深度学习里的“学习”是怎么做到的?
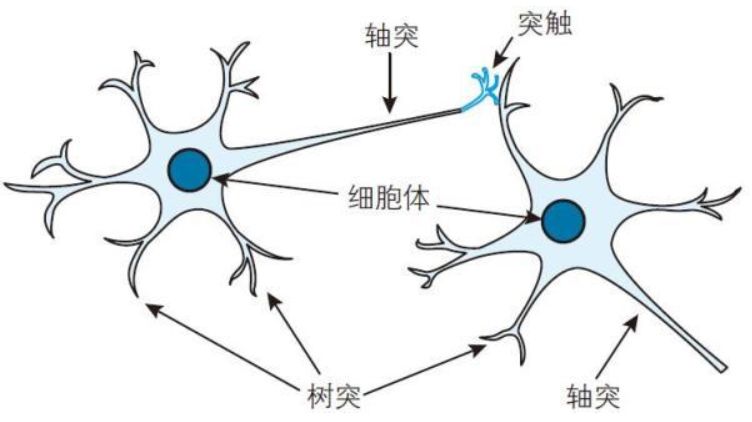
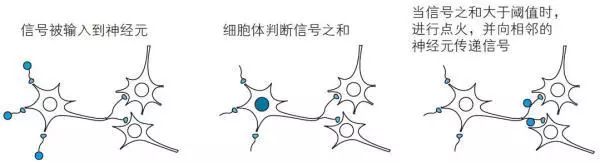
神经元主要由细胞体、轴突、树突等构成。树突是从其他神经元接收信号的突起。轴突是向其他神经元发送信号的突起。由树突接收的电信号在细胞体中进行处理之后,通过作为输出装置的轴突,被输送到其他神经元。另外,神经元是借助突触结合而形成网络的。
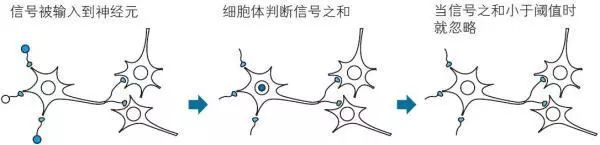
注:对于生命来说,神经元忽略微小的输入信号,这是十分重要的。反之,如果神经元对于任何微小的信号都变得兴奋,神经系统就将“情绪不稳定”。
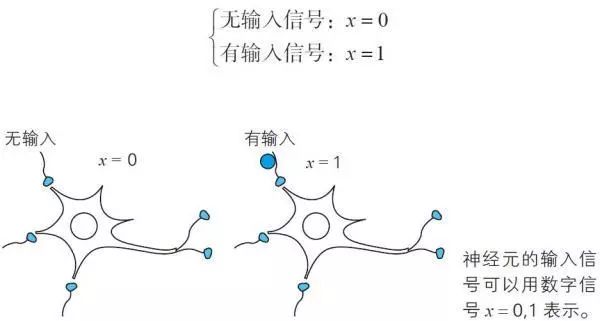
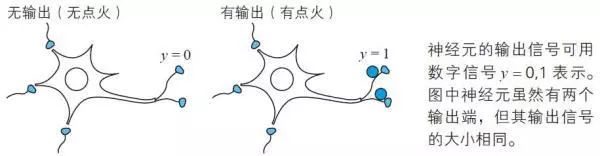
注:与视细胞直接连接的神经元等个别神经元并不一定如此,因为视细胞的输入是模拟信号。

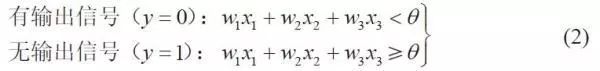
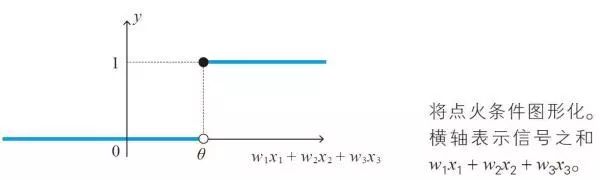
单位阶跃函数又称单位布阶函数,目前有三种定义,它们共同之处是自变量取值大于0时,函数值为1;自变量取值小于0时,函数值为0,不同之处是,自变量为0时函数值各不相同。
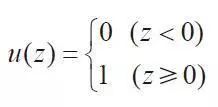
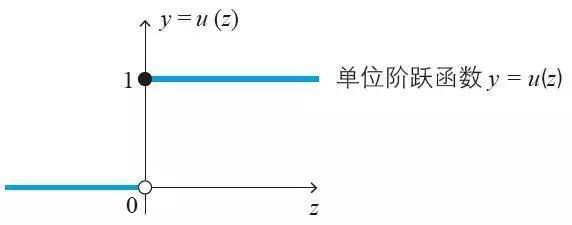
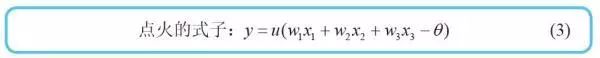

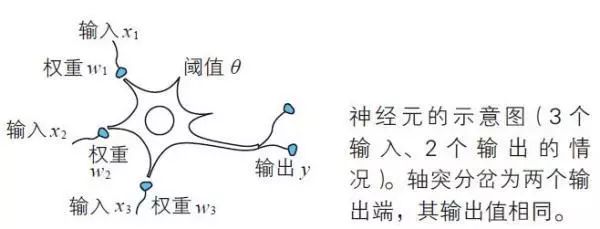
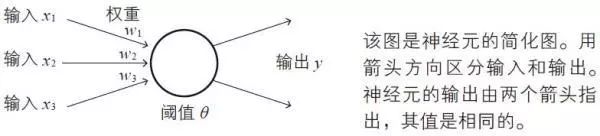

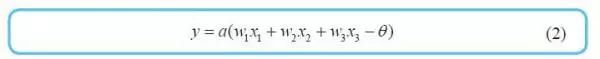
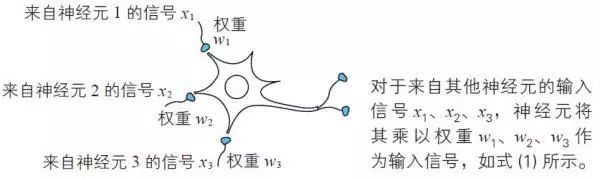
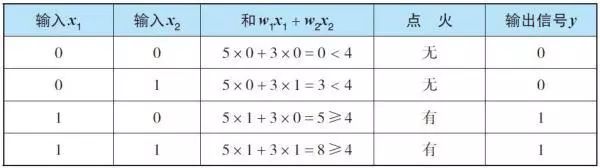
注:虽然式(2) 只考虑了3 个输入,但这是很容易推广的。另外,式(1) 使用的单位阶跃函数u(z) 在数学上也是激活函数的一种。

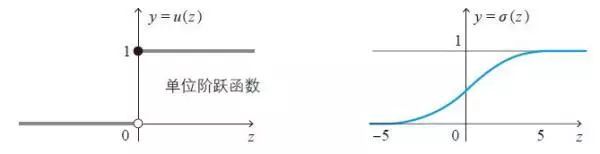
右图是激活函数的代表性例子Sigmoid 函数σ(z) 的图形。除了原点附近的部分,其余部分与单位阶跃函数(左图)相似。Sigmoid 函数具有处处可导的性质,很容易处理。
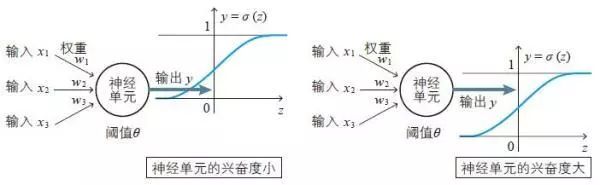
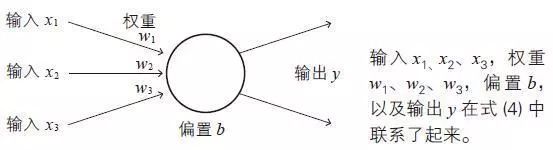



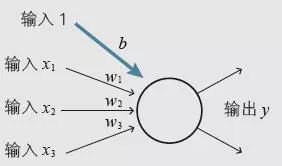
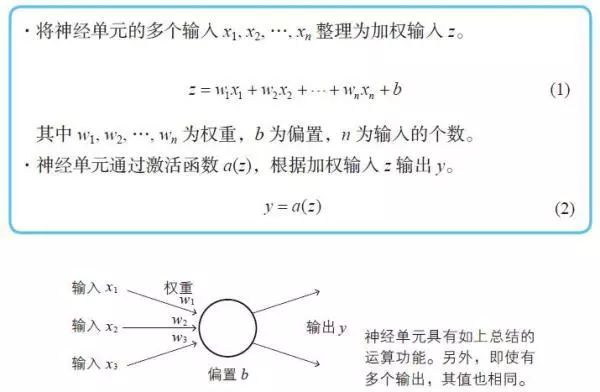
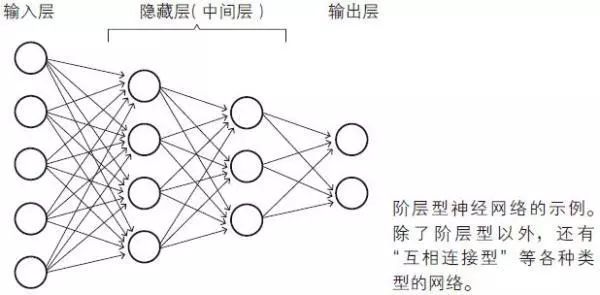
输入层负责读取给予神经网络的信息。属于这个层的神经单元没有输入箭头,它们是简单的神经单元,只是将从数据得到的值原样输出。
隐藏层的神经单元执行前面所复习过的处理操作(1) 和(2)。在神经网络中,这是实际处理信息的部分。
输出层与隐藏层一样执行信息处理操作(1) 和(2),并显示神经网络计算出的结果,也就是整个神经网络的输出。
了解卷积神经网络可以阅读《卷积神经网络的Python实现》这本书。 关于神经网络的详细介绍,请看《这是我看过,最好懂的神经网络》这篇文章。
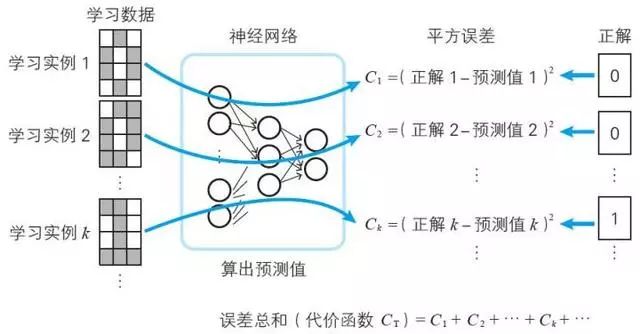
注:学习数据也称为训练数据。