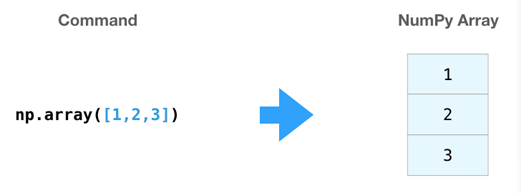
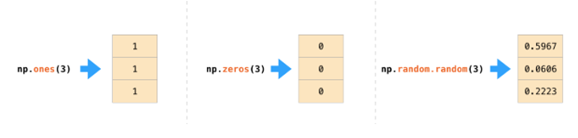
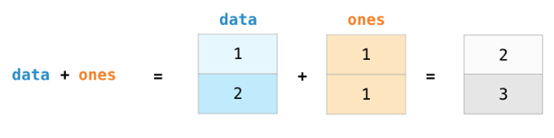
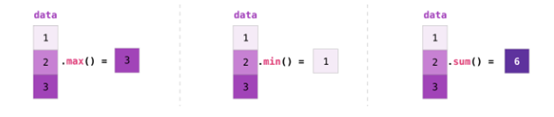
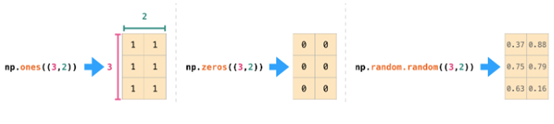
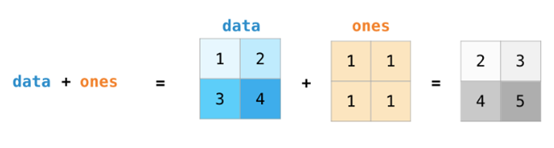
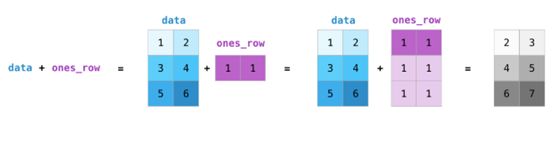
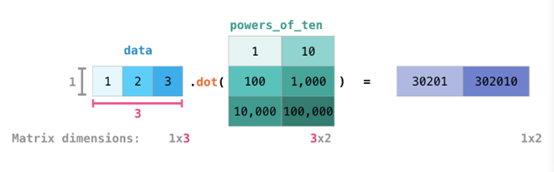
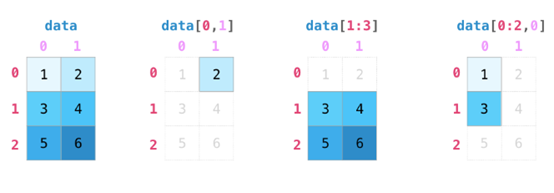
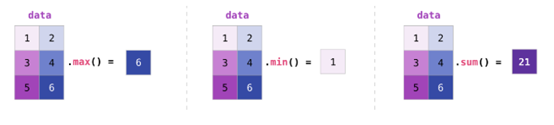
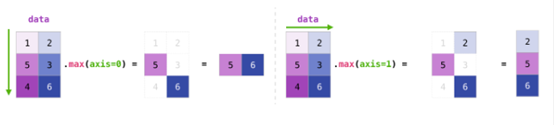
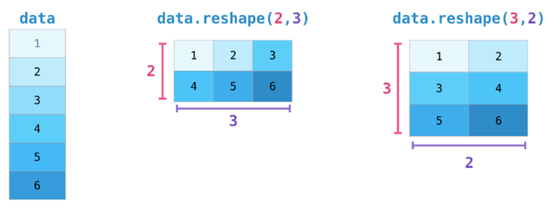
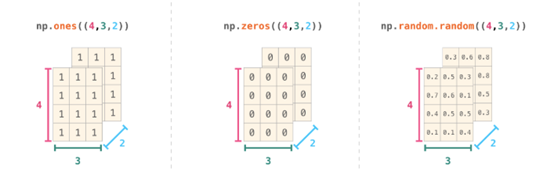
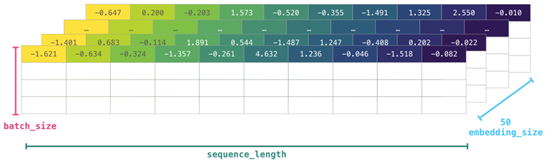
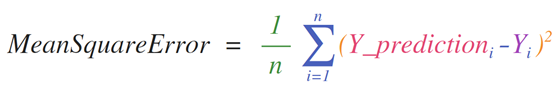如果图像为彩色的,那么每个像素都用三个数字表示——各有红、绿、蓝三色的值。在这种情况下就需要第三个维度了(因为每一格只能包含一个数字)。因此,一幅彩色图像要用维度的多维数组表示(高x宽x3)。语言如果要处理文本,情况会困难一些。用数字表示文本要求建立词汇表(模型已知的所有独有单词列表)这一步和嵌入步骤。一起来看看用数字表示这一句(翻译过来的)古话吧:“Have the bards who preceded me left any themeunsung?”在用数字表示这名尚武诗人略显焦虑的词汇之前,需要让模型观看大量文本。可以将一小个数据集提供给模型,并用这个来建立(含71290个单词的)词汇表: