ICRA 2020:重新探索视觉里程计,从何学起? | 将门好声音

本文内容来自将门计算机视觉社群
作者:粘煌荧
关于作者
粘煌荧,本科毕业于香港中文大学,目前阿德莱德大学博士在读,师从Prof. Ian Reid,澳大利亚机器人视觉中心(ACRV)以及澳大利亚机器学习研究所(AIML)成员。研究方向包括传统几何与深度学习的结合,自监督学习的深度估计,3D重建。
个人主页:huangying-zhan.github.io
Email: huangying.zhan@adelaide.edu.au

相关链接
GitHub: https://github.com/Huangying-Zhan/DF-VO
Arxiv: https://arxiv.org/abs/1909.09803
Demo: https://www.youtube.com/watch?v=Nl8mFU4SJKY


单目VO系统求解的方法有很多种,大致可以分为稀疏的特征点法以及稠密的直接法。我们的方法属于前者中的光流法。
传统的特征点法已经有一套规范性的求解流程,涉及图像特征点检测,描述以及匹配。
假设有2张图片,透过匹配好的2D-2D特征点,可以用对极几何(Epipolar Geometry)去解Fundamental/Essential matrix,再进一步去恢复2帧之间的relative pose (Rotation, translation)。但是解Essential matrix存在几个问题,例如
(1)尺度的ambiguity: translation缺少一个尺度;
(2) translation过小时不稳定的解。
假如我们有其中一张图片的3维结构(depth),再结合匹配好的2D-2D匹配,那就可以用3D-2D的匹配去求解pose。最普遍的方法就是用Perspective-n-point (PnP),而使用3D-2D的匹配去求解pose也避免了2D-2D的一些问题。
提出的方法

假设我们有2个训练好的model,分别可以预测single-view depth和two-view optical flow,这些prediction就足以给出3D-2D以及2D-2D匹配。目前的optical flow network (我们采用的是CUHK的LiteFlowNet)足够预测比较精确的flow(2D-2D匹配),但是,目前的single-view depth精确度不足以给出精确的3D-2D匹配,所以求解出来的pose也不够准确。我们通过实验也验证了用这种3D-2D匹配,使用PnP求解出的pose是不够精确的。
虽然optical flow比较精确,但是
(1)不是所有pixel都足够精准;
(2)我们不需要dense的flow/correspondence来求解pose;
所以我们采用了一个很简单却有效的方法来挑选好的optical flow。
我们预测optical flow时同时预测了双向的optical flow(forward和backward),通过简单地检查forward-backward consistency,可以进而利用这个consistency来选择比较好的optical flow。
通过挑选过的2D-2D匹配,我们可以用epipolar geometry求解精准的rotation和translation direction(少了一个scale),这时候,我们可以进一步做triangulation。用triangulation得出的3D结构跟single-view depth prediction做一个对比,得出一个scale。这样就可以有了一个frame-to-frame的pose estimator。
只是,前文提过epipolar geometry在一些情况下不好求解pose,我们用了一些简单的检测来选择使用epipolar geometry或者PnP (2D-2D / 3D-2D匹配)。

使用这个简单的方法能给出很精确的relative pose,主要的优势在于:
(1) 传统方法的光流法,基本上只能给出稀疏的光流,但是CNN的Optical flow是dense的,用简单的forward-backward consistency可以剔除大量不好的匹配(常见的包括out-of-view region; occlusion; dynamic objects等),也可以挑选出很好的匹配,用这些精准的匹配可以求解出很好的relative pose(缺一个scale)。
(2) 虽然目前的single-view depth estimator不够给出精准的3D-2D匹配,但足够求解scale,而且,因为depth model本身带着的scale是CONSISTENT OVER TIME,这一个特点使我们的VO系统不受传统单目的scale-drift影响。
前面我们假设已经有了2个训练好的DepthCNN和FlowCNN, 那我们这个工作的CNN是怎么训练的呢?
我们当然可以用常见的supervised learning来学,但是我们主要采用self-supervised的方法来训练,这样就不需要GT的数据。
对于DepthCNN,我们主要follow Monodepth2的方法来train,但也做了一些小改进。
对于FlowCNN,我们主要follow LiteFlowNet的方法,使用了在Synthetic dataset(Scene Flow) pretrain好的model。即使在Synthetic dataset训练,但由于任务的通用性, LiteFlowNet也可以适用在real dataset (例如KITTI)上。我们也提出了一个简单的self-supervised finetuning方法来得到更好的model。
如果希望了解更多,请参考文章
实验结果
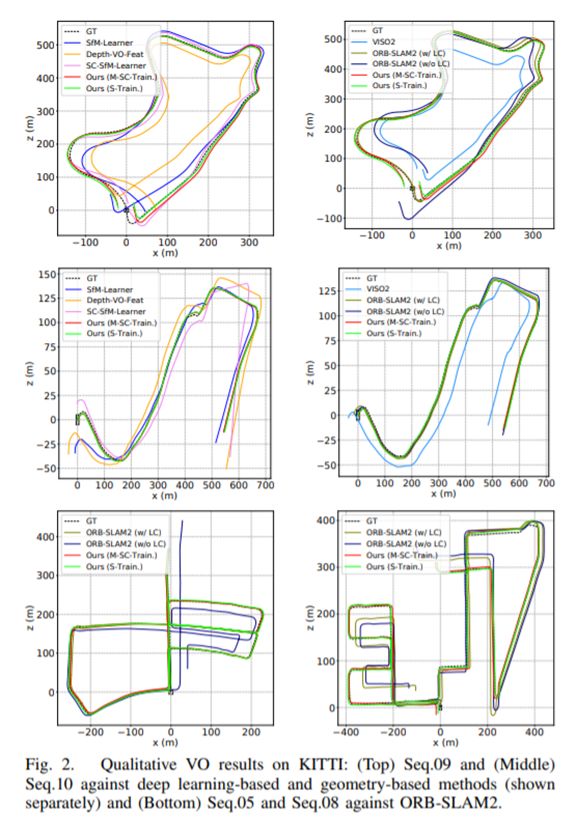
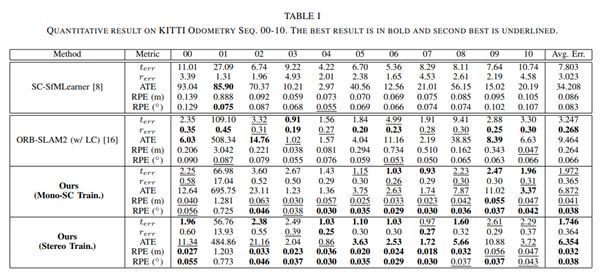
我们主要是在大型的数据集(KITTI)上测试我们的系统, 包括ablation study以及和一些纯深度学习/传统VO/SLAM方法的对比。在这边,我只列了一些比较近期/代表性的工作的对比。详细实验/对比请参考完整文章。可以看到虽然我们的方法很简单,但整体效果优于其他方法,特别是很有代表性的ORB-SLAM2 (Monocular)。更重要的是,我们的方法在单纯frame-to-frame的relative pose预测上很精确,可以进一步嵌入更完整的SLAM系统去帮助localization的表现。
系统的不足/未来方向
(1) 实时性:作为一个VO/SLAM系统,实时性是很有必要的,可是我们的方法依赖于dense optical flow prediction,即使我们挑选了速度比较快的LiteFlowNet,但我们的系统仍然无法做到30FPS的实时性(目前大概3-8FPS@GTX1070)。如何更快地得出精确的optical flow/correspondence?
(2) 更合理的系统设计:目前我们用了一些很简单的条件检查来选择Epipolar geometry/PnP Mode,但这些简单的检查不能百分百地选择合适的model,那如何设计更合理的model selection?
(3) Dynamic environment的应用:虽然forward-backward flow consistency可以移除部份dynamic object的correspondence,而且我们的pose estimation是在RANSAC的框架下做的, 所以大部份情况来说, dynamic object的影响相对比较低,但是当场景里有大量dynamic object时,我们的系统仍然会受影响。如何提升在dynamic environment的效果?
我们目前也在针对这些方面做一些尝试,敬请期待~
Reference
[1]: C. Godard, O. Mac Aodha, M. Firman,and G. J. Brostow, “Digging into self-supervised monocular depth prediction,”in IEEE International Conference on Computer Vision (ICCV), 2019.
[2]: T.-W. Hui, X. Tang, and C. C. Loy,“Liteflownet: A lightweight convolutional neural network for optical flowestimation,” in IEEE Conference on Computer Vision and Pattern Recognition(CVPR), June 2018, pp. 8981–8989.
[3]: A. Geiger, P. Lenz, and R. Urtasun,“Are we ready for autonomous driving? the kitti vision benchmark suite,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012
[4]: R. Mur-Artal and J. D. Tardos,“ORB-SLAM2: an open-source SLAM ´ system for monocular, stereo and RGB-Dcameras,” CoRR, vol. abs/1610.06475, 2016.


来扫我呀
关于我门
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
将门创新服务专注于使创新的技术落地于真正的应用场景,激活和实现全新的商业价值,服务于行业领先企业和技术创新型创业公司。
将门技术社群专注于帮助技术创新型的创业公司提供来自产、学、研、创领域的核心技术专家的技术分享和学习内容,使创新成为持续的核心竞争力。
将门创投基金专注于投资通过技术创新激活商业场景,实现商业价值的初创企业,关注技术领域包括机器智能、物联网、自然人机交互、企业计算。在四年的时间里,将门创投基金已经投资了包括量化派、码隆科技、禾赛科技、宽拓科技、杉数科技、迪英加科技等数十家具有高成长潜力的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: bp@thejiangmen.com


将门创投
让创新获得认可!
微信:thejiangmen
bp@thejiangmen.com
点击“❀在看”,让更多朋友们看到吧~