微软发布史上最大语言模型Turing-NLG:170亿参数量
本文转自"雷锋网"

英伟达的“威震天”现在只能屈居第二了。
文 | 周蕾
微软AI&Research今天分享了有史以来最大的基于Transformer架构的语言生成模型Turing NLG(下文简称为T-NLG),并开源了一个名为DeepSpeed的深度学习库,以简化对大型模型的分布式培训。
基于Transformer的架构,意味着该模型可以生成单词来完成开放式文本任务。除了完成未完成的句子外,它还可以生成对输入文档的问题和摘要的直接答案。
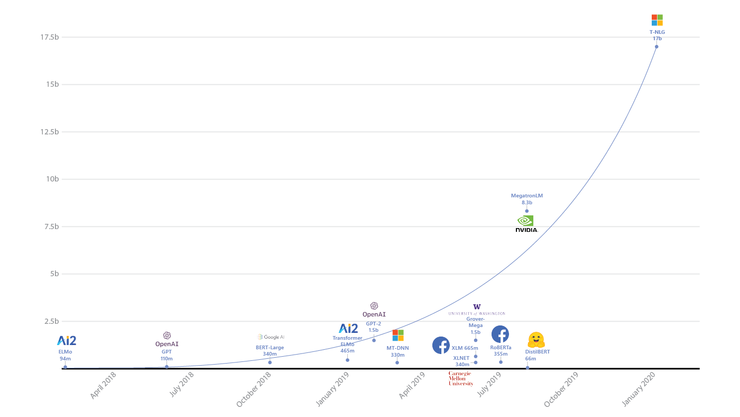
去年8月,英伟达曾宣布已训练世界上最大的基于Transformer的语言模型,当时该模型使用了83亿个参数,比BERT大24倍,比OpenAI的GPT-2大5倍。
而此次微软所分享的模型,T-NLG的参数为170亿个,是英伟达的Megatron(现在是第二大Transformer模型)的两倍,其参数是OpenAI的GPT-2的十倍。微软表示,T-NLG在各种语言建模基准上均优于最新技术,并在应用于许多实际任务(包括总结和问题解答)时表现出色。
不过,像Google的Meena一样,最初使用GPT-2,T-NLG最初只能在私人演示中共享。
微软AI研究应用科学家Corby Rosset在博客文章中写道:“除了通过汇总文档和电子邮件来节省用户时间之外,T-NLG还可以通过为作者提供写作帮助,并回答读者可能对文档提出的问题,由此来增强Microsoft Office套件的使用体验。”
具有Transformer架构的语言生成模型可以预测下一个单词。它们可用于编写故事,以完整的句子生成答案以及总结文本。
微软表示,他们的目标是在任何情况下都能够像人类一样直接,准确,流畅地做出响应:以前,问题解答和摘要系统依赖于从文档中提取现有内容,这些内容可以作为备用答案或摘要,但它们通常看起来不自然或不连贯。使用T-NLG这样的自然语言生成模型,可以自然地总结或回答有关个人文档或电子邮件主题的问题。
来自AI领域的专家告诉VentureBeat,2019年是NLP模型开创性的一年——使用Transformer架构无疑是2019年最大的机器学习趋势之一,这导致了语言生成领域和GLUE基准测试领导者的进步,Facebook的RoBERTa、谷歌的XLNet和微软的MT-DNN都纷纷加入到各类基准测试榜首的争夺当中。
同样是在今天,微软还开源了一个名为DeepSpeed的深度学习库。该学习库已针对开发人员进行了优化,以提供低延迟、高吞吐量的推理。
DeepSpeed包含零冗余优化器(ZeRO),用于大规模训练具有1亿个或更多参数的模型,微软过去曾用它训练T-NLG。
微软表示,DeepSpeed和ZeRO使得他们能够降低模型并行度(从16降低到4),将每个节点的批处理大小增加四倍,并将训练时间减少了三分之二;DeepSpeed使用更少的GPU可以使大型模型的训练效率更高。
开发人员和机器学习从业人员都可以使用DeepSpeed和ZeRO,因为培训大型网络(例如利用Transformer架构的网络)可能会很昂贵,并且可能会遇到大规模问题。
另外,Google的DeepMind今天也发布了一种新的远程内存模型Compressive Transformer,以及一种针对书本级语言建模的新基准PG19。
相关论文:https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
