长文回顾 | 微软亚洲研究院主管研究员谭旭:低资源场景下的文本到语音合成

12月11日, 温哥华等你![]()

本文为将门技术社群线上直播第173期的文字内容整理 分享嘉宾:微软亚洲研究院主管研究员 谭旭 感谢整理人:Datafun 社区 Hoh Xil
基于神经网络端到端的文本到语音合成(TTS, Text to Speech)在近年来发展迅速,受到了学术界和工业界的广泛关注。然而,数据和计算资源往往制约着TTS在实际场景中的广泛应用,如何构建低资源场景下的TTS系统是一个难题。

TTS(Text to Speech)背景知识,包括TTS系统的组成以及在低资源场景下TTS面临的挑战。
低资源场景下TTS的3块工作:FastSpeech(快速语音合成系统)、LightTTS(低数据资源下的语音合成系统)、LightBERT(TTS前端的轻量级解决方案)。
最后和大家探讨下,在低资源场景下还有哪些值得被解决的问题。

语音交互:语音助手、智能音箱
阅读教育:有声读物、语言教育
语音翻译:国际会议、电话会议、旅游翻译机
泛娱乐:AI电话、AI主播、AI唱歌
Azure语音云服务,集成了语音相关的大部分解决方案,包括语音识别、语音合成、语音翻译、定制化的语音服务等;
微软的Windows、office、小冰、小娜等产品;
微软还支持数十种语言和地区的TTS服务。
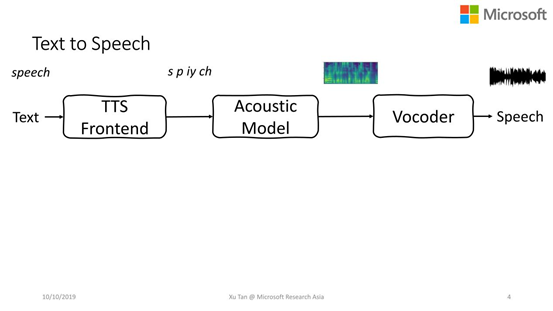
Text Normalization(文本归一化),在语音合成中常见的文字很多是简写或者缩写的,需要把这些文字标准化。如Sep.11th需要展成全写的September Eleventh,方便后面进行语言学分析,
Grapheme-to-Phoneme(字形转音形),比如speech是这个文本的字形,需要先把它转化成音素s p iy ch,也就是发音信息,方便后面的声学模型更准确的知道这个文本发什么样的音。
Polyphone Classification(多音字分类),很多语言中都有多音字的现象,比如模型和模样,这里的模字就发不同的音。所以在输入一个句子的时候,前端就需要准确判断出这个字的发音,否则后端的声学模型可能会发音不准。
Prosody Prediction(break,rising-fallingtone),还有些任务是对韵律进行预测,包括句子中词与词之间的停顿或者句子整体的升降调信息。如:革命胜利后,又经受了一次次政治风浪的考验,如果停顿信息不准确就会出现:革命胜利后,又经受了一次 次 政治风浪的考验,在一次次的地方有一个停顿,这是不该有的,会导致语音合成的信息不自然,如果再严重点可能会影响语音信息的传达。
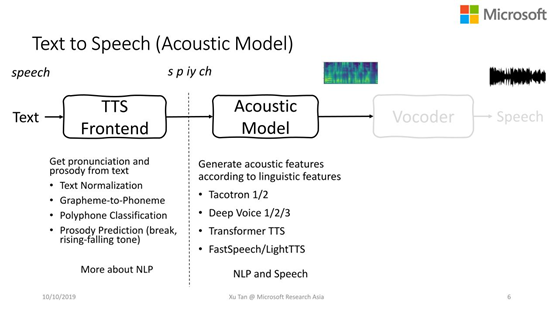
Tacotron 1/2
Deep Voice 1/2/3
Transformer TTS
FastSpeech, LightTTS(本次会重点介绍)
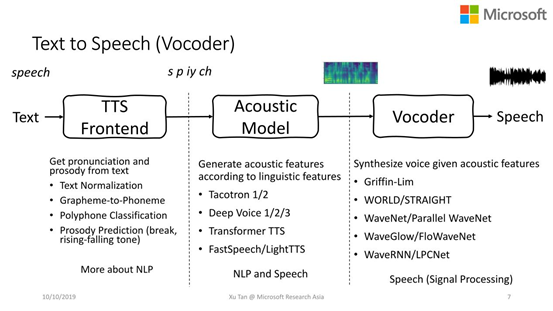
Griffin-Lim
WORLD/STRAIGHT
WaveNet/Parallel WaveNet
WaveGlow/FloWaveNet
WaveRNN/LPCNet


需要高质量的录音数据,其获取成本比一般的语音识别任务所需录音数据高。
训练声学模型需要文本和语音配对数据。
在做TTS前端模型时,需要很多相关的数据,如文本归一化所用到的规则或者模型、字形转音形的配对数据作为发音的词典或训练模型、以及多音字的数据或者语句停顿、韵律、升降调的标注信息。
离线模型训练 在线的serving和inference资源,要求能提供高速或者低延迟的TTS服务,所以计算能力必须足够强,考虑到价格成本的因素,通常线上资源比较匮乏。在有限的计算资源条件下,如何提高TTS模型在线的inference速度,是低计算资源这部分要考虑的核心问题之一。
数据资源中的文本和音频配对数据不足的问题
计算资源中在线serving和inference计算资源不足的问题,我们要提高它的inference速度。

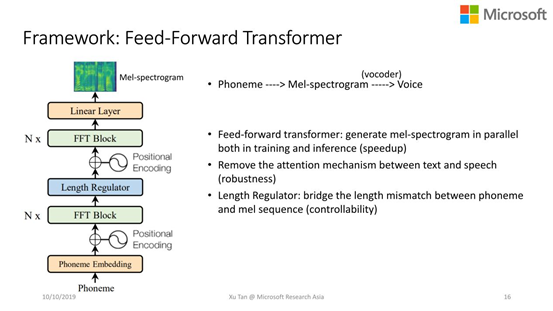
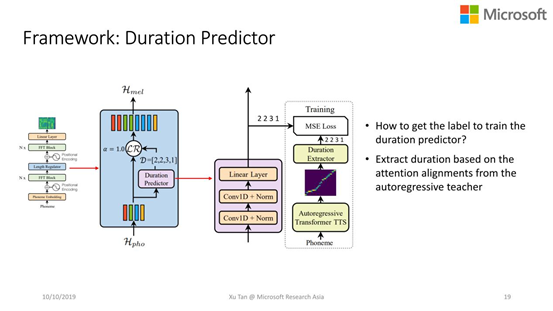
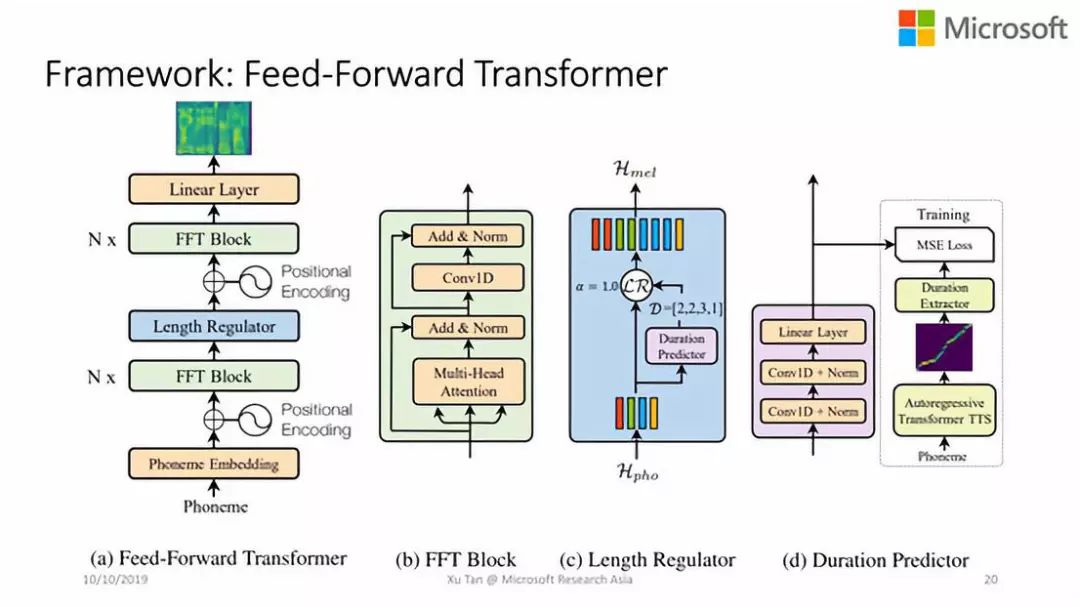
FastSpeech:这是一个快速的、轻量级的语音合成系统,能够并行的产生声学特征,所以主要是为了应对低计算资源问题。这个工作今年被NeurlPS 2019接收。
LightTTS:在低配对资源情况下,构建TTS系统,来解决低数据资源的问题。这个工作今年被ICML 2019接收。
LightBERT for TTS frontend:构建了TTS轻量级的前端模型,能够在线上做快速的inference,也是为了解决在线的低计算资源问题。

Inference 的速度很慢,如一个几秒的语音在梅尔频谱的帧数上大概几百帧,如果用自回归来生成梅尔频谱,整个生成速度会非常慢。
不鲁棒,传统的模型很多都在用encoder-attenion-decoder的结构,TTS中常遇到的就是重复字和漏字的问题,很大部分原因是由于attention机制导致的整个语音不鲁棒。
很难控制语音的速度,由于大部分模型都是自回归模型,很难控制语音合成的速度和韵律。

目前的自回归模型在在线声学特征生成时,还不能达到实时的生成速度。如1s的语音,在比较贵的GPU显卡的情况下,可能还要花费超过1s的时间来合成。
用比好的GPU显卡做在线服务成本比较昂贵。
提出的这些问题,也就是对我们的要求:
用更便宜的GPU或者CPU做服务,来节省成本。
提高语音合成速度。
合成的语音具有很强的鲁棒性和可控性。
整体的生成质量不能有损失。

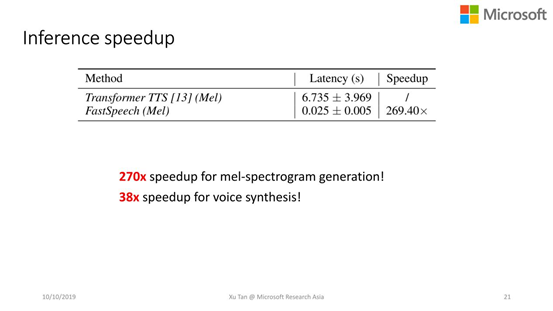
快:梅尔频谱的合成速度比自回归快270倍,同时,加上额外的vocoder来合成语音,有38倍的加速。
鲁棒性:FastSpeech几乎没有bed case,也就是没有重复字和漏字的问题,我们在大规模的测试集上验证了这个功能。
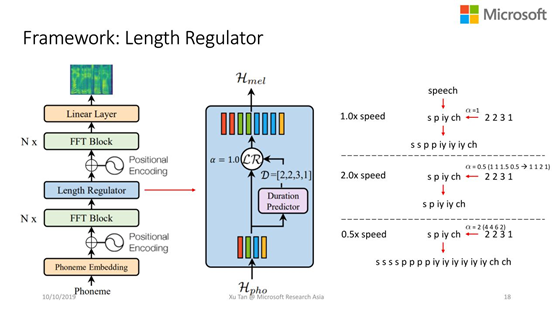
可控性:可以控制语音的速度和韵律信息。
声音质量:能达到传统的SOTA模型甚至更好。





Denoising auto-encoder(去噪自动编码器)
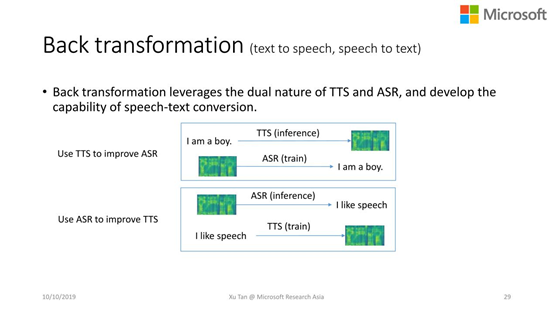
Back Transformation(和机器翻译中的反向翻译比较类似)
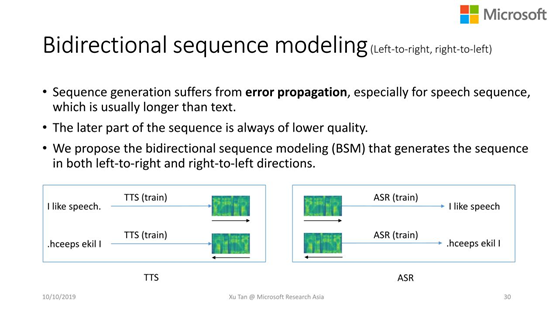
Bidirectional(双向的)sequence modeling
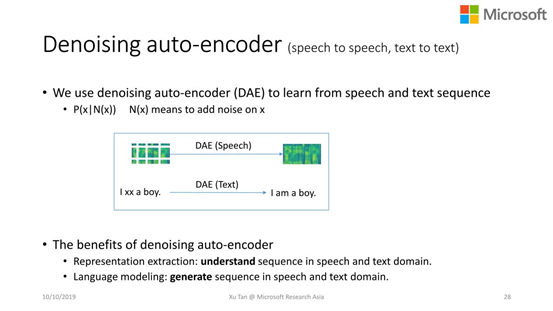
帮助模型理解语音和文本本身。
学会如何生成语音和文本。
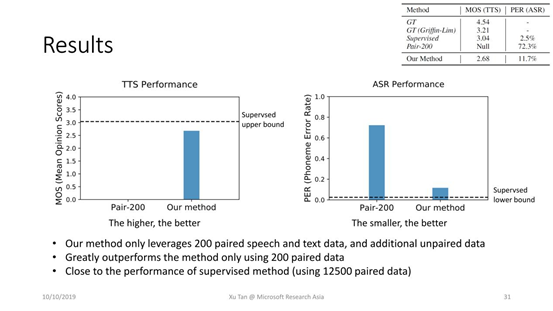
只用了200条的语音和文本数据以及无标注的语音和文本数据。
Baseline只用了200条的语音和文本配对训练处的模型。
同时,和supervised upper bound(采用12500条配对数据)做比较


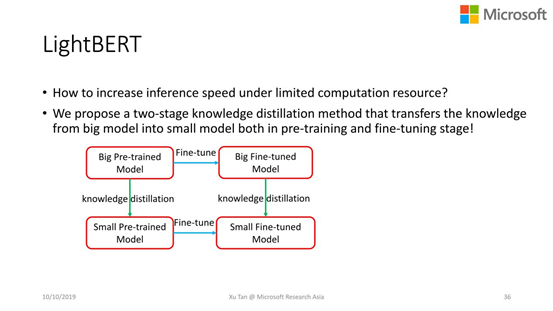
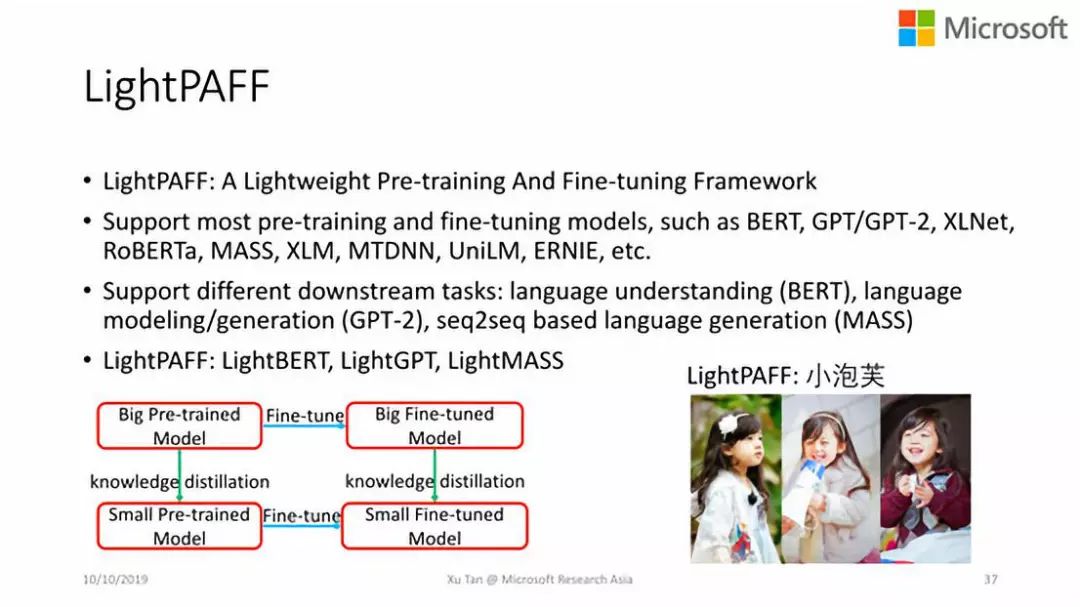
支持大部分的Pre-training和Fine-tuning模型:如BERT,GPT/GPT-2,XLNet,RoBERTa,MASS,XLM,MTDNN,UniLM,ERNIE等。 支持不同的下游任务:如自然语言理解(BERT),languagemodeling/generation(GPT-2),seq2seq语言生成任务(MASS)等。 因此,针对LightPAFF框架,我们有不同的版本:如LightBERT,LightGPT,LightMASS等。



进一步减小模型的大小,如WaveRNN。
从传统的信号处理中获取一些知识,如LPCNet。
把自回归的生成变成并行的生成,如Parallel WaveNet,WaveGlow,FloWaveNet,或者今年新提交的paper:WaveFlow和GAN-TTS等。
上述这些方案并不是既满足高的语音合成的精度,又满足线上很低的时延要求。我们是否还有一些新的思路来设计vocoder?
标签数据很贵
是否可以利用一些噪声的数据
或者multi-speaker数据来帮助TTS的训练
是否可以舍弃TTS前端模型,或者不需要那么多的资源
-The End-
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
将门创新服务专注于使创新的技术落地于真正的应用场景,激活和实现全新的商业价值,服务于行业领先企业和技术创新型创业公司。
将门技术社群专注于帮助技术创新型的创业公司提供来自产、学、研、创领域的核心技术专家的技术分享和学习内容,使创新成为持续的核心竞争力。
将门创投基金专注于投资通过技术创新激活商业场景,实现商业价值的初创企业,关注技术领域包括机器智能、物联网、自然人机交互、企业计算。在三年的时间里,将门创投基金已经投资了包括量化派、码隆科技、禾赛科技、宽拓科技、杉数科技、迪英加科技等数十家具有高成长潜力的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: bp@thejiangmen.com


将门创投
让创新获得认可!
微信:thejiangmen
bp@thejiangmen.com
点击“❀在看”,让更多朋友们看到吧~