基于耦合知识蒸馏,速度提升200倍,一款视频显著区域检测新算法
Synced
AI科技评论
昨天
作者 | 爱奇艺
责编 | 贾伟
2020 年 2 月 7 日-2 月 12 日,AAAI 2020 将于美国纽约举办。不久之前,大会官方公布了今年的论文收录信息:收到 8800 篇提交论文,评审了 7737 篇,接收 1591 篇,接收率 20.6%。本文介绍了爱奇艺与北航等机构合作的论文《Ultrafast Video Attention Prediction with Coupled Knowledge Distillation》。
论文链接:https://arxiv.org/pdf/1904.04449.pdf
本论文
设计
了一个
超轻量级网络 UVA-Net
,并提出了一种基于耦合知识蒸馏的网络训练方法,在视频注意力预测方向的性能可与 11 个最新模型相媲美,而其存储空间仅占用 0.68 MB,在
GPU
,
CPU
上的速度分别达到 10,106FPS,404FPS,
比之前的模型提升了 206 倍。
由于传统的高精度视频显著区域检测模型往往对计算能力和存储能力有较高要求,处理速度较慢,造成了资源的浪费。因此,视频显著区域检测需要解决如下两个问题:1)如何降低模型的计算量和存储空间需求,提高处理效率?2)如何从视频中提取有效时空联合特征,避免准确率下降?
针对这些问题,作者提出了耦合知识蒸馏的轻量级视频显著区域检测方法 [1]。轻量级视频显著区域检测的难点在于模型泛化能力不足,
时域
空域线索结合难,影响方法的检测性能。为此,作者提出了一种轻量级的网络结构 UVA-Net,并利用耦合知识蒸馏的训练方法提高视频显著区域检测性能。
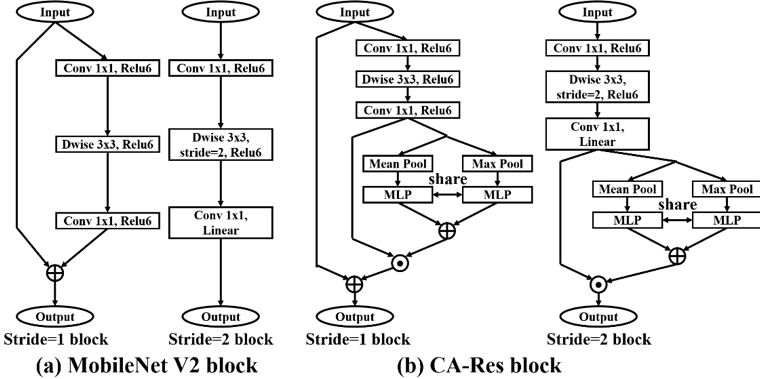
MobileNetV2 作为一种轻量级网络结构(如表 3(a)所示)在较大提高的网络的紧凑性的同时,损失了部分精度。作者在 MobileNetV2 的基础上提出了一种 CA-Res block 结构,具体如表 3(b)所示,利用这种网络结构训练的模型比之前的方法快 206 倍。
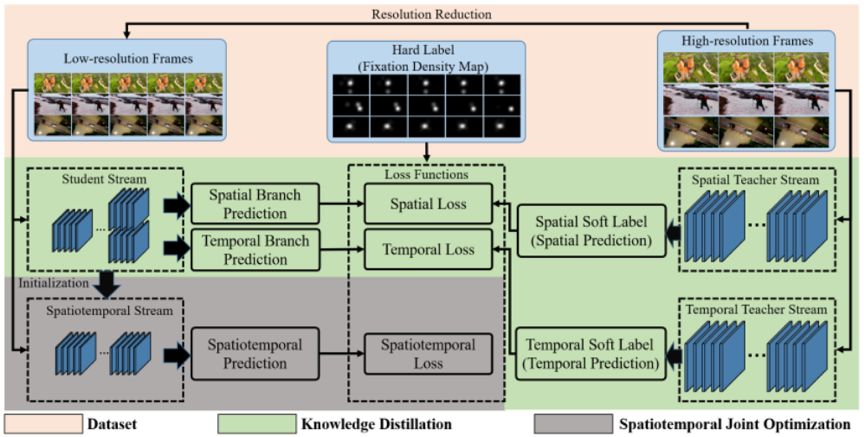
作者采用耦合知识蒸馏的方法来进行网络的训练,该方法首先使用低分辨率视频帧作为输入,在尽可能保留视频显著区域检测所需的
时域
和空域信息的前提下,减少网络的计算量;然后利用结构复杂的时域和空域网络作为教师模型,以耦合知识蒸馏的方式,监督训练结构简单的时空联合的学生模型,大幅度降低了模型参数规模和对存储空间的需求。具体如图 6 所示。
图 6:基于耦合知识蒸馏的超高速视频显著区域检测方法。
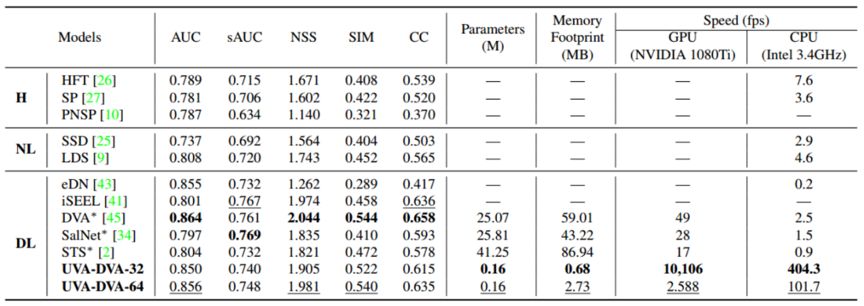
作者在 AVS1K 数据集上进行模型评测,具体结果如表 4 和表 5 所示。从表中我们可以看出 UVA-DVA-64 达到了和其他高性能模型相当的性能,但是模型只有 2.73M,速度达到了 404.3 FPS,而 UVA-DVA-32 性能虽略有下降,模型却只有 0.68M,速度达到了 10,106 FPS。
表 4:
在 AVS1K 上的性能对比。
表 5:
AVS1K 数据集上的代表性帧结果. (a) Video frame, (b) Ground truth, (c) HFT, (d)
SP
, (e) PNSP, (f)
SSD
, (g) LDS, (h) eDN, (i) iSEEL, (j) DVA, (k) SalNet, (l)
STS
, (m) UVA-DVA-32, (n) UVA-DVA-64.
作者提出的基于耦合知识蒸馏的超高速视频显著区域检测
算法
与现有的国际高水平方法相比,计算精度与 11 种国际高水平方法相当,能够有效解决任务中模型泛化能力不足,
时域
空域线索结合难导致的问题,并具有良好的视频显著区域检测效果,且易于迁移到其它任务。
目前该技术已经应用到爱奇艺以图搜剧、视频智能创作等产品中,显著性ROI区域的检测对精准理解图片、视频内容具有很大的帮助。例如爱奇艺智能创作的竖版模式,仅保留视频显著性内容,将从视频理解内容本身提高用户的观看体验。另外,视频显著性分析将对爱奇艺多个业务具有启发意义,例如爱奇艺奇观(
AI
雷达
)、只看TA等,给用户带来更优质的体验。
文献请引用:
[1]Fu, K., Shi, P., Song, Y., Ge, S., Lu, X. & Li, J. (2019). Ultrafast Video Attention Prediction with Coupled Knowledge Distillation. In AAAI, 2020.
AAAI 2020 报道:
新型冠状病毒疫情下,AAAI2020 还去开会吗?
美国拒绝入境,AAAI2020现场参会告吹,论文如何分享?
AAAI 最佳论文公布
AAAI 2020正式开幕,37%录用论文来自中国,连续三年制霸榜首
一文全览,知识图谱@AAAI 2020
Hinton AAAI2020 演讲全文:
这次终于把
胶囊网络
做对了
AAAI 2020 论文集:
AAAI 2020 论文解读会 @ 望京(附PPT下载)
AAAI 2020上的
NLP
有哪些研究风向?
微软 6 篇精选 AAAI 2020 论文
京东数科 6 篇精选AAAI 2020 论文
AAAI 2020 论文解读系列:
01. [中科院
自动化
所] 通过识别和翻译交互打造更优的语音翻译模型
02. [中科院
自动化
所] 全新视角,探究「目标检测」与「实例分割」的互惠关系
03. [北理工] 新角度看双线性池化,冗余、突发性问题本质源于哪里?
04. [复旦大学] 利用场景图针对图像序列进行故事生成
05. [腾讯
AI
Lab] 2100场王者荣耀,1v1胜率99.8%,腾讯绝悟 AI 技术解读
06. [复旦大学] 多任务学习,如何
设计
一个更好的参数共享机制?
07. [清华大学] 话到嘴边却忘了?这个模型能帮你 | 多通道反向词典模型
08. [北航等] DualVD:
一种视觉对话新框架
09. [清华大学] 借助BabelNet构建多语言义原知识库
10. [微软亚研] 沟壑易填:端到端语音翻译中预训练和微调的衔接方法
11. [微软亚研] 时间可以是二维的吗?基于二维时间图的视频内容片段检测
12. [清华大学] 用于少次关系学习的
神经网络
雪球机制
13. [中科院
自动化
所] 通过解纠缠
模型探测语义和语法的大脑表征机制
14. [中科院
自动化
所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上海交大] 基于图像查询的视频检索,代码已开源!
18. [奥卢大学] 基于
NAS
的 GCN 网络
设计
(视频解读)
19. [中科大] 智能教育系统中的神经认知诊断,从数据中学习交互函数
20. [北京大学] 图卷积中的多阶段自监督学习
算法
21. [清华大学] 全新模型,对话生成更流畅、更具个性化(视频解读,附PPT)
22. [华南理工] 面向文本识别的去耦注意力网络
23. [
自动化
所] 基于对抗视觉特征残差的零样本学习方法
24. [计算所] 引入评估模块,提升机器翻译流畅度和忠实度(已开源)
25. [北大&上交大] 姿态辅助下的多相机协作实现主动目标追踪
26. [
快手
] 重新审视图像美学评估 & 寻找精彩片段聚焦点
27. [计算所&微信
AI
] 改进训练目标,提升非
自回归模型
翻译质量(已开源)
28. [中科院&
云从科技
]:
双视图分类,利用多个弱标签提高分类性能
29. [中山大学] 基于树状结构策略的渐进
强
化学
习
30. [东北大学] 基于联合表示的神经机器翻译(视频解读)
31. [计算所]引入评估模块,提升机器翻译流畅度和忠实度(视频解读)
32. [清华大学]用于少次关系学习的
神经网络
雪球机制(视频解读)
33. [计算所]非自回归机器翻译,基于n元组的训练目标(视频解读)
34. [清华大学] 司法考试数据集(视频解读,附下载链接)
35. [
自动化
所] 弱监督语义分割(视频解读)
36. [
自动化
所] 稀疏二值
神经网络
,不需要任何技巧,取得SOTA精度(视频解读)
37. [华科&阿里] 从边界到文本—一种任意形状文本的检测方法
38. [上交大&
云从科技
] DCMN+ 模型:破解「阅读理解」难题,获全球领先成绩
39. [
自动化
所&微信
AI
] 双通道多步推理模型,更好解决视觉对话生成问题
40. [ETH Zurich] 反向R?
削弱显著特征为细粒度分类带来提升
41. [中科大] RiskOracle: 一种时空细粒度交通事故预测方法
42. [
华为
] 短小时序,如何预测?
——基于特征重构的张量ARIMA
43. [清华大学] 棋盘游戏做辅助,进行跳跃式标注(视频解读)
44. [商汤]
新视频语义分割和光流联合学习
算法
45. [商汤]
新弱监督目标检测框架
46. [第四范式]
优化
NAS
算法
,速度提高10倍!
47. [牛津大学] 利用注意力机制,实现最优相机定位(视频解读)
48. [天津大学] DIoU和CIoU:
IoU在目标检测中的正确打开方式
49. [宁夏大学] 面向大规模无标注视频的人脸对齐方法
50. [商汤] KPNet,追求轻量化的人脸检测器(视频解读)
51. [东北大学]
源和目标语句不再独立,联合表示更能提升机器翻译性能
52. [
腾讯
AI
Lab] 完全依存森林:
大幅缓解关系抽取中的错误传递
点击“
阅读
原文
” 前往
AAAI 2020 专题页
阅读原文
阅读
在看
已同步到看一看
写下你的想法
前往“发现”-“看一看”浏览“朋友在看”
前往看一看
看一看入口已关闭
在“设置”-“通用”-“发现页管理”打开“看一看”入口
我知道了
已发送
取消
发送到看一看
发送
基于耦合知识蒸馏,速度提升200倍,一款视频显著区域检测新算法
最多200字,当前共
字
发送中





 点击“阅读原文” 前往 AAAI 2020 专题页点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页点击“阅读原文” 前往 AAAI 2020 专题页