经典解读 | CVPR TOP10 论文盘点
机器学习算法与Python学习
今天
以下文章来源于读芯术
,作者读芯术
读芯术
专注年轻人的
AI
学习与发展平台
如果你没能亲临CVPR(IEEE国际
计算机视觉
与
模式识别
会议)的现场,无需担心。
本文将列出广受关注的前十篇论文,包括深度伪造、
面部识别
、重建等话题。
1. 学习对话姿势的个人风格(Learning Individual Styles of Conversational Gesture)
全文链接:
https://www.profillic.com/paper/arxiv:1906.04160
TLDR:
在输入音频演讲后,生成与声音协调的可能的姿势,并合成相应的演讲者视频。
使用的模型/架构:
演讲到姿势的翻译模型。
一个回旋型音频
编码器
降低了二维声谱图的
取样
频率,并将其转成一维信号。
之后,翻译模型G会预测一些相应的短暂的二维姿势。
真实姿势的L1回归将提供一个训练信号,同时对抗性鉴别器D会确保预测动作既保持短暂的连贯性,也符合讲话者的风格。
模型准确度:
研究人员定性地将演讲到姿势的翻译结果与基准线和真实姿势顺序进行比较(作者在文中的表格显示较低的损失和新模型较高的PCK值)。
使用的数据集:
通过Youtube获取演讲者特有姿势的数据集。
总共有时长为144小时的视频。
研究人员将数据分类,80%用于训练,10%用于佐证,剩下的10%用于
测试
集,因此每一段视频源只在一个集合中出现。
2. 有质感的神经性化身(Textured Neural Avatars)
全文链接:
https://www.profillic.com/paper/arxiv:1905.08776
TDLR:
研究员展示了用于学习全身神经性化身的系统,如深度网络,它会生成个人全身的效果图,显现多变的身体姿势和相机位置。
这是从神经出发的人类化身的效果图,但并未重塑身体的几何结构。
使用的模型/架构:
有质感的神经性化身的综述。
输入姿势被定义为一堆“骨架”的
光栅
化(一条信道上有一根骨头)。
完全卷积的网络(发电机)会处理输入,从而生成人体部位分配的地图堆以及人体部位协调的地图堆。
这些地图堆之后会用于对人体肌理地图的
取样
,人体部位的协调堆规定了取样地点,并使用人体部位分配堆规定权值,制作RGB图像。
除此以外,最后的人体分配地图堆与背景可能性保持一致。
在学习过程中,掩码和RGB图像均需同真实情况作比较。
通过在完全卷积的网络运转中、肌理上
取样
,所得损失进行反向传播,最终更新模型。
模型准确度:
在有结构的自相似性(SSIM)方面表现优于另外两种模型,在Frechet Inception Distance(FID)方面表现比V2V突出。
使用的数据集:
· CMU全景数据集收藏的两个子集。
· 使用一套包含七个相机、横跨约30度的装备,捕捉针对三个目标的多视图序列。
-从另一篇文章及Youtube视频里得来的两个短的单目序列。
3. DSFD:
二元镜头面部检测器(DSFD: Dual Shot Face Detector)
全文链接:
https://www.profillic.com/paper/arxiv:1810.10220
TLDR:
研究员提出一项崭新的面部检测网络,其中有三项全新贡献,它们解决了面部检测的三个重要方面,包括更好的特征学习、不断发展的损失计划和以锚地分配为基础的数据扩大。
使用的模型/架构:
DSFD框架在前馈的VGG/ResNet架构顶端使用了特征加强模块,从原始特征中生产强化版特征,同时还有两个损失层,分别是服务原始特征的第一镜头
PAL
和服务受迷惑特征的第二镜头。
模型准确度:
在受欢迎的基准上的大量实验表明:
WIDER FACE和FDDB认为DSFD(二元镜头面部检测器)比最新面部检测器(如PyramidBox和SRN)更具权威性。
使用的数据集:
WIDER FACE和FDDB。
4. GANFIT:
适用于高保真3D面部重建的生成对抗网络(GANFIT: Generative Adversarial Network Fitting for High Fidelity 3D Face Reconstruction)
全文链接:
https://www.profillic.com/paper/arxiv:1902.05978
TLDR:
研究人员提议的深度适用方法能通过一张图像,使用精准的身份恢复工作,重建高质量的肌理和结构。
图中以及论文其余部分的人物重建是由大小为700浮动点的向量展现的,且在没有任何特技的情况下进行实施(模型重建了被描述的肌理,但没有任何特征是直接从图像中提取的)。
使用的模型/架构:
3D面部重建过程由可辨别型渲染器实施。
成本函数的公式编写主要通过预训练的
面部识别
网络,且成本函数被优化,方法是全程流动错误、回到有着梯度下降优化的潜藏型参数。
端到端可辨别型架构让人们可以使用价廉质优的计算机,优化第一指令衍生物,从而实现将深度网络用于发生器(如
统计学
模型)或成本函数。
模型准确度:
MICC数据集上的网状物运用点到面距离的准确度结果。
表格表明平均误差(平均值)、标准化推导(Std.)在所提出的模型中数值最低。
使用的数据集:
MoFA-
测试
、MICC、Labelled Face in the Wild(LFW)数据集和BAM数据集。
5. DeepFashion2:用于穿着图像检测、姿势估计、分类以及再识别的通用基准(DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images)
全文链接:
https://www.profillic.com/paper/arxiv:1901.07973
TLDR:
DeepFashion2为穿着图像检测、姿势估计、分类以及再识别提供了新基准。
使用的模型/架构:
R-CNN匹配由三个主要部分组成,即特征提取网络(FN)、知觉网络(PN)和匹配网络(MN)。
模型准确度:
R-CNN使用真实的边界框,准确度小于0.7,排名前二十。
这表明检索基准很有挑战性。
使用的数据集:
DeepFashion2包含491k的多样化图像,这些图像来自于广受商业购物店和消费者欢迎的13个分类。
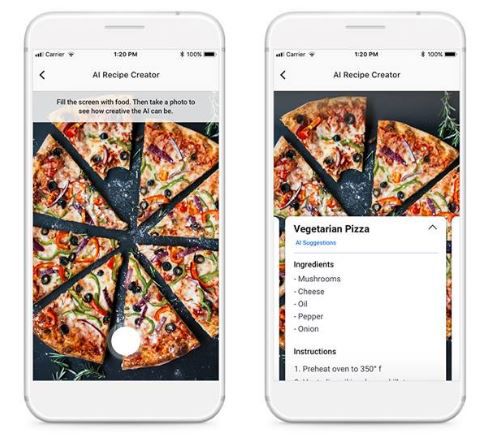
6. 逆向烹饪:
通过食物图片获得菜谱
(Inverse Cooking: Recipe Generation from Food Images)
全文链接:
https://www.profillic.com/paper/arxiv:1812.06164
TDLR:
脸书研究员用
AI
技术从食物图片提取菜谱。
使用的模型/架构:
菜谱生成模型-研究员用图片
编码器
提取图像特征。
食材
编码器
预测出食材,再通过食材编码器将食材编进成分嵌入。
通过图片嵌入、食材嵌入以及先前的预测性文字,烹饪指令
解码器
会生成菜谱标题以及一系列烹饪步骤。
模型准确度:
使用者研究结果表明该系统准确度超过最新型由图片到菜谱的检索方法(该系统优于人类基准线以及包含49.08%F1并以检索为基础的系统)(F1高分意味着低错误正数和低错误负数)。
使用的数据集:
研究员运用大规模菜谱1M数据集衡量整个体系。
7. ArcFace:
为进行深度
脸部识别
的累加有角边界损失(ArcFace: Additive Angular Margin Loss for Deep Face Recognition)
全文链接:
https://arxiv.org/pdf/1801.07698.pdf
TLDR:
ArcFace获取了更多区别性深度特征,并在百万脸庞的挑战中以可再生的方式中进行最新演示。
使用的模型/架构:
为增强同组的紧密性、加大不同组间的矛盾,研究员提议使用累加有角边界损失(ArcFace),在样品和中间插入一个测地线的距离边缘。
这样做能加强
面部识别
模型的区别能力。
模型准确度:
被报道的全面实验表明ArcFace在不断超越最新系统。
使用的数据集:
研究员们使用CASIA、VGGFace2、MS1MV2以及DeepGlint-Face(包括MS1M-DeepGlint和Asian-DeepGlint),将它们作为训练数据,与其他方法一起进行公平比较。
其他实用的数据集为LFW、 CFP-FP、AgeDB-30、CPLFW、CALFW、YTF、MegaFace、IJB-B、IJB-C、Trillion-Pairs和iQIYI-VID。
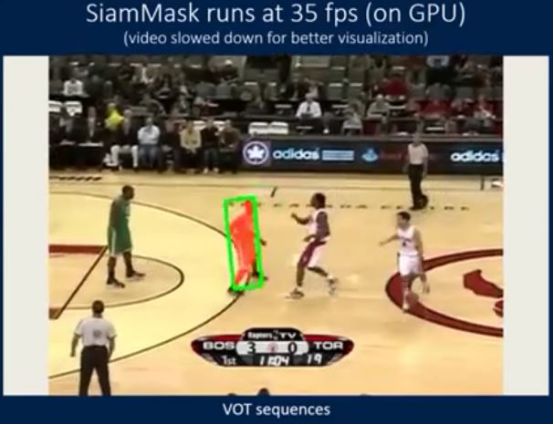
8. 统一的方法——对在线物品进行快速追踪及分类(Fast Online Object Tracking and Segmentation: A Unifying Approach)
全文链接:
https://www.profillic.com/paper/arxiv:1812.05050
TLDR:
这个方法也被戏称为SiamMask,它改善了广受欢迎的全面卷积的Siamese方法的线下训练流程,通过一个二元分类任务增大损失,追踪物品。
使用的模型/架构:
SiamMask旨在通过视觉追踪任务及视频物品分类寻找交集,从而实现可操作的最大便利。
和传统物品追踪器一样,该方法也依赖于一个简单的边界框的初始化,并在线上运转。
与最新款追踪器,如ECO不同的是,SiamMask能够生成二元分类任务,更精确地描述目标物体。
SiamMask有两个变量:
一是有三个分支的架构、二是有两个分支的架构(可通过论文获取更多细节)。
模型准确度:
SiamMask用于VOT(视觉上物品追踪)和DAVIS(密集型配注释的视频分类)序列所得的定性结果在论文中有所体现。
不仅在高速中,哪怕在干扰器中,SiamMask也能生成精确的分类掩饰。
使用的数据集:
VOT2016、VOT-2018、DAVIS-2016、DAVIS-2017和YouTube-VOS。
9. 通过行为重建转化结构,从而展现场景(Revealing Scenes by Inverting Structure from Motion Reconstructions)
全文链接:
https://www.profillic.com/paper/arxiv:1904.03303
TLDR:
微软公司的一组科学家和学者重建点云数据中某一场景的色彩图像。
使用的模型、架构:
研究员的方法基于
级联
U-Net,它的角色是输入值。
通过一个特定角度包含的点深度、视觉性色彩及SIFT描述,可得到一个2D多波段的点图像。
同时该图像会输出该特定角度下场景的色彩图像。
所用的网络有三个子网络:VISIBNET、COARSENET和REFINENET。
该网络的输入是多维度nD列。
论文还探索了网络变量,其中输入值是不同的深度色彩和SIFT描述的不同子集。
三个子网络有相似的架构,都有
编码器
和
解码器
图层的U-Nets,图层中有对称的跳跃连接。
在解码图层低端的额外图层有助于高维度输出。
模型准确度:
该论文认为,令人惊讶的高质量图像可以在数量受限的且与稀少的3D点云模型一起储存的信息中进行重建。
使用的数据集:
在700+室内和室外SfM重建结构上训练,该结构由500k+多角度图像产生,而这些图形选自NYU2和MegaDepth数据集。
10. 具有空间适应性普遍化的语义图像合成(Semantic Image Synthesis with Spatially-Adaptive Normalization)
全文链接:
https://www.profillic.com/paper/arxiv:1903.07291
TLDR:
将涂鸦转化成惊艳又逼真的风景!
NVIDIA
研究运用生成式对抗性网络创造高度逼真的场景。
艺术家使用漆刷和漆桶工具,运用水、岩石和云朵等标签
设计
风景。
使用的模型、架构:
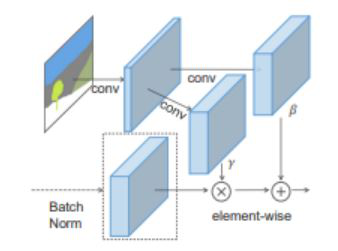
在SPADE中,掩码首先被投射到一个
嵌入式
空间,之后以卷积的形式生成调制参数γ和β。
与之前假定的标准化方法不同,γ和β并非矢量,而具有空间维度的张量。
生成的γ和β不断增多,进行元素的正常化激活。
在SPADE生成器中,每个标准化图层都使用分类掩码调整图层激活。
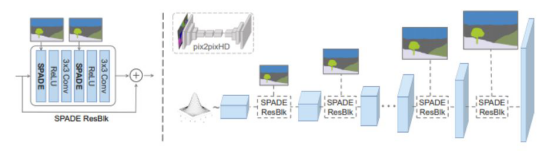
(左边)带有有SPADE的残差模块结构。(右边)生成器包括一系列SPADE有未
取样
图层的残差模块。
模型准确度:
该架构能用更少参数带来更好表现,方法在于去除主要图像到图像翻译网络的缩减
取样
图层。
所使用的方法成功地应用在多样场景中,从动物到体育活动,生成真实图像。
使用的数据集:
COCO-Stuff, ADE20K, Cityscapes, Flickr Landscape
推荐阅读
从月薪2500到年入60万,他付出的不只是努力
ICCV 2019,中国力量不容小觑,中科院、清华领跑
深度学习
大合集,马上突破10000+Stark
人人网回归了!历史记录全保留!前任们的黑历史就要被重新翻开了
Github | 准备入坑
NLP
的小伙伴注意了,复旦大学NLP入门教程
阅读
在看
已同步到看一看
写下你的想法
前往“发现”-“看一看”浏览“朋友在看”
前往看一看
看一看入口已关闭
在“设置”-“通用”-“发现页管理”打开“看一看”入口
我知道了
已发送
取消
发布到看一看
发送
最多200字,当前共
字
发送中