看不懂AI芯片推理性能跑分结果?专家教你!
原创:
廖均
EDN电子技术设计
今天
继今年早些时候发表了
AI
训练的性能
测试
基准,MLPerf近期又针对
AI
推理性能公布了测试基准MLPerf v0.5以及各公司的
AI
芯片
跑分结果。
MLPerf是什么?
MLPerf基准联盟现有50多家成员,包括
谷歌
、微软、Facebook、阿里巴巴等企业,以及斯坦福、哈佛、多伦多大学等高校,由图灵奖得主大卫·帕特森(David Patterson)于2018年联合谷歌、百度、
英特尔
、
AMD
、哈佛大学与斯坦福大学成立。
MLPerf基准是业内首套衡量
机器学习
软硬件性能的通用基准,即训练过的
神经网络
在不同量级的
设备
(
物联网
、智能手机、PC、服务器)、各种应用(
自动驾驶
、
NLP
、
计算机视觉
)上处理新数据的速度。
MLPerf是
测试
推理性能的通用方法,它最终将成为衡量从
低功耗
SoC
中的
NPU
到数据中心高性能加速器的标准。
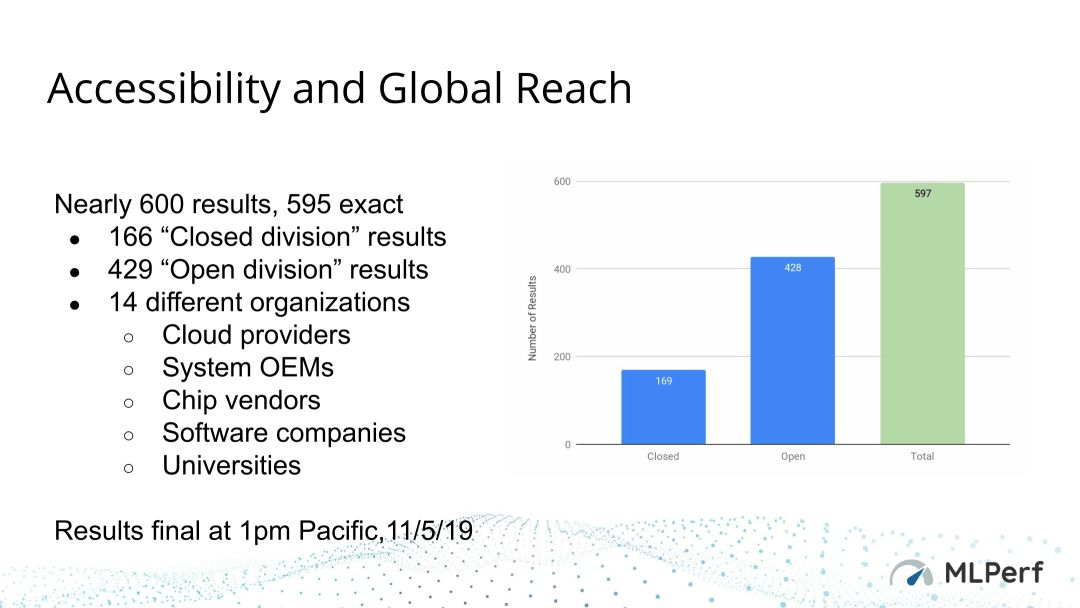
本次
AI
芯片
的推理
测试
对来自19家公司机构的594种芯片在各种自然语言和
计算机视觉
任务中的表现进行了审核,其中5家公司的63个“参赛者”提供了跑分结果,参与推理性能
测试
基准跑分并提供成绩的公司数量更多,共有14家公司的500组成绩,来自中国、以色列、韩国、英国和美国的公司纷纷提交了测试结果,这些公司包括:
阿里巴巴、
戴尔
EMC
、
谷歌
、浪潮、
英特尔
、
英伟达
、米兰理工大学、
高通
和腾讯等等。
MLPerf v0.5
AI
芯片
推理
测试
的部分结果如下面的两个表所示。
完整的跑分结果请点击
阅读原文。
专家解读MLPerf跑分结果
MLPerf v0.5推理基准
测试
设有五个基准(目前还没有功耗测试指标),当前套件的桌面/服务器版本涵盖了图像分类(ResNet50),对象检测(ResNet34)和机器翻译任务(GNMT)。
所有基准
测试
都提供了四种方案:
单路((Single Stream,一个终端运行一个任务),多路(Multi-Stream一个终端同时运行多个任务),服务器(服务器的实时性能)和离线(不在线的服务器)。
测试
者可以选择提交任何基准及相应场景的结果。
不过,很多读者看了MLPerf跑分结果后表示一头雾水,因为有些系统看来相似但是分数却大不相同,而且也搞不清楚数字高低究竟代表什么……
EE Times欧洲特派记者Sally Ward-Foxton为此特地请教了以色列
AI芯片
新创公司Habana Labs的研究科学家Itay Hubara,他非常耐心地为大家解释了MLPerf v0.5表格中不同的分类(category)、分区(division)、模型(
model
)以及场景 (scenario)所代表的意义。
分类
其中“现货”意味着该系统目前在市场上已经买得到,其
软件
堆栈必须已经完全准备就绪,而且提供跑分结果的公司得让社区能重现其结果。
这意味着不在该公司SDK中的所有代码必须要上传到MLPerf的Github平台。
在“预览”分类中的系统,意味着提交分数的公司需要让该产品在MLPerf下一次(预计是明年夏天)公布
AI芯片
推理性能分数时上市,而在这个分类中的公司不需要提供所有的
软件
。
此外还有“研发与其他”分类,这意味着此分类中的系统仍在原型阶段,还没有量产计划,提交分数的单位也不需要分享任何
软件
。
分区
MLPerf提供了两个
测试
“分区”:
封闭分区(Closed Division)和开放分区(Open Division)。
封闭分区是“
苹果
对苹果(apples-to-apples)”
测试
,是让各系统能够直接比较,参与的公司必须遵守严格的规范,芯片将获得预先训练的网络和预先训练的权重。
在选择要使用的精度等级时,芯片公司在量化方面仍具有一定的灵活性,但是在封闭的分区,他们的解决方案仍必须达到
数学
上的等效性,并且禁止重新训练网络。
相比之下,开放分区显然更加开放。
芯片公司被允许重新训练网络以及进行更广泛的量化工作。
绝对不是封闭
测试
区那样
苹果
对苹果,开放分区本质上是一种结构较少的结构化格式,可以让芯片公司以最佳的方式展示其解决方案和团队的独创性。
Hubara将开放分区形容为“牛仔世界”,参与者不需要遵循什么规则,不过必须透露它们做了哪些变更,诸如重新训练了模型,或者是进行了微调。
参与开放分区的公司通过让自家的
算法
工程师大显身手来展现优势,例如,Habana Labs在开放分区中的分数,其延迟性降低到只有封闭分区中的四分之一,充分发挥了Goya芯片的性能。
不过基于封闭与开放分区的本质,并不适合将封闭分区与开放分区中的分数拿来比较,甚至将开放分区中的分数互相比较也不合适。
模型
MobileNet-v1与ResNet-50 v1.5都是以ImageNet数据集进行推理的图像分类模型,MobileNet是手机用的轻量化网络,ResNet-50相较之下属于较重量级、适合较大的加速器使用。
MobileNet-v1与ResNet-34的
SSD
算法
都是用来进行物体检测,SSD的全名为单次多框检测器(Single Shot MultiBox Detector),是一种用来检测一幅图像中的单个物体以便进行分类的算法,必须搭配MobileNet或ResNet等分类算法使用。
MobileNet是较轻量化的模型,适用于较低分辨率的图像(300 x 300或0.09 Mpix);
ResNet-34模型则能支持较高分辨率的图像(1,200 x 1,200或1.44 Mpix)。
这些模型都是使用COCO (Common Objects in Context)数据集进行推理。
GNMT则是唯一并非以卷积
神经网络
或是图像处理为基础的
测试
基准,它是用于语言翻译(在这里的案例是德文翻英文)的递归神经网络。
场景
总共有4种不同的场景,两种是边缘的推理,另外两种是数据中心的推理。
其中单路只是测量推理一幅图像——样本总数为1——所需时间,单位是毫秒。
在这个项目中,分数越低越好,而这种场景可能是对应于一次执行单一图像推理的手机。
多路则是测量某系统一次能处理多少图像数据流(样本总数大于1),依据不同模型,延迟在50~100毫秒之间。
这时分数越高越好。
表现优良的系统最后可能是出现在配备很多个对着不同方向的摄像头的
自动驾驶
车辆,或者是监控摄像系统。
在服务器场景中,多个使用者会随机发送请求给系统,测量指标是该系统能在特定的延迟时间内支持多少请求;
这里的数据流不像是多路场景那样持续,难度会更高,因为样本数可能是动态的。
数字越高代表成绩越好。
离线场景可能是对一本相册中的图像进行批处理,其中的数据能以任何顺序进行处理。
这个场景没有延迟的限制,以每秒多少图像为单位描述其处理量,数字越高代表成绩越好。
加速器数量
这个测量基准比较的是系统而非芯片。
有些系统可能有一个主芯片和一个加速器芯片,而最大规模的系统拥有128颗
Google
的张量处理单元(
TPU
)加速器芯片。
这里的分数并未针对每个加速器正规化,因为主芯片也扮演重要角色,它们与加速器的数量大致呈线性关系。
为何有些分数是空白的?
MLPerf并未要求参与者提供每一种场景或模型的
测试
结果,用于终端平台的元件可能只会选择提交单路与多路场景的分数。
数据中心平台就可能会选择只提供服务器与离线场景的
测试
分数。
而显然每一家公司都选择提交它们认为最能表现其系统优点的分数。
还有另一个可能的因素是,Hubara举例说,Habana的分数栏空白,是因为该公司来不及在这一次成绩公布的截止收件时间内提交
测试
分数。
此外在GNMT翻译模型项目提交分数的公司也比较少,因为这个模型现在被广泛认为已经过时,很多公司更愿意花时间布署较新的
算法
,例如BERT。
其他考虑因素
而整体说来,MLPerf的分数是测量纯性能,要为某个实际应用选择一套系统当然还需要考量许多其他因素。
例如在这一系列成绩单中,并没有关于功耗的测量 (据说在下一个版本的
测试
基准中会包含)。
成本也是一个未包括的指标。
如果一套系统只有一颗加速器芯片,而另外一套有128颗加速器芯片,显然两者在价格上一定会不同。
MLPerf的表格也列出了每一套系统使用的主处理器,这可能会带来额外的成本,而且也可能会需要昂贵的
水冷
系统。
至于系统主机的外观——例如移动/手持式、桌面/工作站、服务器、边缘/
嵌入式
则是由系统制造商自行提供的指标,并非每一个分类中严格限制的基准参数。
在MLPerf表格右侧,点击每一个系统的“细节”(details)链接,则能看到该系统更详细的软硬件规格,值得参考。
在其详细规格中的某些部份是必填信息,有些不是,但从中可以得知
散热
等系统要求。
平头哥“含光800”全球夺冠
阿里巴巴旗下平头哥的
AI芯片
“含光800”是中国公司首次提交到MLPerf的原创
AI
芯片,参加了适用于图像分类任务的Resnet50 v1.5基准
测试
,在离线模式、服务器模式、多路模式和单路模式四个场景测试项目上,都稳拿“全球第一”的成绩。
离线模式:
“含光800”超
谷歌
和
英伟达
在芯片
测试
中,离线模式测试的目的是评估芯片推理的最大吞吐量。
这项
测试
可以考验芯片的计算、存储、通信等
设计
所能达到的最佳性能。
在该项
测试
中,“含光800”芯片的成绩是69306.60 image/sec,位居全球第一,排名第二的
Google
TPU
V3.8的成绩是32716.00,排名第三的则是
英伟达
RTX,成绩是16562.6。
“含光800”的成绩是
谷歌
TPU
v3 的8.5倍、
英伟达
T4的12倍。
服务器模式:
是第二名
Google
TPU
v3的2.82倍
服务器模式主要用来测评芯片系统单张图片的吞吐量,“含光800”的成绩是45169.48 image/sec,是第二名
Google
TPU
v3.8的2.82倍。
多路模式:
是第二名Habana Goya的3.84倍
多路模式是评估芯片系统所能支撑的视频流的最大路数。
这里的视频流定义为20帧/sec,主要应用于视频、监控、智慧城市等。
在多路模式
测试
中,“含光800”最大可同时处理2692路视频流,是第二名Habana Goya的3.84倍。
单路模式:
比第二名Habana的Goya快1.41倍
单路模式
测试
是用于评估芯片系统的单张图像请求吞吐量。
它强调单图像的推理场景下,芯片的最小反应延迟,反应越快越“聪明”,数值越小越优秀。
在这项
测试
中,“含光800”的成绩是0.17毫秒,比第二名Habana的Goya快1.41倍。
2019年9月问世的“含光800”是阿里巴巴第一款正式流片的芯片,基于
台积电
12nm
工艺
生产,采用平头哥自研架构,现已大规模应用于阿里巴巴集团内多个场景,如视频图像识别/分类/搜索、城市大脑等,未来还可应用于医疗影像、
自动驾驶
等领域。
英伟达
也获多项第一
MLPerf实际上收到了除神经形态和模拟系统以外每种类型的处理器,其中包括
英伟达
的
GPU
、
谷歌
的
TPU
、
英特尔
的
CPU
和加速器以及Habana Labs的Goya加速器、Raspberry Pi 4和阿里巴巴的“含光800”加速器。
几乎每个芯片公司都可以在某个分类中取得胜利。
在离线
测试
中,
Google
展示了从1 TPUv3到32的几乎完美的拓展性,
英伟达
的Tesla加速器在一些
测试
中名列前茅,
英特尔
在
CPU
中位居榜首,
高通
的
骁龙
855在官方结果中也远远超过其它
SoC
。
英伟达
公布的图表诠释了
测试
结果。
从数据中心推理的
测试
结果来看,
英伟达
在包括服务器与脱机项目中的所有5个
测试
中都排名第一。
在数据中心分类中与
英伟达
成绩最接近的对手是以色列新创公司
Habana Labs
的Goya推理芯片。
Habana Labs
在接受EE Times采访时指出,该
测试
成绩完全以性能为基础,功耗并不是一个测量标准,实用性与成本也不是。
下图为配备Goya推理芯片的
Habana Labs
PCIe
卡。
在边缘推理
测试
中,
英伟达
则在商用方案封闭分区的所有4个项目中胜出。
Qualcomm
的
Snapdragon
855
SoC
以及
Intel
的Xeon
CPU
在单路场景中紧随
英伟达
,不过
Qualcomm
与
Intel
都没有提交较困难的多路场景
测试
结果。
结语
自去年初成立以来, MLPerf联盟一直在稳步建立
机器学习
基准。
今年6月,MLPerf联盟发布了第2个基准
测试
集MLPerf Inference v0.5,目前该版本还不太完善,也没有功耗测试指标,但仍然吸引了主要芯片公司的关注。
MLPerf联盟表示未来几年将开发移动应用程序以加快对智能手机和其他智能
设备
的
测试
,同时桌面基准测试也将日趋成熟,推理芯片数十亿美元的市场将继续快速增长。
阅读原文
阅读
在看
已同步到看一看
写下你的想法
前往“发现”-“看一看”浏览“朋友在看”
前往看一看
看一看入口已关闭
在“设置”-“通用”-“发现页管理”打开“看一看”入口
我知道了
已发送
取消
发布到看一看
发送
最多200字,当前共
字
发送中