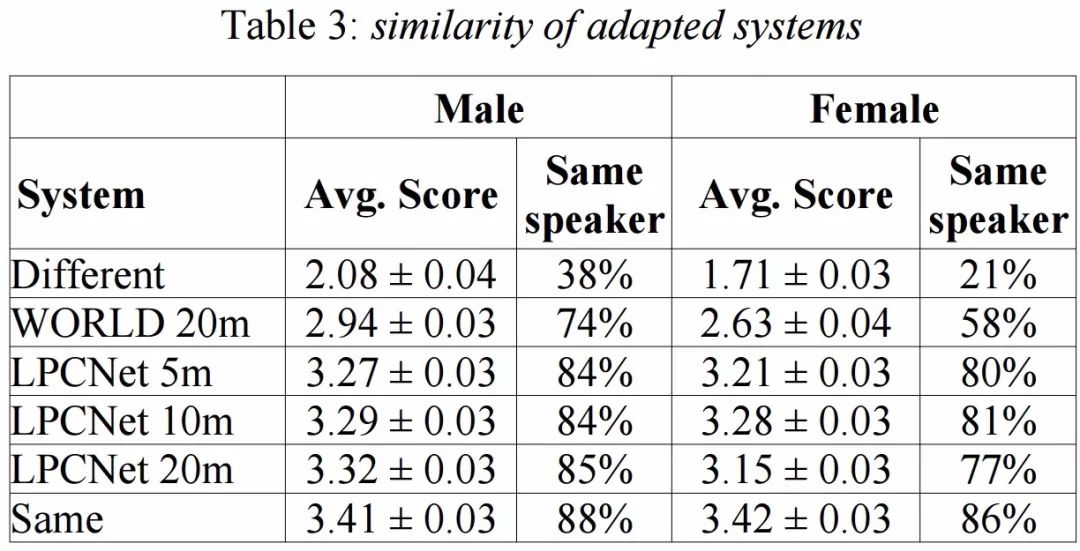
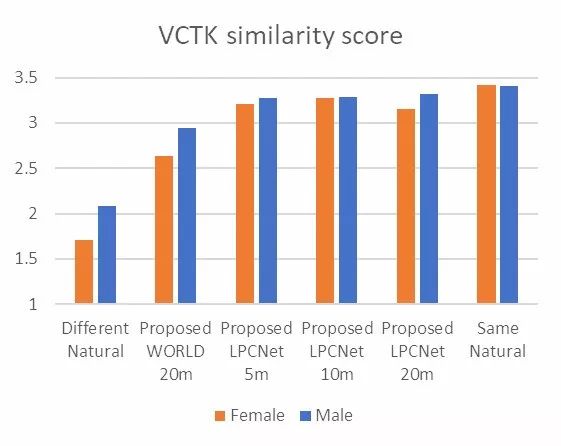
而针对相似性评测,人工测评者将为真实和对应的合成语音样本相似性进行打分(1-4)。测试结果可以看到,在相似性方面合成结果与真实结果也十分接近,值得注意的是,针对特定目标语音的训练可以在仅仅只有5min的语音样本下实现有效的训练:
如果有兴趣可以到本项目的demo网页上听一听这种新方法的语音合成效果:
http://ibm.biz/IS2019TTS 
如果想要了解更多细节,可以参考论文细节:
https://arxiv.org/pdf/1905.00590.pdfhttps://www.ibm.com/blogs/research/2019/09/tts-
DOC:https://cloud.ibm.com/docs/services/text-to-speech?topic=text-to-speech-voices
demo:http://ibm.biz/IS2019TTS
“Neural TTS Voice Conversion,” 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 2018, pp. 290-296
“LPCNET: Improving Neural Speech Synthesis through Linear Prediction,” ICASSP 2019, Brighton, United Kingdom, 2019, pp. 5891-5895
“CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit”, [sound]. University of Edinburgh. The Centre for Speech Technology Research (CSTR). https://doi.org/10.7488/ds/1994
LPCNet: DSP-Boosted Neural Speech Synthesis
https://github.com/mozilla/LPCNet
https://people.xiph.org/~jm/demo/lpcnet/
https://jmvalin.ca/papers/lpcnet_icassp2019.pdf
Sample model files: https://jmvalin.ca/misc_stuff/lpcnet_models/
https://medium.com/ibm-watson/ibm-watson-text-to-speech-neural-voices-added-to-service-e562106ff9c7
-The End-
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
将门创新服务专注于使创新的技术落地于真正的应用场景,激活和实现全新的商业价值,服务于行业领先企业和技术创新型创业公司。
将门技术社群专注于帮助技术创新型的创业公司提供来自产、学、研、创领域的核心技术专家的技术分享和学习内容,使创新成为持续的核心竞争力。
将门创投基金专注于投资通过技术创新激活商业场景,实现商业价值的初创企业,关注技术领域包括机器智能、物联网、自然人机交互、企业计算。在三年的时间里,将门创投基金已经投资了包括量化派、码隆科技、禾赛科技、宽拓科技、杉数科技、迪英加科技等数十家具有高成长潜力的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: bp@thejiangmen.com


将门创投
让创新获得认可!
微信:thejiangmen
bp@thejiangmen.com




 扫一扫下载订阅号助手,用手机发文章
扫一扫下载订阅号助手,用手机发文章 
朋友会在“发现-看一看”看到你“在看”的内容