推出 AutoFlip:智能视频重构的开源框架
文 / 高级软件工程师 Nathan Frey 和 Zheng SunGoogle Research
一般情况下,我们会以 16:9 或 4:3 的宽高比例拍摄与剪辑视频,当我们在电视和台式机设备播放这些视频时,并没有太多问题。
然而,随着越来越多的用户开始在移动设备上创建和观看视频,经常会出现以往所采用的比例无法适用于播放设备的情况。这种情况下,我们需要将视频重构为不同的宽高比例。传统方法 通常是采用静态裁剪 (Static Cropping),即在指定窗口比例时,裁掉窗口区域外的视觉内容。遗憾的是,由于拍摄者构图与相机运动风格的多样,这类静态方法的效果往往不尽人意。然而,若想采用更加 定制化的方法 :则需要视频剪辑者人工识别每一帧上的重点内容,在内容帧与帧的转换间追踪,最后再对整个视频中的裁剪区域相应调整。这一过程往往步骤繁琐、耗时长,还极易出错。
越来越多的用户
https://insights.digitalmediasolutions.com/articles/digital-mobile-dominate
为解决这一问题,我们很高兴地推出用于智能视频重构的开放源代码框架 —— AutoFlip。AutoFlip 构建在 MediaPipe 框架之上,用户可以使用流水线开发和处理时间序列多模态数据。
AutoFlip
https://github.com/google/mediapipe/blob/master/mediapipe/docs/autoflip.mdMediaPipe
https://mediapipe.dev/
首先,AutoFlip 会选取一段视频(随意拍摄或经过专业编辑)和目标维度(横向、正方形、纵向等)作为输入内容,然后通过分析视频内容,制定最佳的追踪和裁剪策略,最后输出一个具有所需宽高比且时长相同的视频。

左图:原始视频 (16:9)。中图:使用标准中央剪裁重构后的视频 (9:16)。右图:使用 AutoFlip 重构后的视频 (9:16)。通过检测兴趣主题,AutoFlip 能够避免裁剪掉重要的视觉内容
AutoFlip 介绍
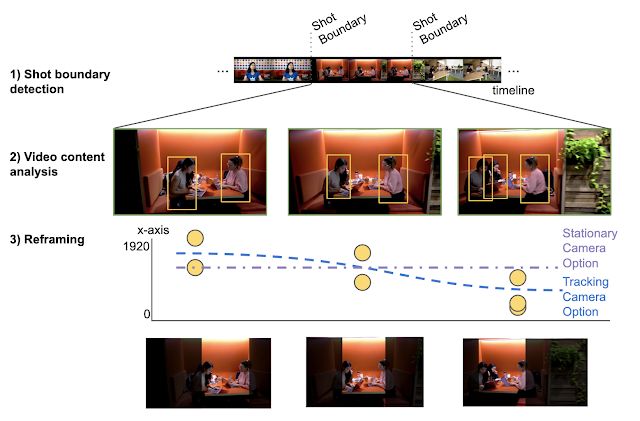
AutoFlip 利用基于机器学习的最前沿 (SOTA) 对象检测和追踪技术,智能理解视频内容,提供了全自动智能视频重构解决方案。AutoFlip 通过检测表示场景变化的构图变化,将不同场景分开进行处理。在每个镜头中,用户可以使用视频分析功能识别重点内容,然后通过选择针对该内容进行过优化的相机模式和路径,对场景进行重构。
场景或镜头是未经剪切(或跳跃)片段的连续视频序列。为检测镜头变化,AutoFlip 通过计算每一帧的颜色直方图,并与前面的帧进行比较。如果发现帧的颜色分布以不同的频率,而非以平滑时间窗口发生变化,AutoFlip 就会发出镜头变化的提示信号。AutoFlip 对视频进行缓冲,直到完成对该场景的缓冲,然后做出裁剪决定,以优化对整个场景的裁剪与重构。
我们利用基于深度学习的对象检测模型,在视频帧中找出有趣、突出的内容。这些内容通常包括人和动物,但根据应用场景的不同,也会检测其他元素,如文本和广告 logo、体育运动中的球和动作等。
我们通过 MediaPipe 将人脸和物体检测模型集成到 AutoFlip 中,MediaPipe 在 CPU 上使用 TensorFlow Lite。这种结构使 AutoFlip 能够扩展,因此开发者可以为不同用例和视频内容轻松添加新的检测算法。每种对象类型有一个权重值,定义了对象的相对重要性,权重越高对计算相机路径时的影响就越大。
人脸
https://github.com/google/mediapipe/blob/master/mediapipe/docs/face_detection_desktop.md物体检测模型
https://github.com/google/mediapipe/blob/master/mediapipe/docs/object_detection_desktop.mdTensorFlow Lite
https://www.tensorflow.org/lite

左图:运动镜头中的人物检测。右图:两个人脸框(“核心”和“全部”人脸界标)。在较窄的肖像裁剪中,通常只能容纳核心界标框
确定每一帧中的感兴趣的目标之后,就可以对如何重构新视图中的内容做出逻辑判断了。AutoFlip 会自动在 静态、 摇摄 或 追踪 三种方式中选择一个最优的重构策略,具体取决于对象在场景中的行为方式(比如来回移动或静止)。在 静态 模式中,重构的相机窗口固定在一个位置上,使观众能够在该场景中的大部分区域看到重要内容。这种模式可以有效模仿专业的电影摄影,即把相机安装在固定的三脚架上,或在后期进行稳定化处理。而在其他情况下,最好 摇动 相机,匀速移动窗口。追踪 模式可对在帧内移动的目标进行持续稳定的追踪。
AutoFlip 根据算法在这三种重构策略中做出的选择,为每一帧确定一个最佳裁剪窗口,同时最大限度地保留有趣的内容。追踪场景中的焦点目标对象时,边界框通常会在帧与帧之间表现出相当大的抖动,因此不足以定义裁剪窗口。相反,我们通过欧几里得范数优化流程来调整每一帧的窗口,在这个过程中最大限度地减小平稳(低阶多项式)相机路径与边界框之间的残差。

上排:在帧与帧之间跟随边界框产生的相机路径;下排:使用欧几里得范数路径构造最终生成的平滑相机路径;左列:包含移动的对象,需相机追踪路径的场景;右列:对象靠近同一位置的场景;静态相机覆盖整个场景的内容
AutoFlip 的配置图表用于显示实现 最佳效果 或 进行重构所需 的设置。若无法完全覆盖必要区域(如当这些区域在帧内的分布过于分散时),流水线将通过应用 信箱模式(Letterboxing) 效果,自动切换到 低干预策略 :对图像进行填充,令所有必要区域全部在帧内显示。如果检测到背景为纯色,流水线将以此颜色进行无缝填充;否则将进行模糊处理。

AutoFlip 案例
我们很高兴能为开发者和电影制作人提供这款工具,在发挥设计创意时减少障碍,并实现视频编辑自动化。随着人们观看视频内容设备种类愈发多样,让各种视频格式能适应各种屏幕比例变得越来越重要。AutoFlip 提供智能、自动化和自适应的视频重构解决方案:无论从纵向变为横向,还是从横向变为纵向,甚至是进行从 4:3 变为 16:9 这样的微小调整,AutoFlip 都能满足您的需求。

未来计划
与其他机器学习算法一样,当检测目标与相关视频意图的能力提升时,AutoFlip 也可相应提升,比如采访中的受访者识别或卡通中的动画人物的面孔检测。此外,当输入视频在屏幕边缘出现重要信息重叠(如文本或 logo)的情况时,会出现一个常见问题,即这些重叠部分常被剪掉。通过结合文本 / logo 检测和图像修复技术,我们希望未来的 AutoFlip 版本可以重新定位前景目标,以便更好地适应新的宽高比。最后,在需要填充的情况下,Deep Uncrop 技术可以提供更出色的扩展功能,将可视区域扩展至更大范围。
Deep Uncrop
http://openaccess.thecvf.com/content_ICCV_2019/papers/Teterwak_Boundless_Generative_Adversarial_Networks_for_Image_Extension_ICCV_2019_paper.pdf
目前,Google 内部正致力于改进 AutoFlip,我们希望开放源代码社区的开发者和电影制作人也能参与进来,贡献出自己的一份力量。
致谢
我们在此感谢为 Autoflip 贡献力量的各位同事:Alexander Panagopoulos、Jenny Jin、Brian Mulford、Yuan Zhang、Alex Chen、Xue Yang、Mickey Wang、Justin Parra、Hartwig Adam、Jingbin Wang 和 Weilong Yang;感谢为我们提供开源帮助的 MediaPipe 团队成员:Jiuqiang Tang、Tyler Mullen、Mogan Shieh、Ming Guang Yong 和 Chuo-Ling Chang。
