【最全中文NLP数据集】10大类、142条数据源,总有一款适合你!
CLUE benchmark
机器学习算法与Python学习
今天
本文授权转自"
机器之心
"(almosthuman2014)
中文
NLP
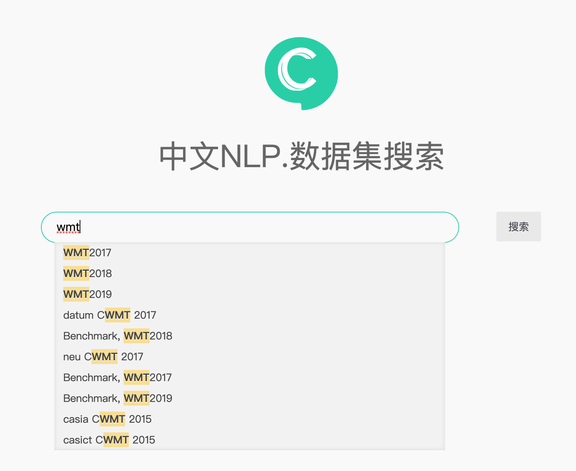
数据集搜索:
https://www.cluebenchmarks.com/dataSet_search.html
在学习
NLP
的这条不归路上,我们总会发现大多数先进
算法
与优质示例代码都是用英文数据集。
而当我们满怀希望地把模型迁移到中文世界时,缺少公开的优质数据集简直就是天堑。
比如说最简单的语言模型与词嵌入模型,只需要一段段自然的中文文本就行了,然而实际上我们会发现好用的公开大型语料真的很少。
我们需要在 GitHub 等平台上找收集中文
NLP
数据集的各种项目,再根据需求进行选择。
值得注意的是,很多国内中文数据集已经非常老了,它们的使用会比较麻烦,这时候就需要我们自行判断与试错了。
不过在本文中,我们将介绍一项新的中文
NLP
数据搜索项目,
它可能是目前最全的中文
NLP
数据集信息收集项目
。
该项目收集了一百多条中文
NLP
数据信息,并以搜索的形式展示结果。
我们只要键入关键词,或者数据集所属的领域等信息,就能找到对应的数据集。
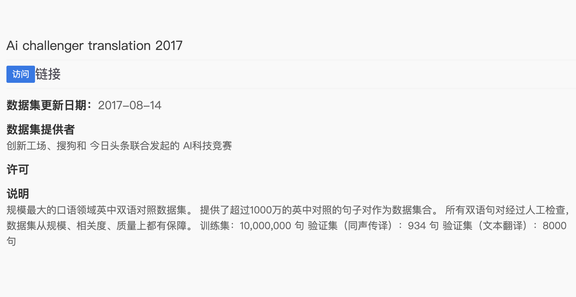
每一条搜索结果都会展示数据集的基本信息、访问链接等关键信息,能帮助我们快速筛选数据集。
因为每一个领域都能找到非常多的同类数据集,因此这些简述非常有意义。
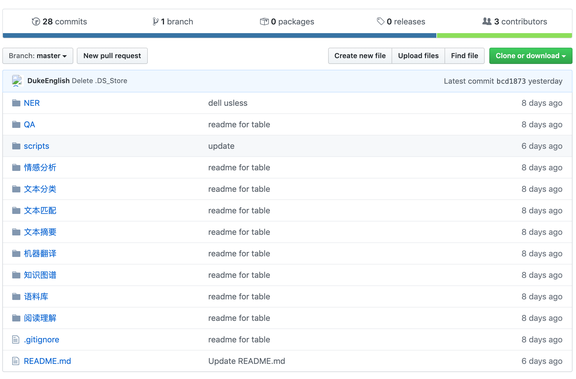
如果读者想看看到底有哪些数据集,可以直接查看该搜索项目的 GitHub 地址,所有数据集的信息都在上面。
这可能是最全的中文
NLP
数据集合
本项目中的
NLP
数据集囊括了 NER、QA、情感分析、文本分类、文本分配、文本摘要、机器翻译、知识图谱、语料库以及阅读理解等 10 大类共 142 个数据集。
具体而言,对于每一个数据集,项目作者都提供了数据集名称、更新时间、数据集提供者、说明、关键字、类别以及论文地址等几方面的信息。
项目地址:
https://github.com/CLUEbenchmark/CLUEDatasetSearch
本项目中文
NLP
数据集分类。
但由于整个项目包含的数据集种类很多,
机器之心
只对其中的情感分析和文本分类数据集进行以下简要介绍。
情感分析
作为
自然语言处理
(
NLP
)的一种常见应用,情感分析特别适用于以提取文本情感内容为目的的分类方法中。
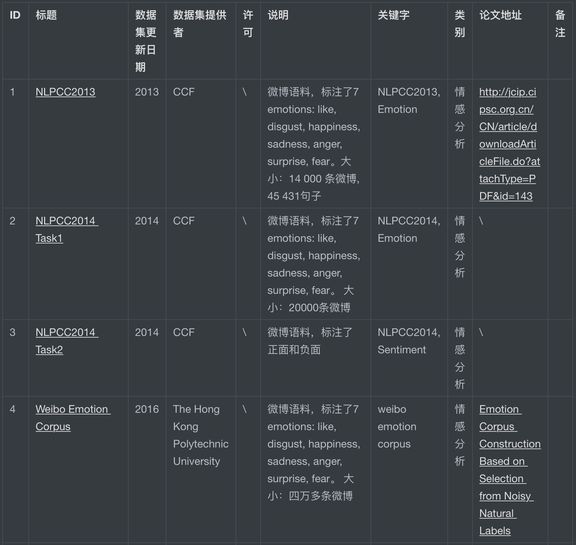
本项目中介绍了 11 个情感分析数据集来源
,其中包括 NLPCC 2013/2014、Weibo Emotions Corpus、之江杯电商评论观点挖掘大赛以及 2019 搜狐校园
算法
大赛数据集。
项目中部分情感分析中文数据集详情。
文本分类
作为
自然语言处理
中最常用和最基础的应用,文本分类方面的数据集已经有很多。
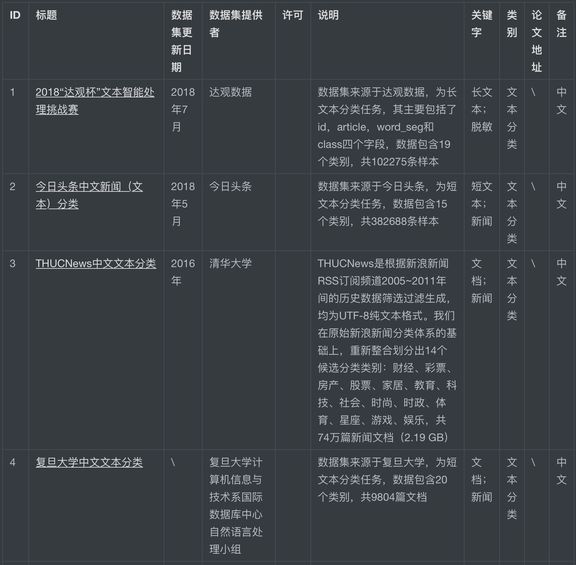
本项目中介绍了 19 个文本分类数据集来源,其中包括今日头条中文新闻(文本)分类、THUCNews 中文文本分类、2017 知乎看山杯
机器学习
挑战赛 以及中科大新闻分类语料库等。
项目中部分文本分类数据集详情。
最后,开发者也可以上传数据集信息贡献自己的力量,上传 5 个(含)以上数据集信息即可在审核通过后成为本项目的贡献者。
目前似乎 142 个数据集已经很全了,但对于更多
NLP
子领域任务,还需要大家共同维护。
* 凡来源非注明“
机器学习算法与Python学习
原创”的所有作品均为转载稿件,其目的在于促进信息交流,并不代表本公众号赞同其观点或对其内容真实性负责。
推荐阅读
【资源】 866页《
计算机视觉
:原理,
算法
,应用,学习》第五版免费下载!
【入门】
Python
函数式编程,这篇文章就够了
Python
3.9又更新了:dict内置新功能,正式版十月见面
【资源】547页中文PDF《动手学
深度学习
》免费下载, 李沐大神出品 !
阅读
在看
已同步到看一看
写下你的想法
前往“发现”-“看一看”浏览“朋友在看”
前往看一看
看一看入口已关闭
在“设置”-“通用”-“发现页管理”打开“看一看”入口
我知道了
已发送
取消
发送到看一看
发送
【最全中文NLP数据集】10大类、142条数据源,总有一款适合你!
最多200字,当前共
字
发送中