AMD真能翻身,压倒Intel?

来源:内容来自「台湾水电工协会-非在职工友」,谢谢。
当「挤牙膏」对决「大跃进」
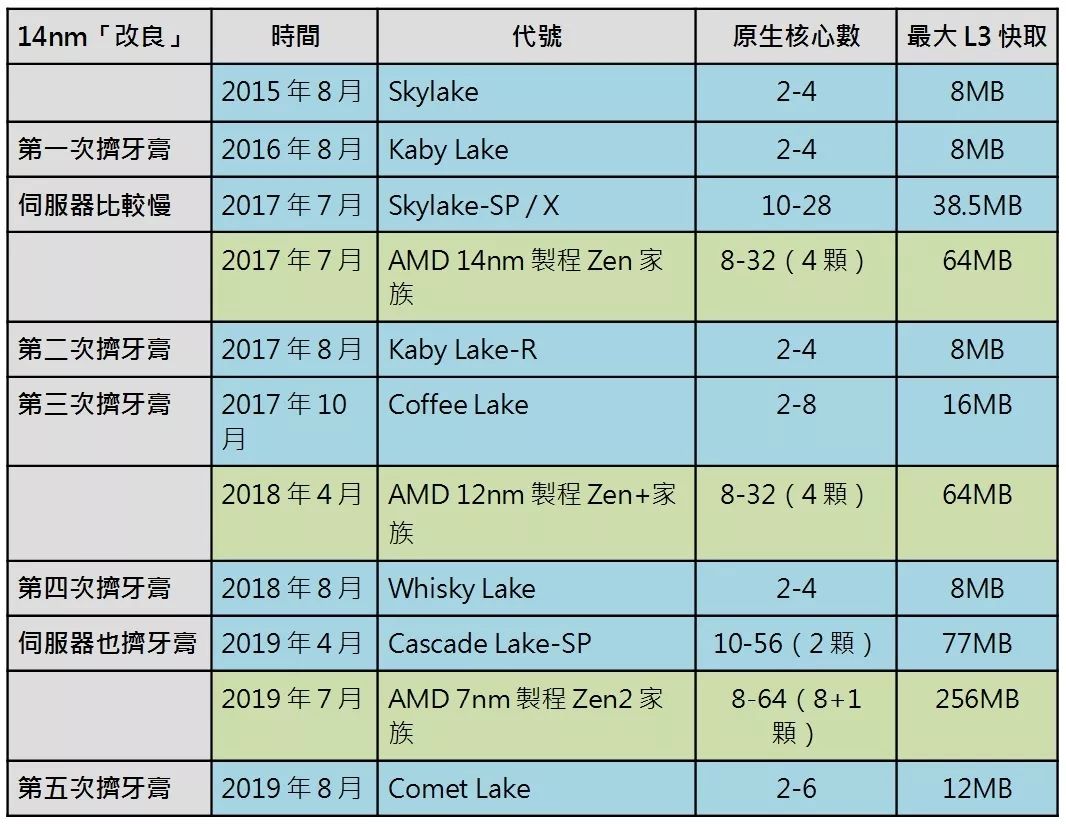

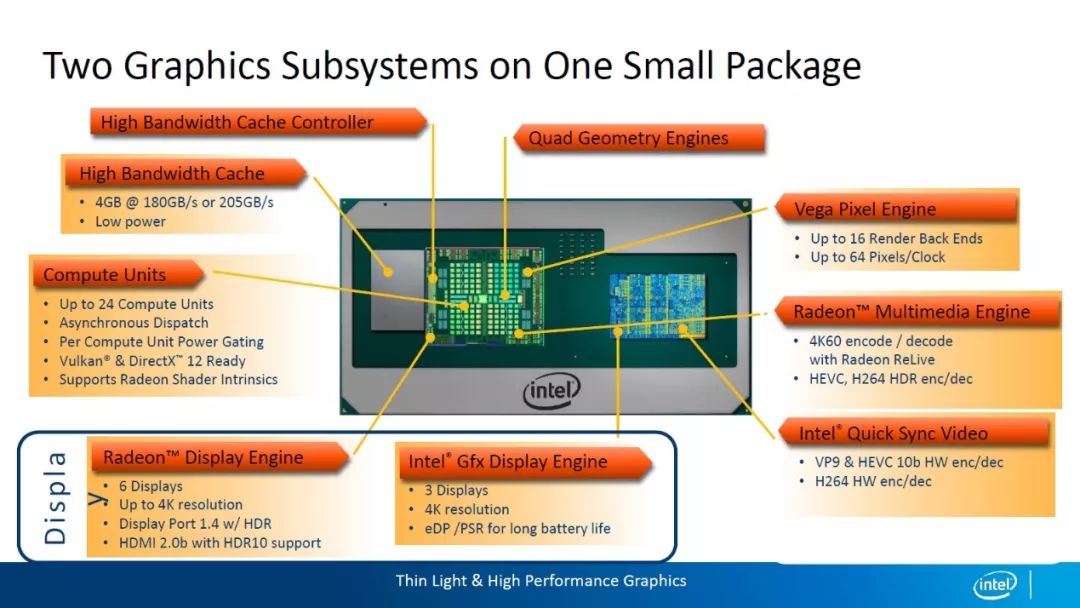







当AMD 可用更小芯片对抗英特尔产品

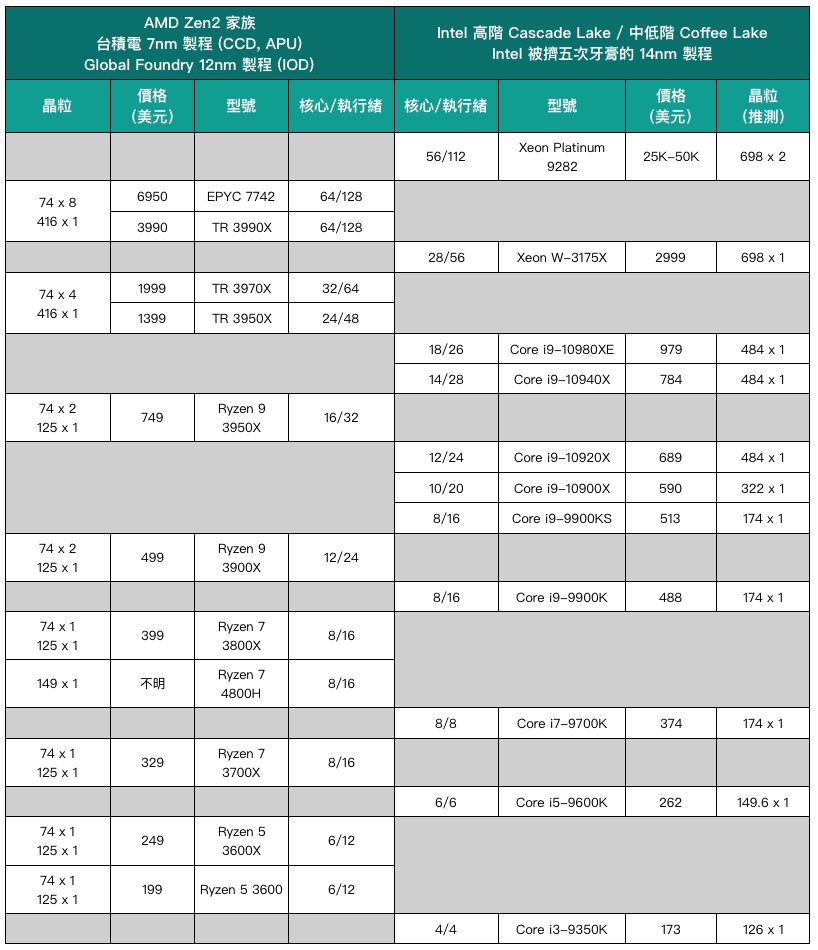
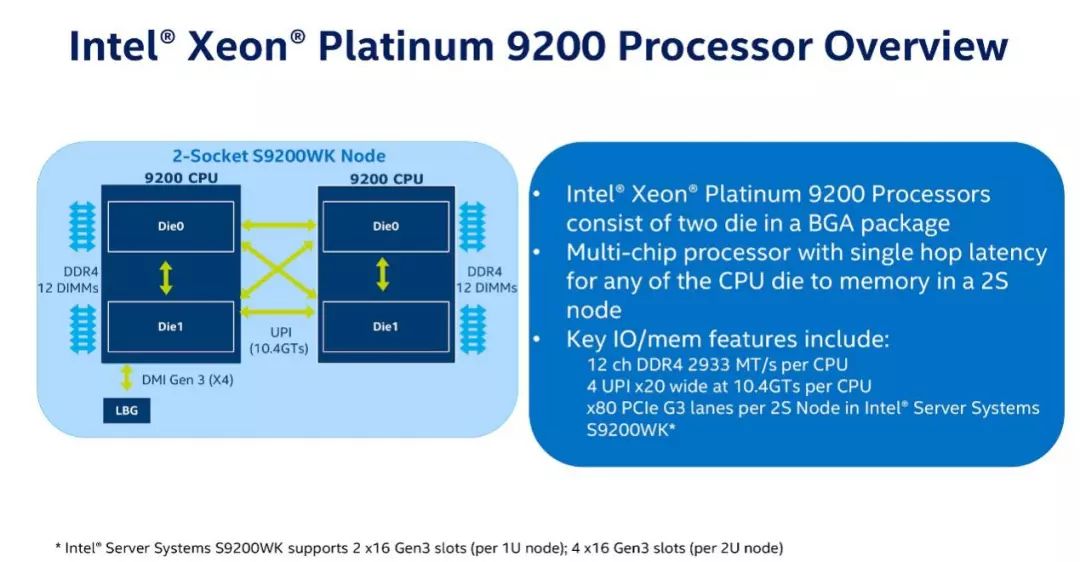
Zen 2 的实际优势并不只有台积电的7 纳米制程
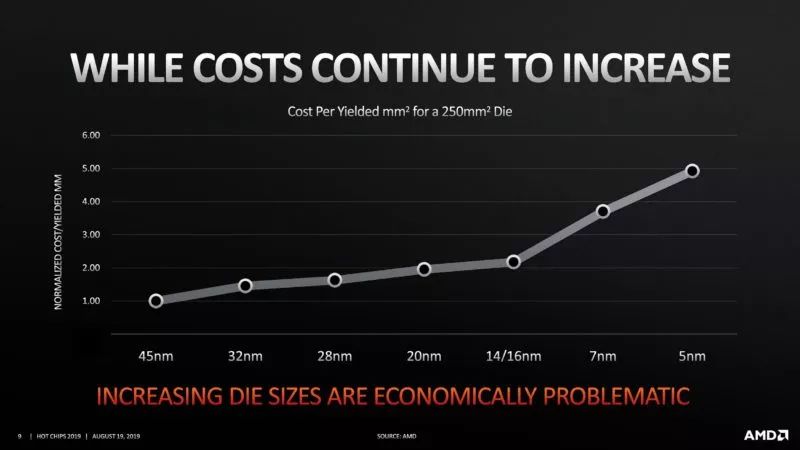
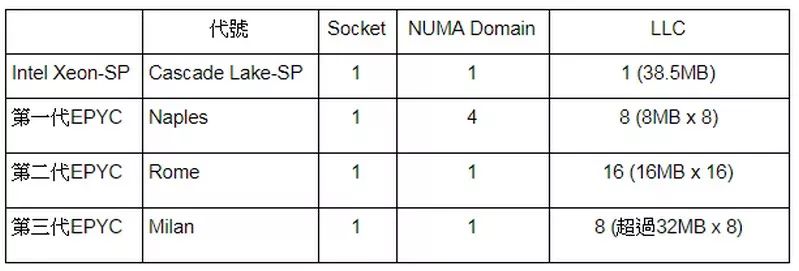
台积电先进制程天下无敌。 AMD Chiplet 策略高瞻远瞩。 AMD 的制造成本辗压英特尔。 万恶的英特尔快要挤不出牙膏了。
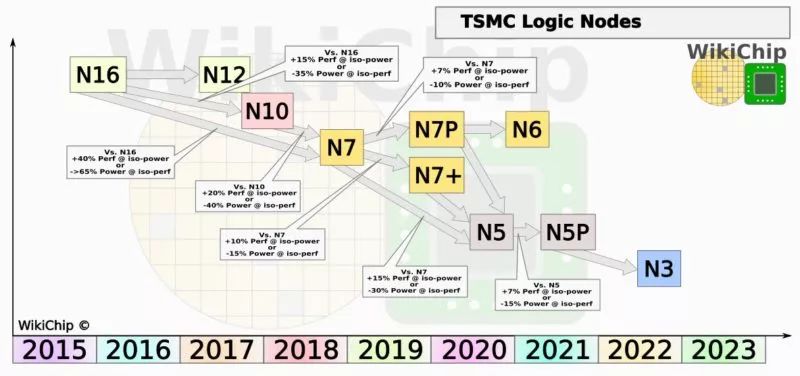
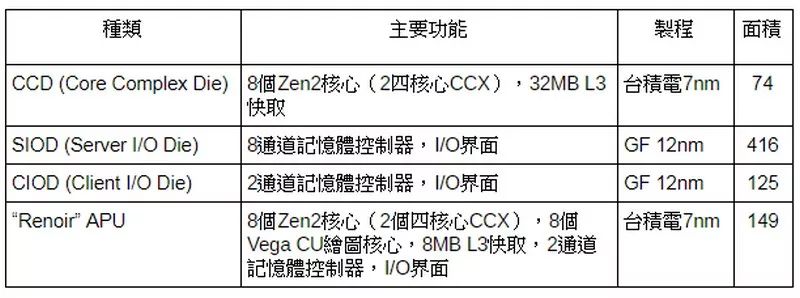
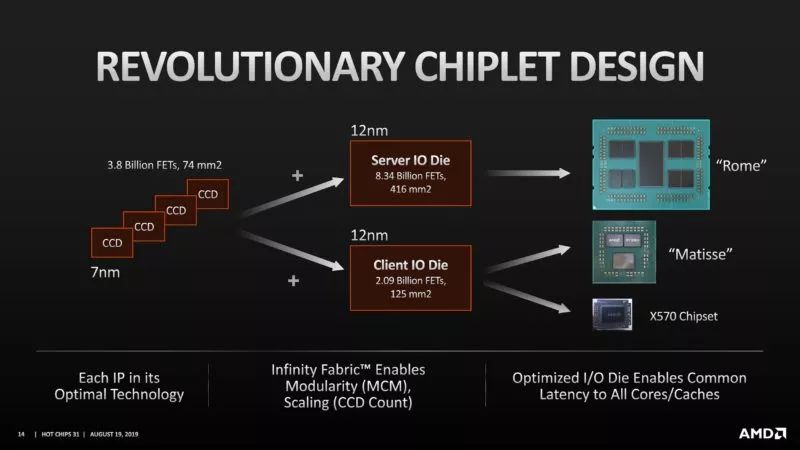
减少风险:I/O与记忆体控制器的IP区块,难以快速导入最先进制程。 提升弹性:同样的7纳米制程CCD和12纳米制程IOD可同时用在不同的产品线。 增加产能:用更少的晶圆数提供更多可出货产品,特别当台积电产能被苹果为首的大客户抢破头时。 改善效能:将记忆体控制器独立于CPU核心之外,可精简NUMA (Non-uniform memory access)Domain,利于软件最佳化,这绝对值得花时间解释。
记忆体控制器和CPU 脱钩是简化系统最佳化手段


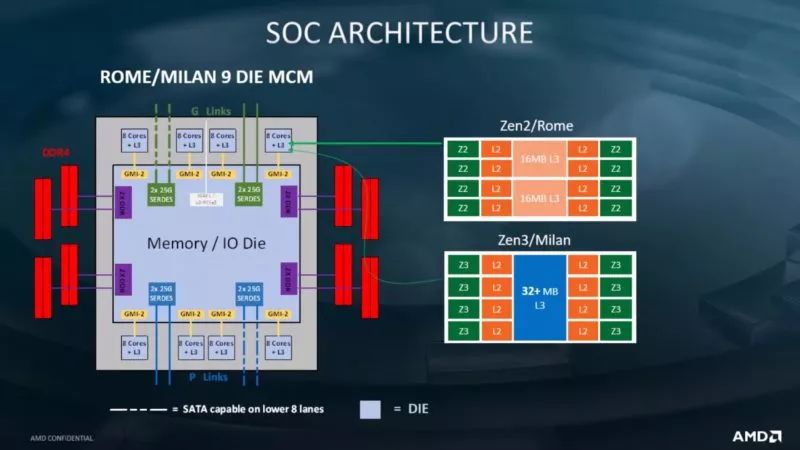
多芯片结构带来更复杂的系统调校工作
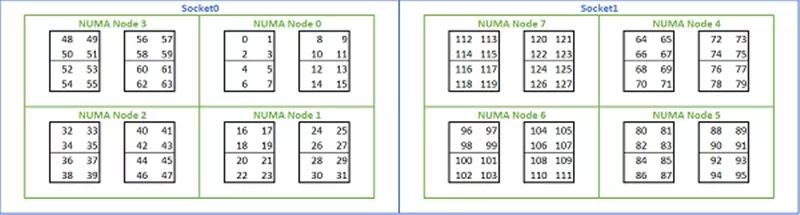
NUMA Nodes per Socket(NPS):名为每个处理器插座的NUMA节点(Node),但实际作用是「分而治之」、定义处理器核心群存取记忆体通道的方式。 NPS0:当安装两颗EPYC时,所有处理器核心如同只有一个NUMA Domain的交错存取所有总计16通道的主记忆体,这很明显没有效率(强迫存取另一颗EPYC的记忆体),所以连AMD官方都不建议这样做。 NPS1:EPYC所有处理器核心像同处同一个NUMA Domain同时交错存取8通道主记忆体(ABCDEFGH),最一般的「泛用」组态,整体理论频宽最高,存取延迟最长。 NPS2:记忆体通道拆成4条一组(ABCD EFGH),形同两个NUMA Domain(一半的核心)交错存取这两组。 NPS4:记忆体空到拆成2条一组(AB DC EF GH),有如4个NUMA Domain(四分之一的核心)交错存取这4组,整体理论频宽最低,存取延迟最短。
ACPI SRAT L3 Cache as NUMA Domain:这命名非常容易让人一头雾水,那L3 Cache实际上应该正名为CCX。讲白话一点,这功能是将CCX加入NUMA Domain,透过ACPI SRAT让作业系统或虚拟机管理者意识到其存在,让每个CCX「专心」存取自己的L3快取。以第二代EPYC为例,8颗CCD有16个CCX,启动此功能后,就等于告诉作业系统「我有16个CCX,每个都有自己的L3快取,请给我好好排程,尽量让CCX自己吃自己的L3」。


假若EPYC只有跑少少的虚拟机、部署少少的虚拟CPU,每个虚拟机和虚拟CPU都可以独自享受丰沛的硬件资源,那VMware建议设定就是:
NPS (NUMA per Socket) = 4
启动L3 Cache as NUMA
讲白一点就是就地分赃,「让虚拟机绑架专属的资源」。EPYC已跑了满满的虚拟机或部署满满的虚拟CPU,任何系统资源都不容许一丝一毫浪费,那就会变成:
NPS (NUMA per Socket) = 1
关闭L3 Cache as NUMA
换言之就是「独乐乐不如众乐乐」,大家一起吃大锅饭。关于高度平行化的高效能运算或其他已针对NUMA 最佳化的应用程式,Dell 建议NPS 设成4(应该也要开启L3 Cache as NUMA),可让这类应用「同时享受到最高的频宽与最低的延迟」。

核心数量太多也会制造麻烦
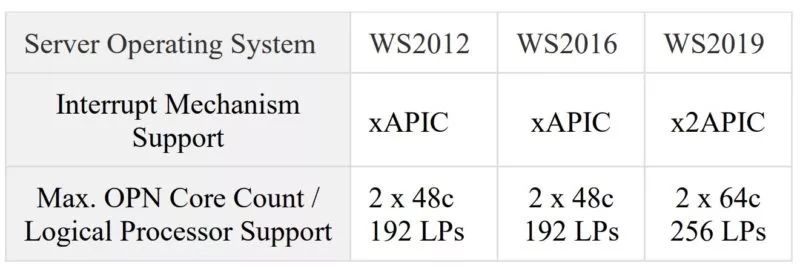

从英特尔无缝接轨到AMD 并非易事


福利

点击阅读原文,了解摩尔精英!