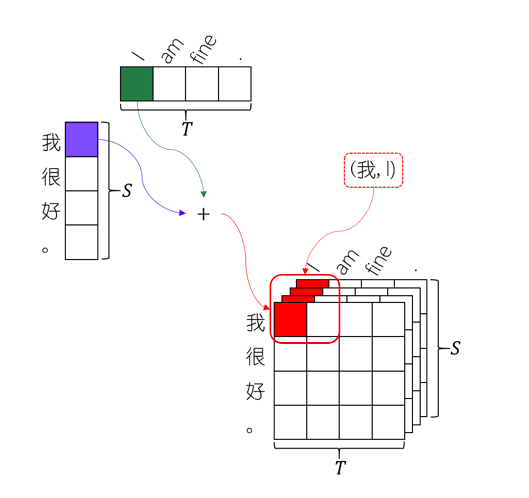
源和目标语句不再独立,联合表示更能提升机器翻译性能

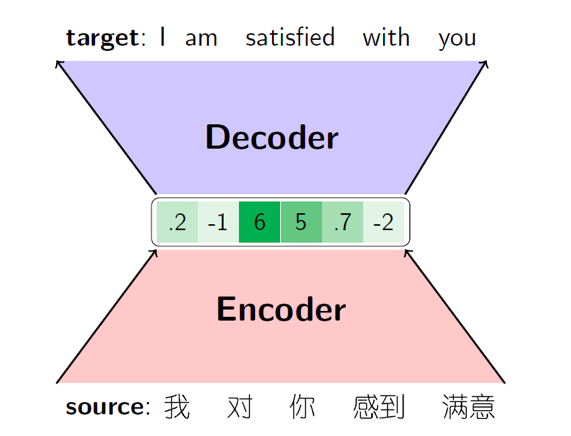
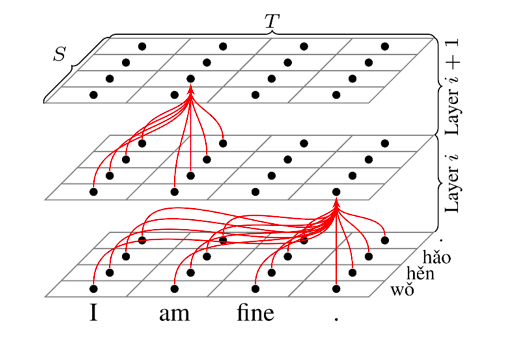
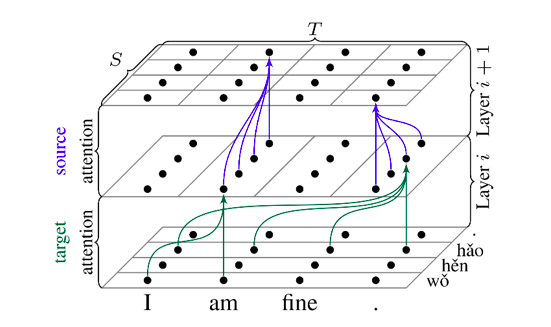
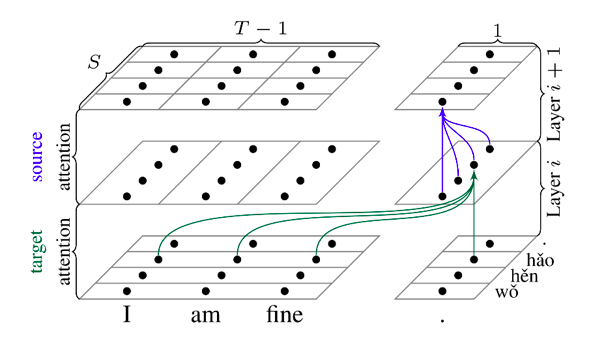
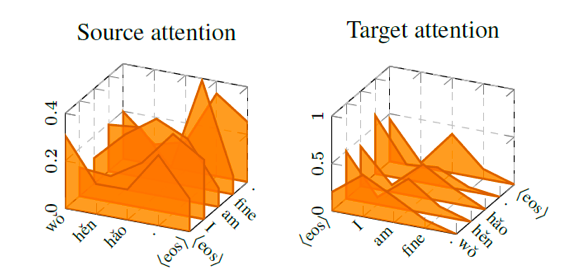
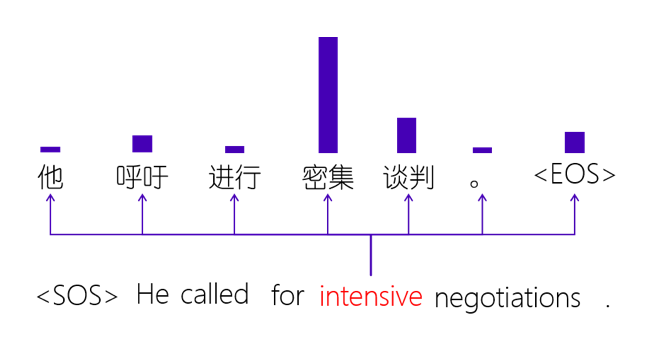 Figure 2注意力机制
Figure 2注意力机制
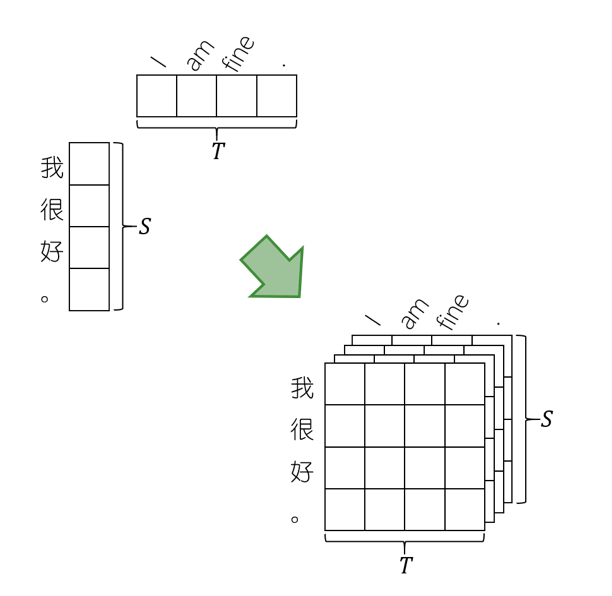
联合表示
Reformer-base
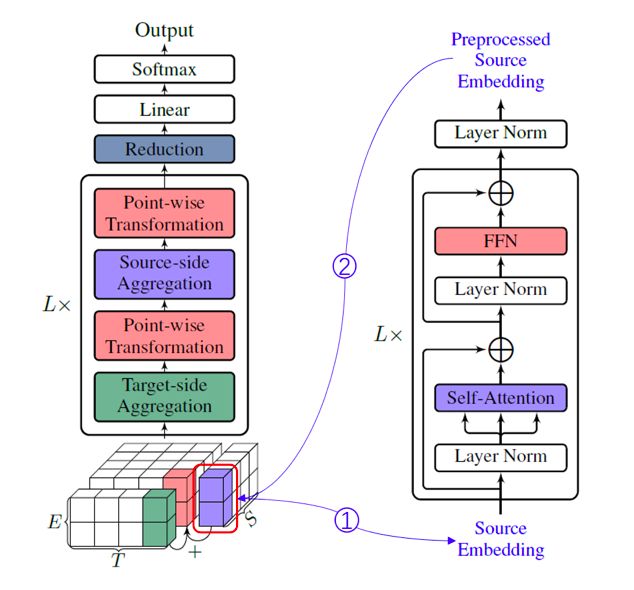
词嵌入
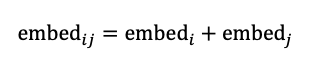
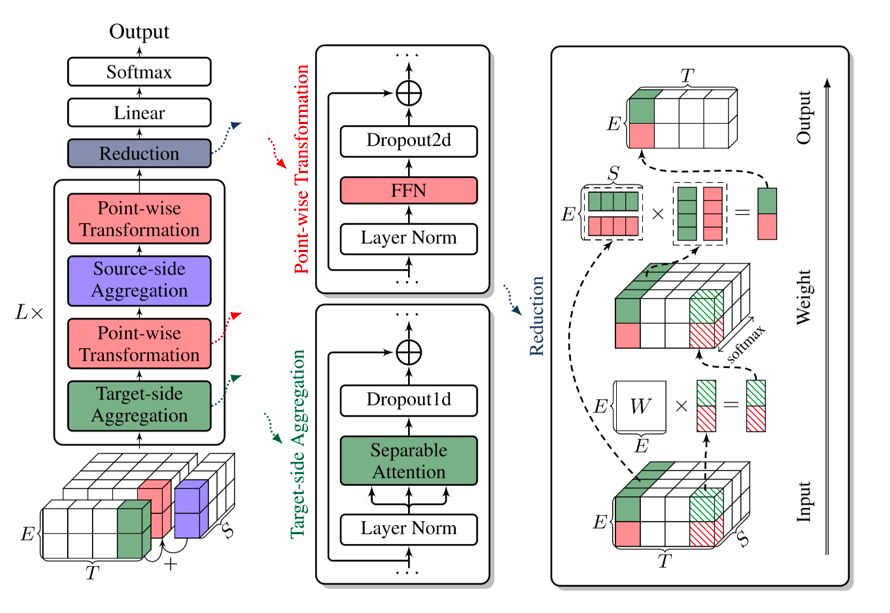
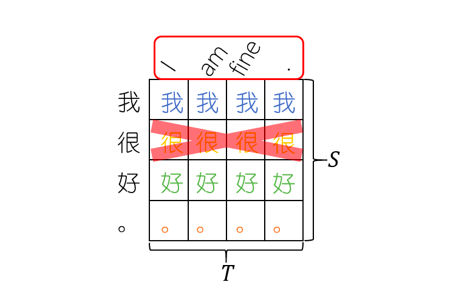
可分离注意力
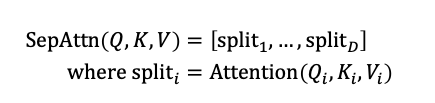
降维
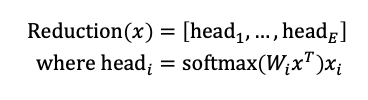
整体架构
Reformer-fast
权衡效率和有效性

PreNet
模型调优
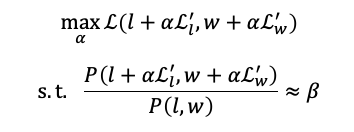
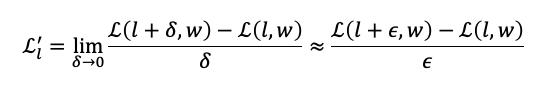
实验

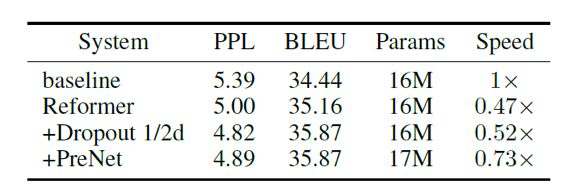
Table 3消融实验
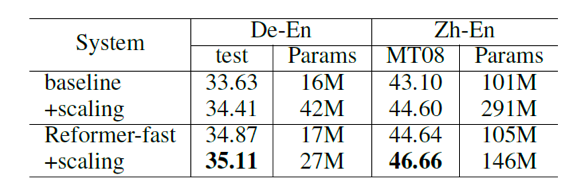
Table 3消融实验
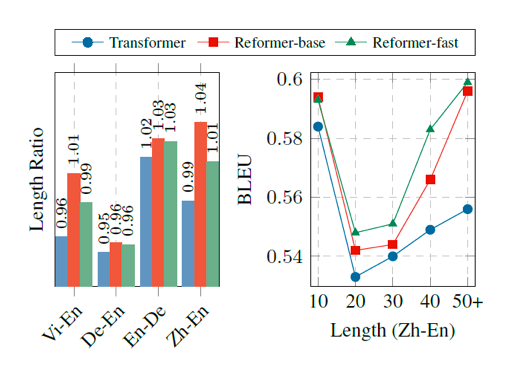
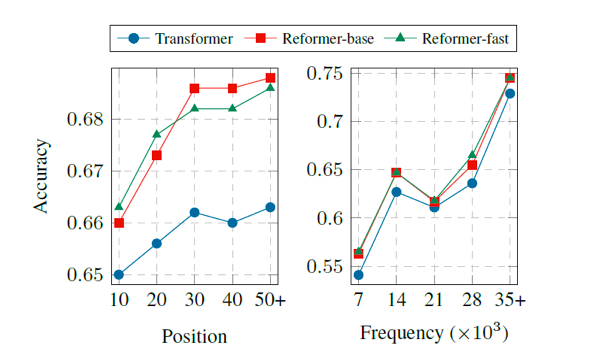
结论
AAAI 2020正式开幕,37%录用论文来自中国,连续三年制霸榜首
Hinton AAAI2020 演讲全文:这次终于把胶囊网络做对了


 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页