一窥Habana的推理和训练神经处理器

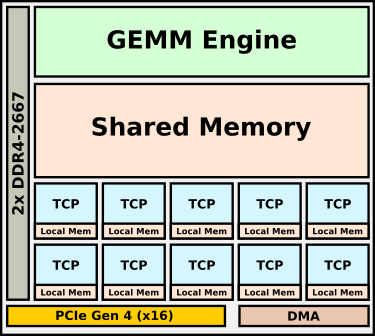
Goya

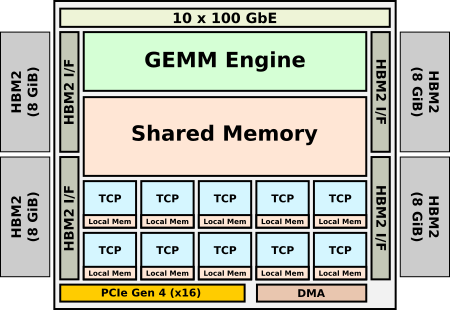
Gaudi



*点击文末阅读原文,可阅读英文原文。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2160期内容,欢迎关注。
推荐阅读
半导体行业观察

『半导体第一垂直媒体』
实时 专业 原创 深度
识别二维码,回复下方关键词,阅读更多
晶圆|AI|台积电|封测|亚马逊|RISC-V|思科|存储
回复 投稿,看《如何成为“半导体行业观察”的一员 》
回复 搜索,还能轻松找到其他你感兴趣的文章!