谷歌使用机器学习进行自主布局布线,证实可提高开发效率并降低成本
以下文章来源于大国重器高端电子元器件 ,作者大国重器 天地
大国重器高端电子元器件
小器件,大战略!首个专注世界军用电子元器件的权威智库,全面覆盖政策、管理、技术、产业和市场,望与圈内同仁携手,为我国军用电子元器件突破发展瓶颈、自主可控集聚智慧。本公号以专业、首发、原创、悦读为运维原则,打造军用电子元器件圈内第一信息平台。

发展机缘
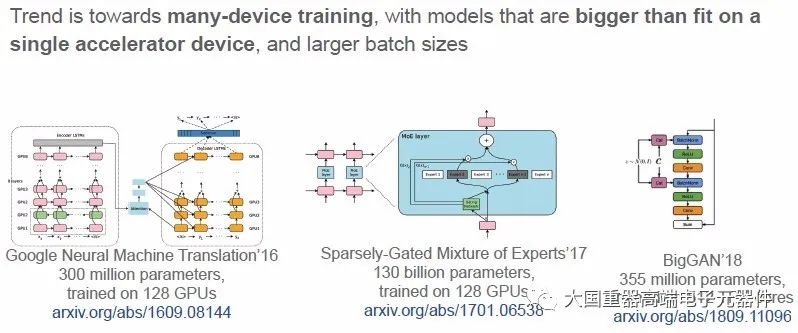
面临挑战
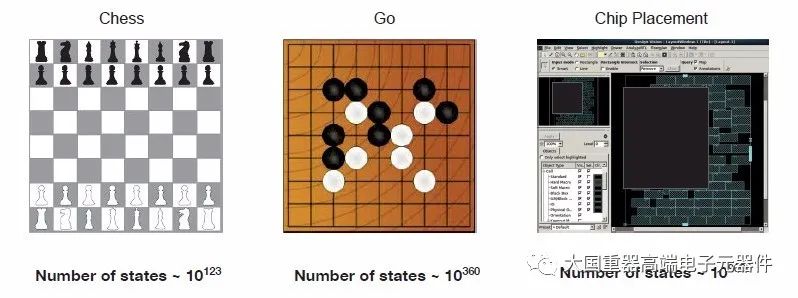
主要成果

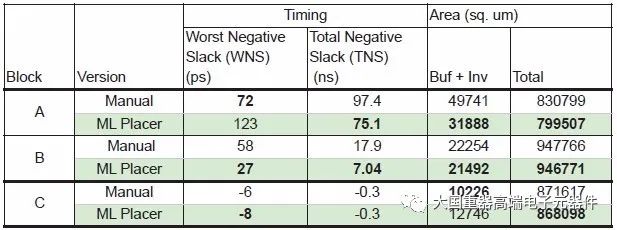

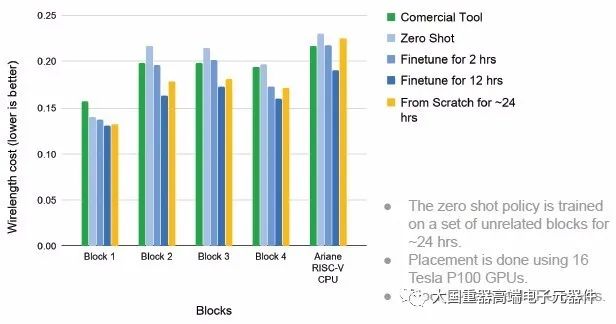
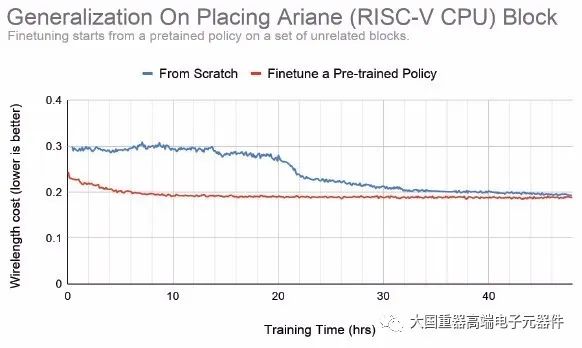
显著优势
下步发展
拭目以待
福利


以下文章来源于大国重器高端电子元器件 ,作者大国重器 天地
小器件,大战略!首个专注世界军用电子元器件的权威智库,全面覆盖政策、管理、技术、产业和市场,望与圈内同仁携手,为我国军用电子元器件突破发展瓶颈、自主可控集聚智慧。本公号以专业、首发、原创、悦读为运维原则,打造军用电子元器件圈内第一信息平台。
发展机缘
面临挑战
主要成果
显著优势
下步发展
拭目以待
福利