2019 NLP大全:论文、博客、教程、工程进展全梳理(长文预警)
选自Medium
在整个2019年,NLP领域都沉淀了哪些东西?有没有什么是你错过的?如果觉得自己梳理太费时,不妨看一下本文作者整理的结果。

研究论文
机器学习/自然语言处理的创造力和社群
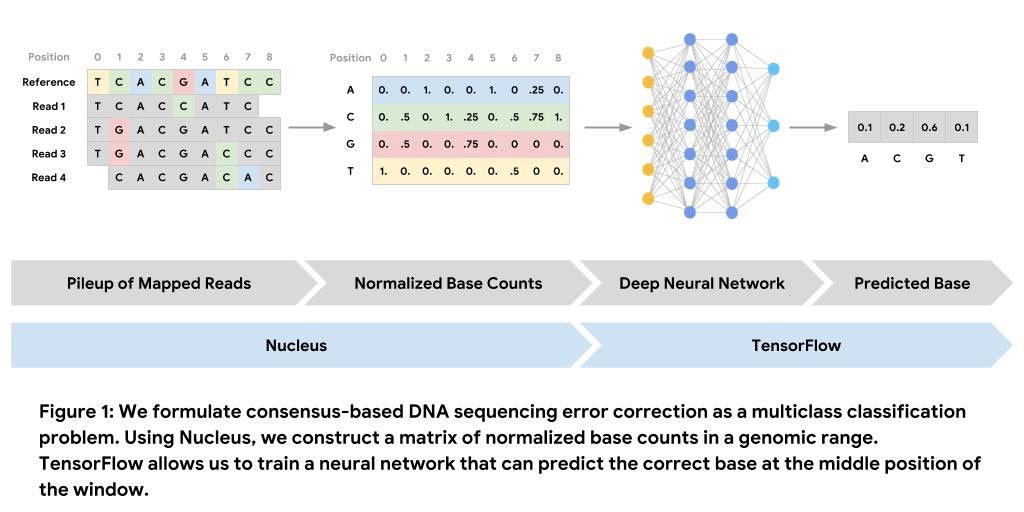
工具和数据集
博文文章
教程资源
人工智能伦理学

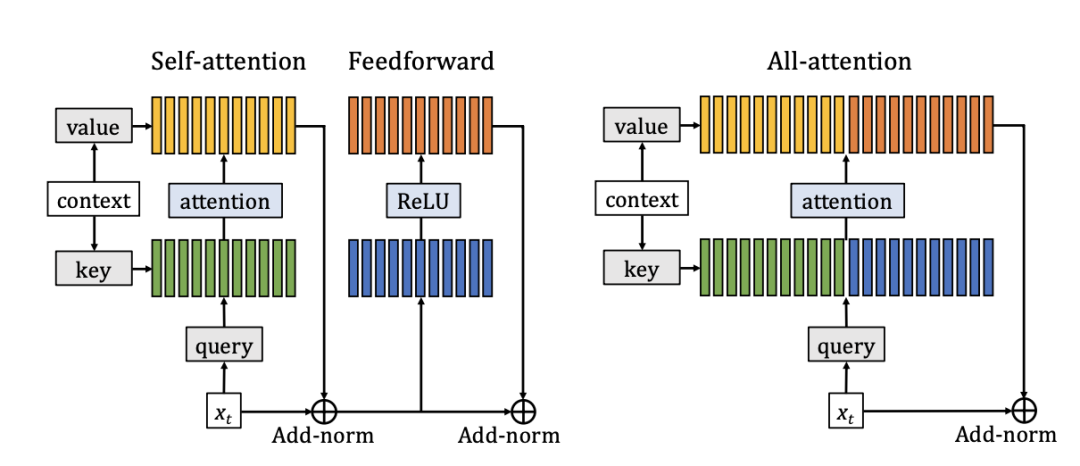
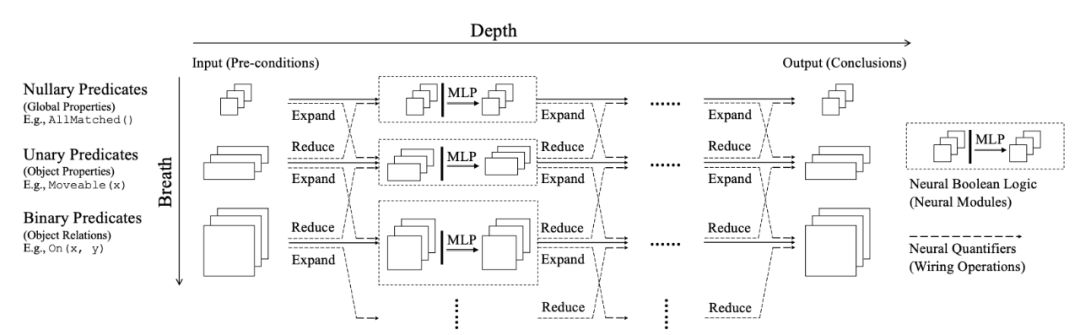
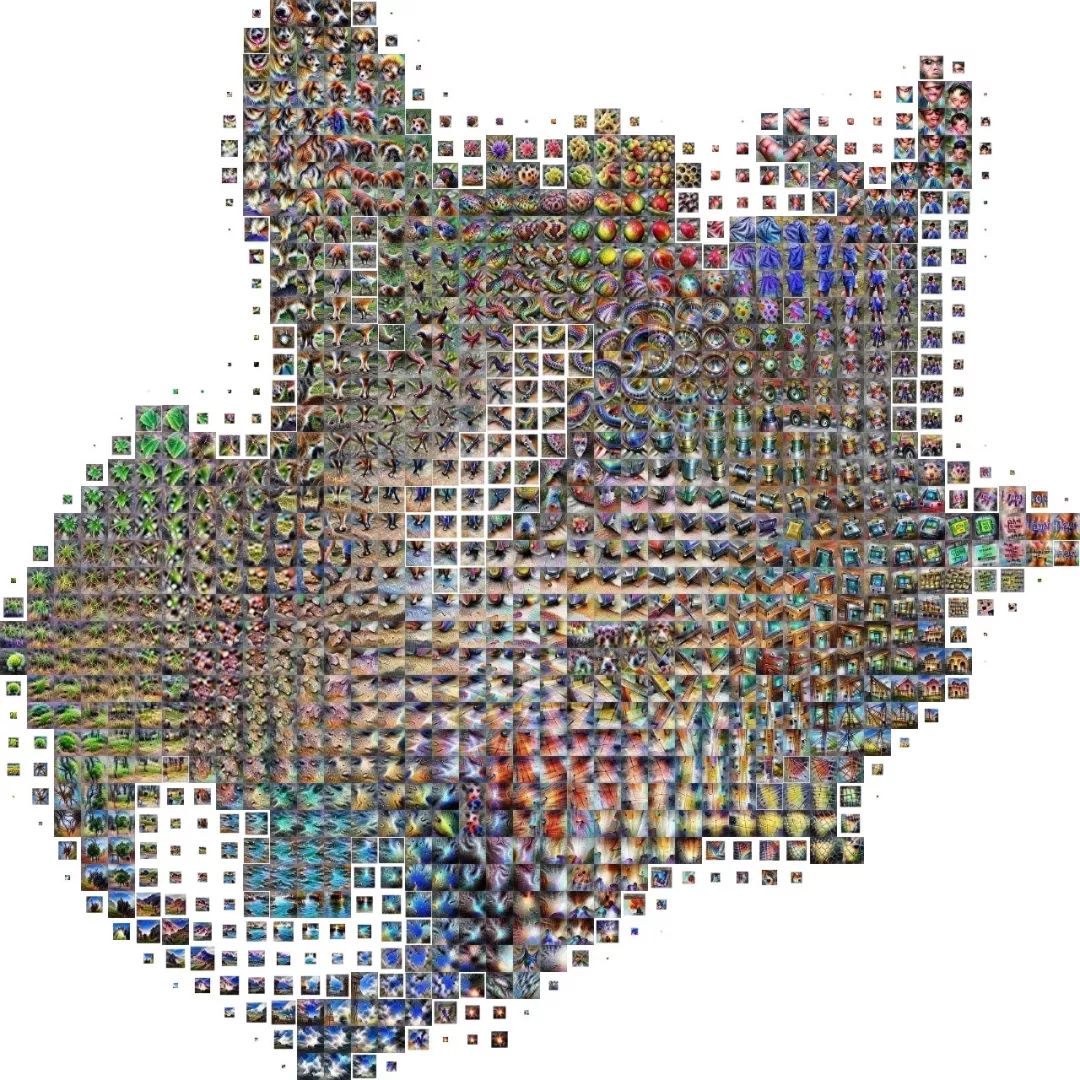
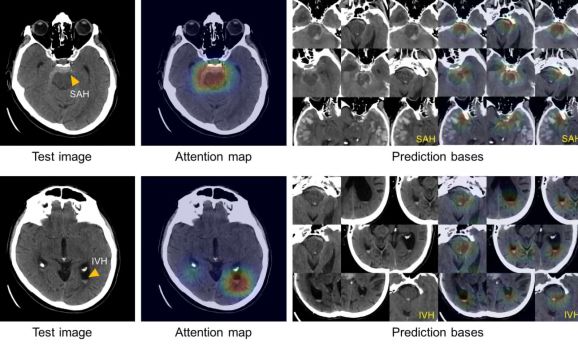

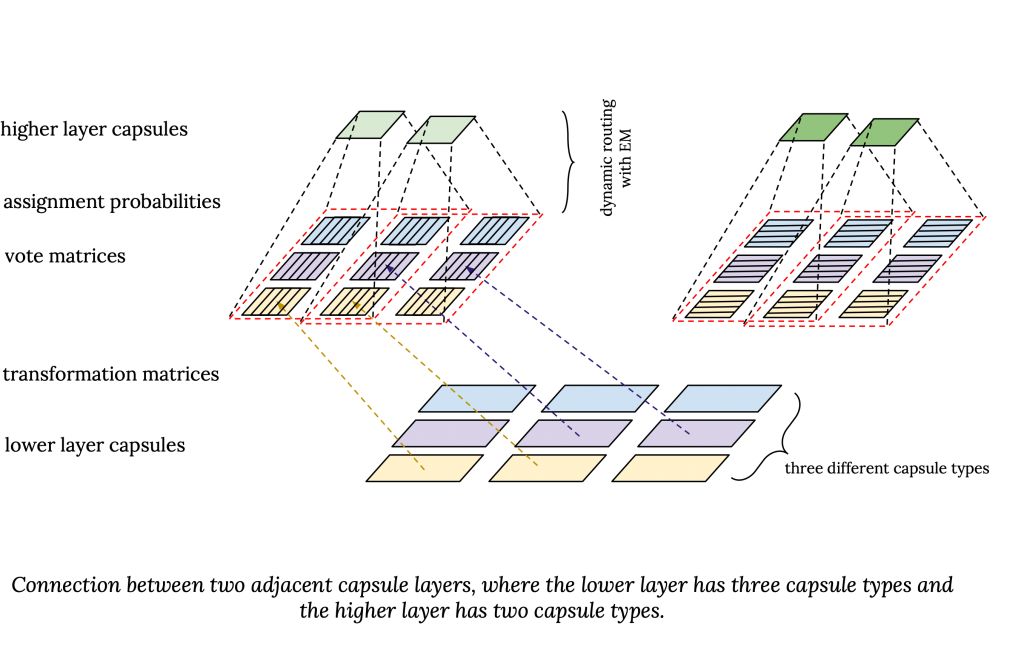
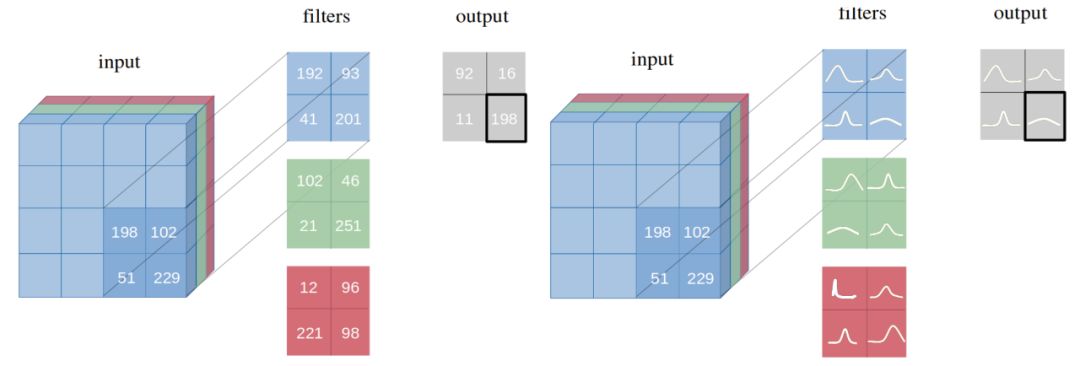
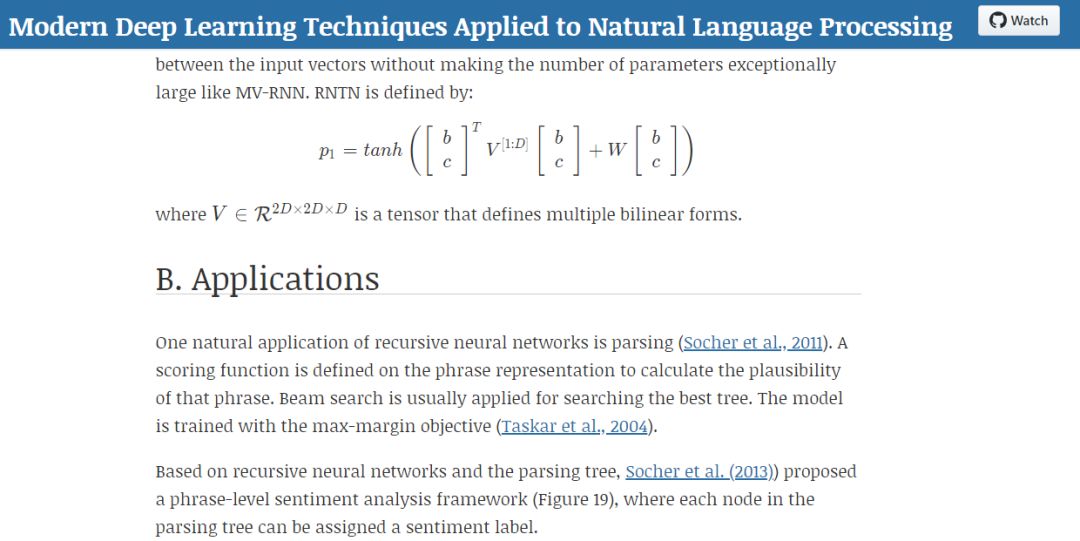

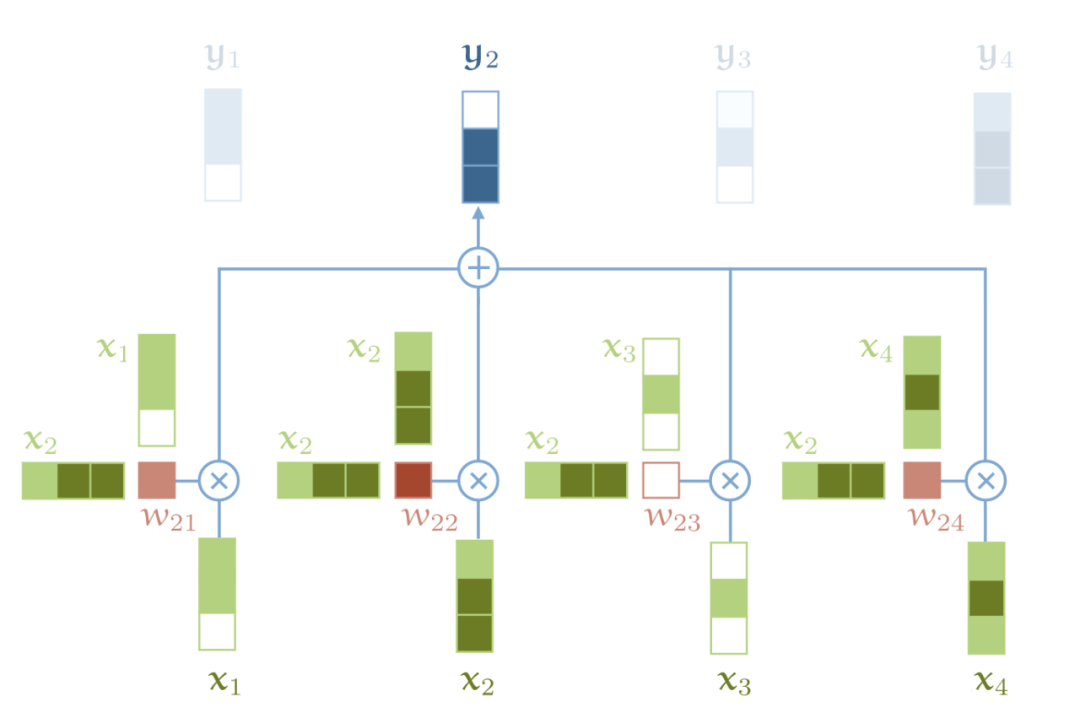

选自Medium
在整个2019年,NLP领域都沉淀了哪些东西?有没有什么是你错过的?如果觉得自己梳理太费时,不妨看一下本文作者整理的结果。
研究论文
机器学习/自然语言处理的创造力和社群
工具和数据集
博文文章
教程资源
人工智能伦理学