万字长文综述:文本增强技术的研究进展及应用实践
本文经机器之心(微信公众号:almosthuman2014)授权转载 禁止二次转载
作者:李渔
样本少、分布不均衡,如何让训练的模型性能更优越?文本增强技术算得上一个不错的办法。本文介绍了熵简科技联合创始人李渔的一篇关于自然语言处理领域中文本增强技术的论文,重点探讨了近两年来常用的五类文本增强技术路径以及对应的代表性技术。
目 录
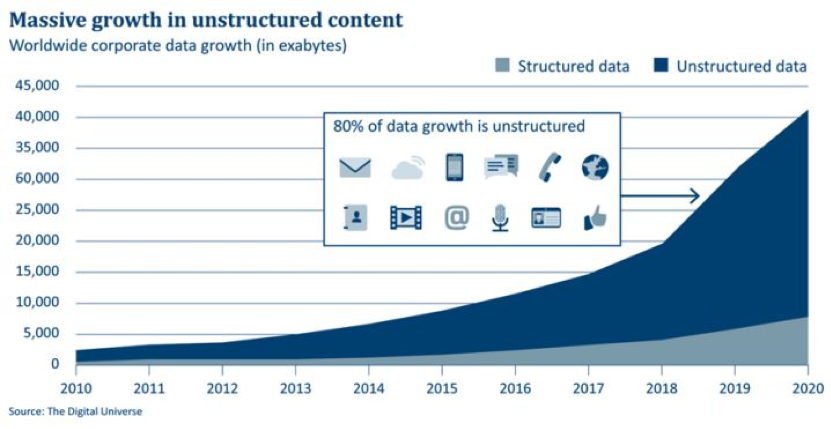
1 为什么要了解文本增强技术
2. 典型技术方案
原始文本为:文本数据增强技术在自然语言处理中属于基础性技术;
翻译为日语:テキストデータ拡張技術は、自然言語処理の基本的な技術です;
日语再翻译为英语:Text data extension technology is a basic technology of natural language processing;
英语再翻译回中文:文本数据扩展技术是自然语言处理的基本技术;
原始文本:今天天气很好。
同义词替换 (SR):今天天气不错。(好 替换为 不错)
随机插入 (RI):今天不错天气很好。(插入 不错)
随机交换 (RS):今天很好天气。(很好 和 天气交换位置)
随机删除 (RD):今天天气好。(删除 很)

原始数据:【xxx 月报】特点:(1)紧跟物业市场动向,观测各地政策变化;(2)补充公告内容,跟踪项目中标和收并购。行业:「物业服务」入产业结构鼓励类目,中消协发布调查报告。行业类别:房地产
原始数据:公司有望成为「慢病管理+血糖监测+药物治疗」三位一体的糖尿病管理大平台企业。维持预测 2001-2002 年 EPS 为 0.2/0.34/0.21 元,同比增长 11/11/11%,现价对应 01~21 年 PE 为 10/10/10 倍,维持「增持」评级。行业类别:医药
原始数据:公司实现飞机起降架次 6 万次,同比增长 4.8%,旅客吞吐量 800 万人次,同比增长 4.5%,货邮吞吐量 32.2 万吨,同比增长 0.8%。行业类别:交通运输
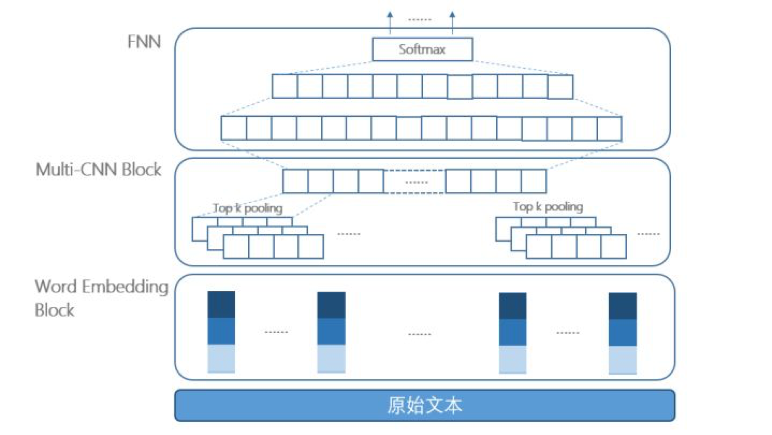
卷积运算本质上是局部区域的加权运算,应用在本模型中可以有效提取文本的局部特征及局部语序信息。通过不同长度卷积核的组合,还可以同时提到取文本中不同距离上的特征信息。
池化运算一方面可以实现降维功能,并保证输出向量的长度不受文本长度变化的影响,另一方面池化操作还可以保证平移不变性,从而使得文本的关键特征不受到位置的影响。
词向量层的语料训练样本:由各门户网站的新闻语料、各机构发布的研报、百度百科等文本构成的数亿规模的语料;
整体模型的训练样本:包含上述的训练集中的 900 条语料、利用数据增强技术对 900 条原始语料扩充之后获得的语料;
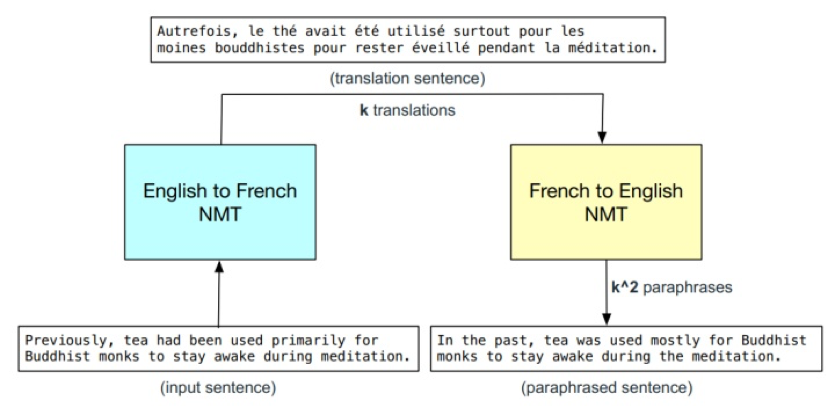
方案一:利用开源的 中-英、英-中 两个翻译模型实现回译变换,在输出选择时,我们同时尝试了随机采样和 beam search 两种方式,以实现多倍数的文本增强;
方案二:利用 google 翻译,选用多个中间语种做过渡,以同样实现多倍数的文本增强。如,中-日-英-中,中-法-德-中 等。
原始文本:公司有望成为「慢病管理+血糖监测+药物治疗」三位一体的糖尿病管理大平台企业。维持预测 2001-2002 年 EPS 为 0.2/0.34/0.21 元,同比增长 11/11/11%,现价对应 01~21 年 PE 为 10/10/10 倍,维持「增持」评级。
增强后文本:该公司有望成为具有「慢病管理+血糖监测+药物治疗」的三位一体糖尿病管理平台公司。维持预测,2001 年至 2002 年每股收益为 0.2 / 0.34 / 0.21 元,比上年增长 11/11/11%。当前价格是对应于 01-21 PE 的 10/10/10 倍,维持「增持」评级。
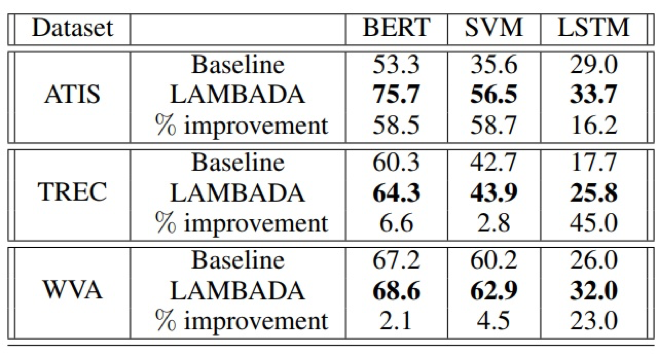
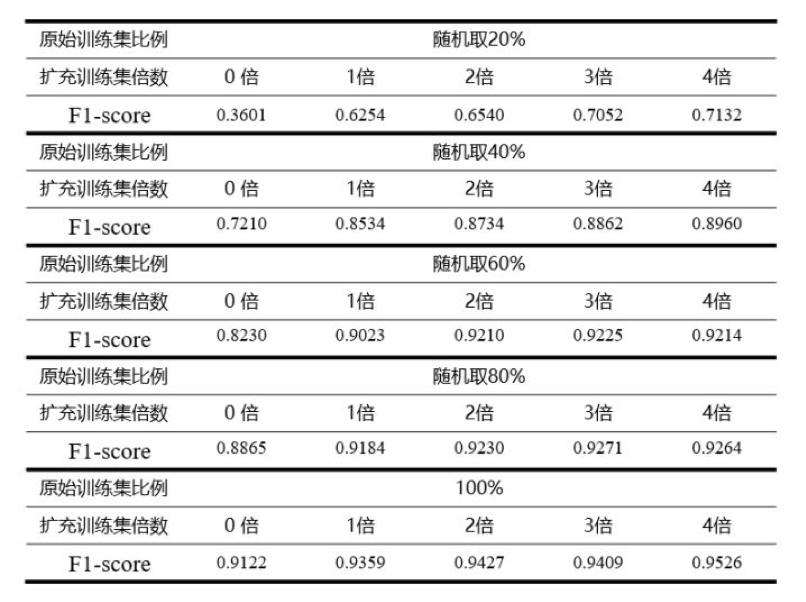
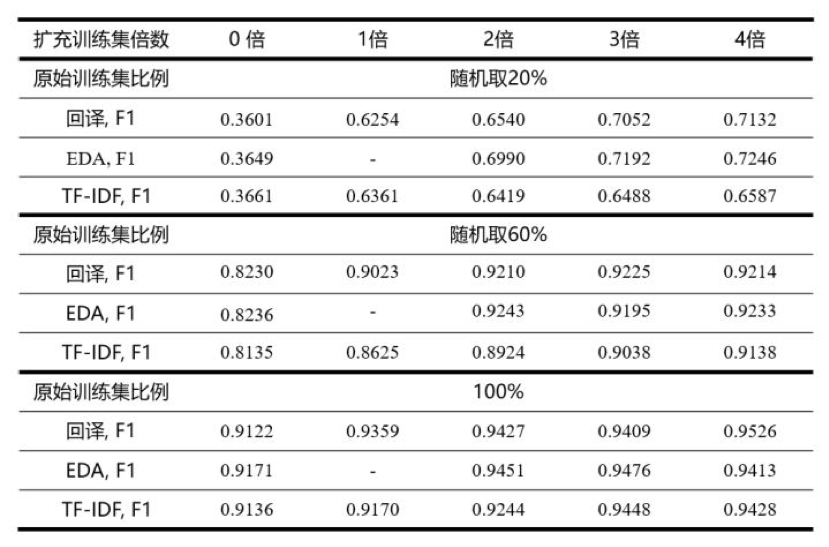
步骤一:对训练集中的 900 条样本,运用 回译 技术进行文本增强操作,共增强 4 倍(因此利用了 4 种不同的中间语种);
步骤二:从原始训练集的 900 条样本中随机取 20%、40%、60%、80% 和 100 % 比例的数据,然后混合进对应的增强后数据(包括 0 倍,即不做增强),在不同混合倍数下进行模型训练,并记录最优实验结果;
步骤三:重复步骤二的实验三次,以三次实验的平均值作为最终结果。
原始数据:【周报(12.02-12.08)】:拼多多上线火车票业务,海南离岛购物免税新政三周年销售近 200 亿。(行业类别:餐饮旅游)
同义词替换:【周报(12.02 亿 12.08,】:拼多多上线火车票业务)海南离岛购物免税新政三周年销售近 200 亿。
随机插入:【周报(12.02</s>-12.08)】:拼革新多多上线火车票业务,海南离岛购物免税新政三周年销售近 200 亿。
随机交换:【服务 200(12.02 近 12.08)】:拼多多上线火车票业务,海南离岛购物免税新政三周年销售-周报亿。
随机删除:【周报(12.02-12.08)】:拼多多上线火车票,海南离岛购物免税新政三周年销售近 200。
随即交换句子位置:海南离岛购物免税新政三周年销售近 200 亿,【周报(12.02-12.08)】:拼多多上线火车票业务。
步骤一:对训练集中的 900 条样本,运用 五种 EDA 技术进行文本增强操作,每中操作进行 2 倍,3 倍,4 倍扩充,即每条样本对应扩充 10 倍,15 倍,20 倍;
步骤二、三:与回译实验相同;
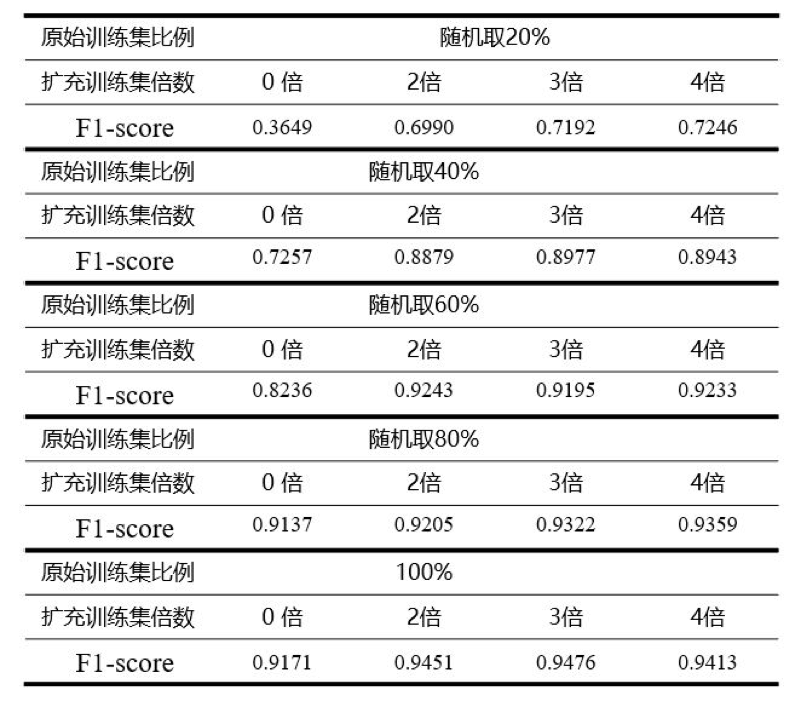
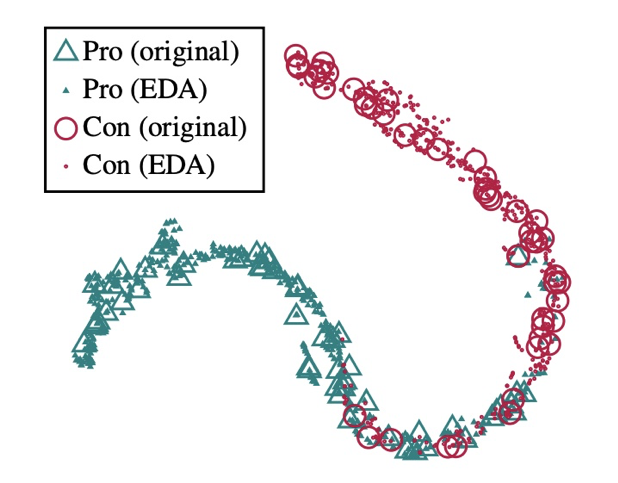
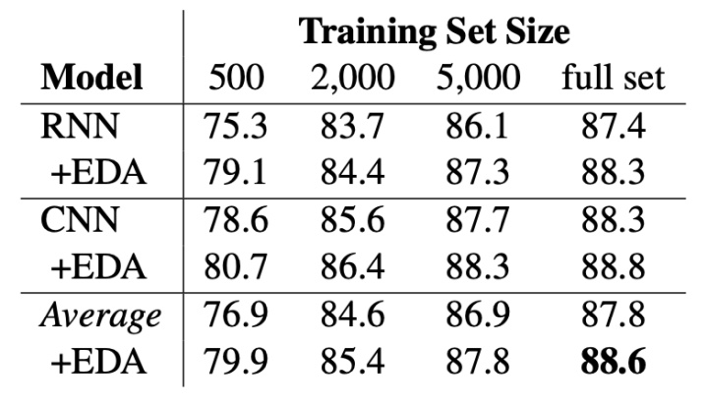
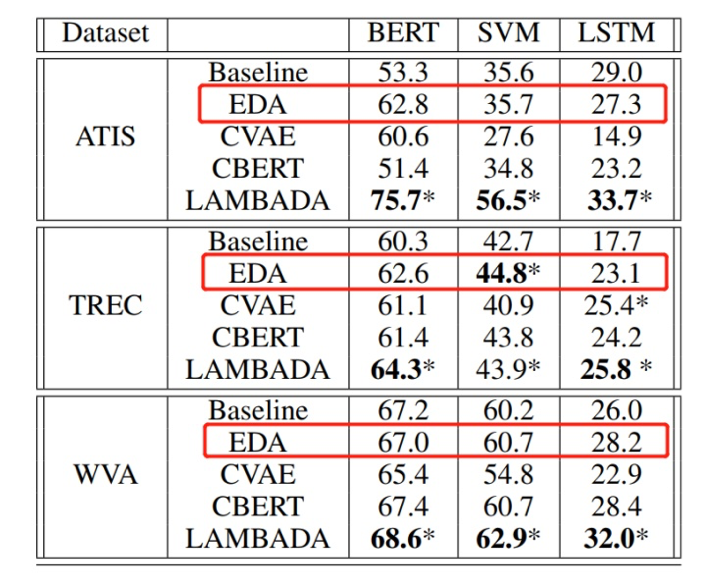
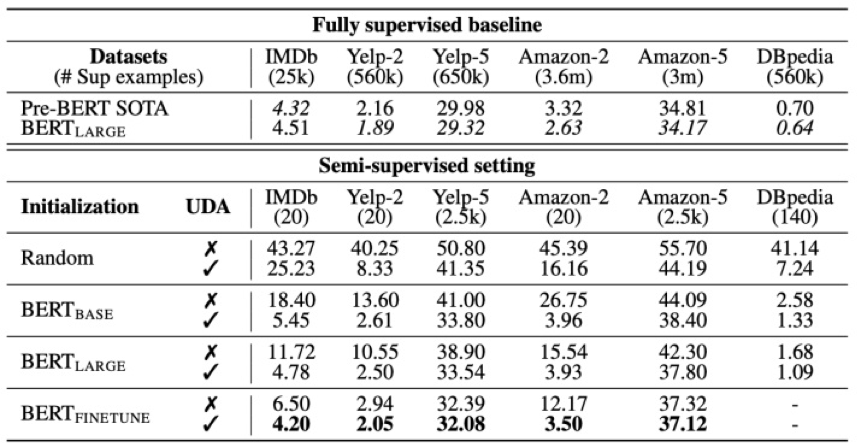
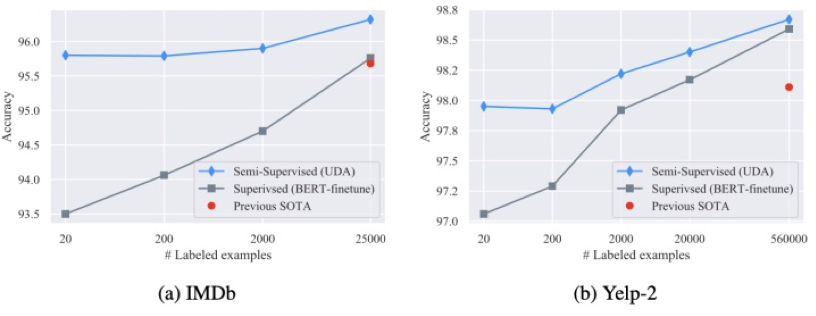
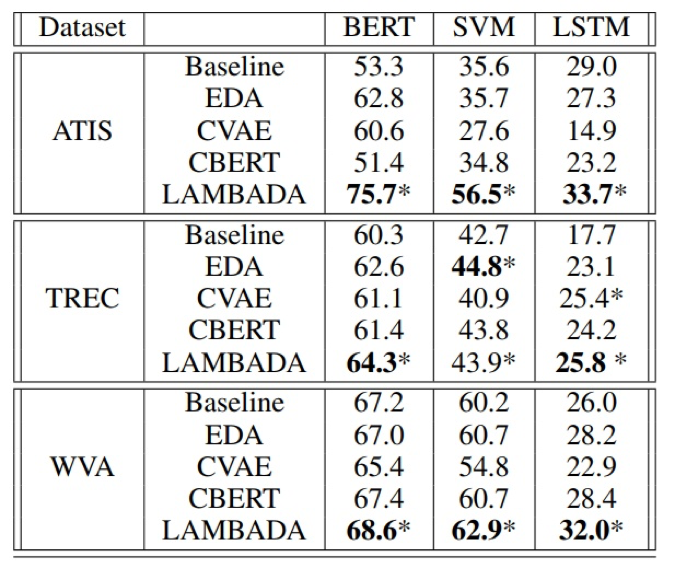
第一,无论是在仅有 180 条样本的场景下,还是在完整数据集下,EDA 的运用可以给模型带来 2~30 个百分点不等的提升,数量越小,相对于 baseline 的提升越明显;
第二,运用 EDA 技术时,较好的增强倍数在 3 倍左右,数据量小时,可适当选择更大的增强倍数;
第三,从表中可以看出,数据集仅为 60% 时,采用 EDA 进行 2 倍扩充时,模型的表现就已经超过了在完全数据集下不用 EDA 技术的模型,这也充分说明了 EDA 的杠杆作用。同时,这一现象,也在 EDA 的原始论文中提到过 [4];
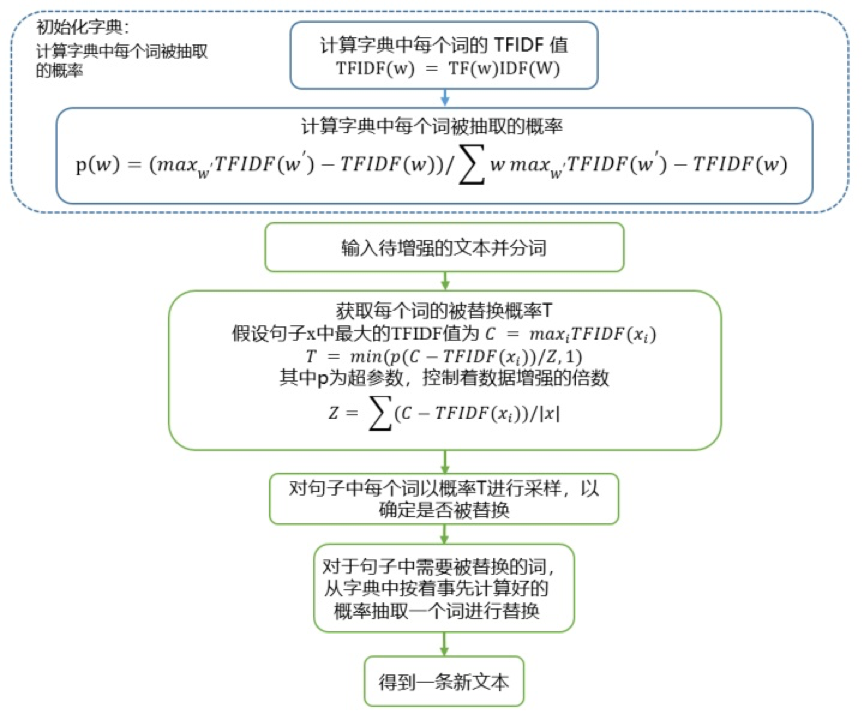
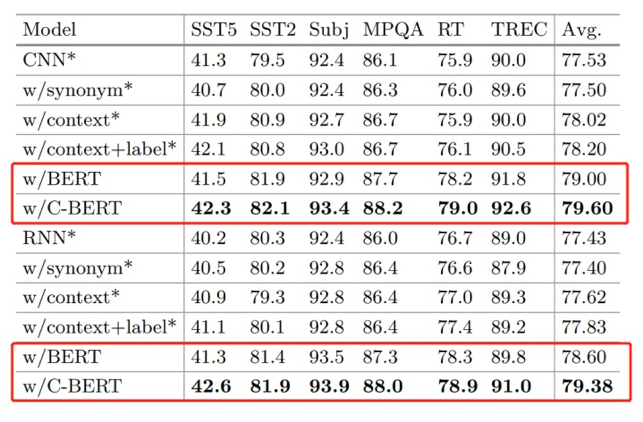
增强后样本 (扩充系数 p=0.1):齐格勒酒店调研纪要,经济型酒店相比中探访酒店各细目下滑多一点专攻入住率、单价均有下滑,幅度较之前差不多。近期中端酒店同店 revpar 数据是持平,整体受新开店略有下降。
增强后样本 (扩充系数 p=0.3):201912 锦江酒店每位纪要,经济型酒店相比中高端酒店各指标下滑多一点,入住率陶冶华有下滑,幅度较之前差不多。近期中端酒店同店 revpar 诺思是于长,整体受新町村蓝黛略有下降。
增强后样本 (扩充系数 p=0.1):大秦铁路点评:电煤需求回升或受港口卸车影响,8 月运量同比 2%。新闻/公告:大秦铁路公布 9 月份运营马勒,公司核心资产大秦线 9 月份完成货物运输。
增强后样本 (扩充系数 p=0.3):大秦铁路助益:项下不断回升或西递专属卸车影响,8 月运量同比 2%。偿债/公告。大秦铁路形制 10 月份运营数据,滑石封航 cerner 大秦线 9 月份完成招聘。
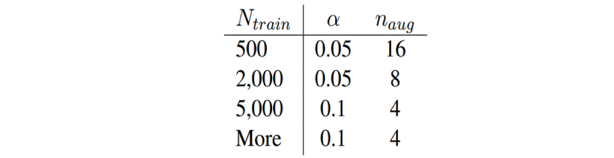
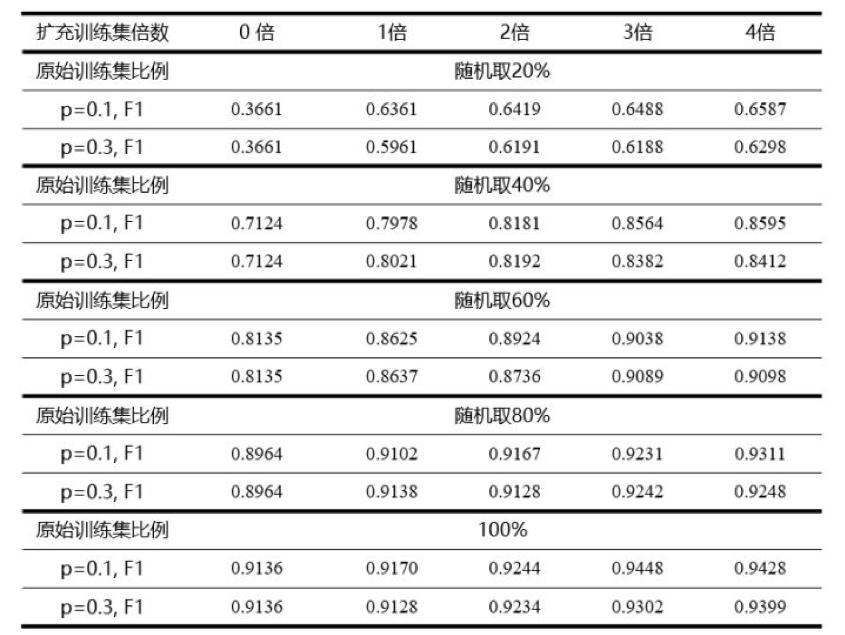
步骤一:将数据集按照之前的比例划分为 训练集 和 测试集,并对训练集进行文本增强操作,替换比例分别为 5%,10%,15%,20%,25%,30%;
步骤二、三:与回译实验相同;
Wei, Jason W., and Kai Zou. "Eda: Easy data augmentation techniques for boosting performance on text classification tasks." arXiv preprint arXiv:1901.11196 (2019).
Anaby-Tavor, Ateret, et al. "Not Enough Data? Deep Learning to the Rescue!." arXiv preprint arXiv:1911.03118 (2019).
Hu, Zhiting, et al. "Learning Data Manipulation for Augmentation and Weighting." Advances in Neural Information Processing Systems. 2019.
Wang, William Yang, and Diyi Yang. "That』s so annoying!!!: A lexical and frame-semantic embedding based data augmentation approach to automatic categorization of annoying behaviors using# petpeeve tweets." Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015.
Chawla, Nitesh V., et al. "SMOTE: synthetic minority over-sampling technique." Journal of artificial intelligence research16 (2002): 321-357.
Xie, Qizhe, et al. "Unsupervised data augmentation." arXiv preprint arXiv:1904.12848 (2019).
Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. Deep learning. MIT press, 2016.
Sennrich, Rico, Barry Haddow, and Alexandra Birch. "Improving neural machine translation models with monolingual data." arXiv preprint arXiv:1511.06709 (2015).
Edunov, Sergey, et al. "Understanding back-translation at scale." arXiv preprint arXiv:1808.09381 (2018).
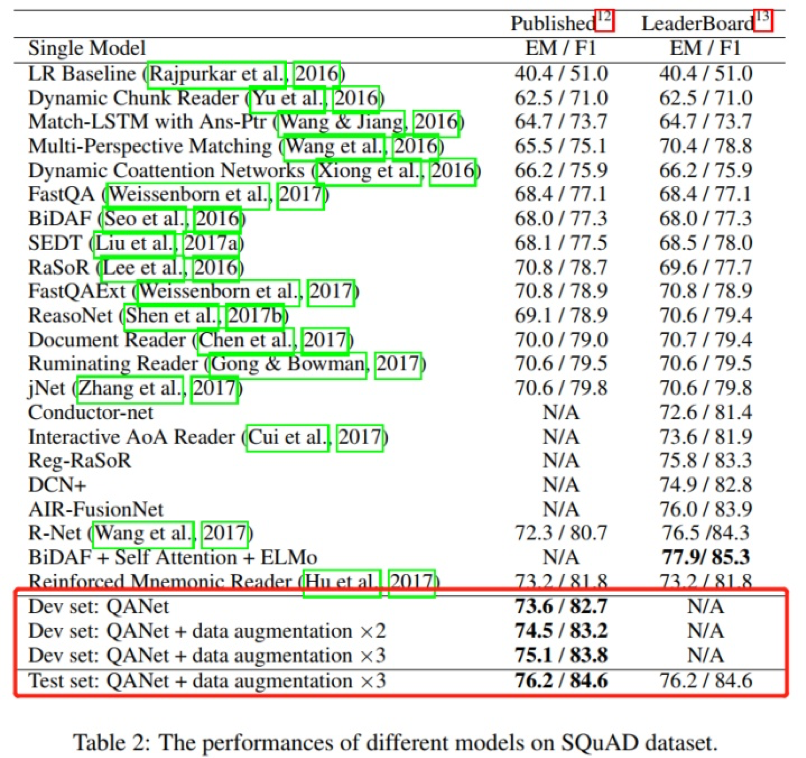
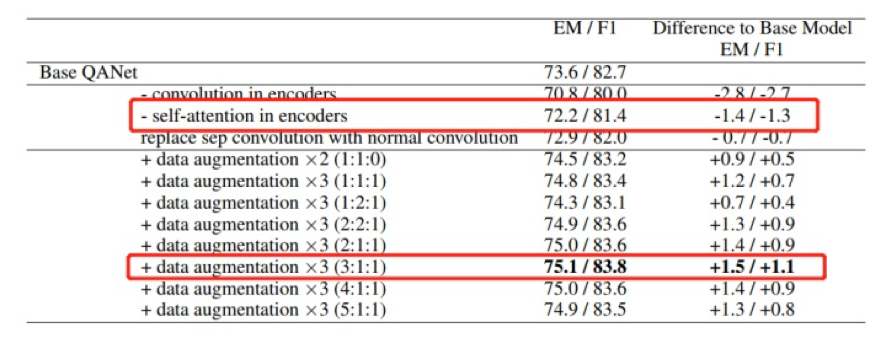
Yu, Adams Wei, et al. "Qanet: Combining local convolution with global self-attention for reading comprehension." arXiv preprint arXiv:1804.09541 (2018).
Wei, Jason W., and Kai Zou. "Eda: Easy data augmentation techniques for boosting performance on text classification tasks." arXiv preprint arXiv:1901.11196 (2019).
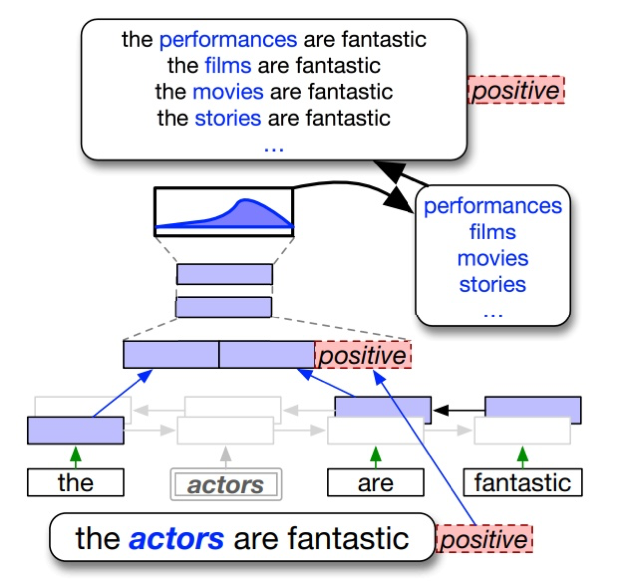
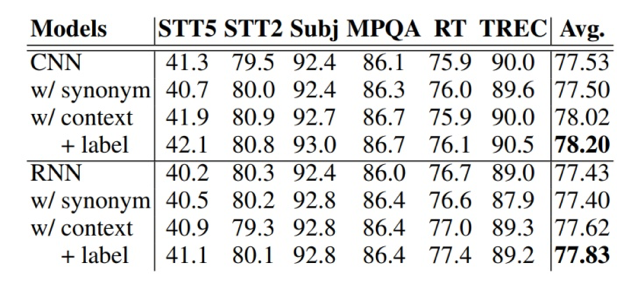
Kobayashi, Sosuke. "Contextual augmentation: Data augmentation by words with paradigmatic relations." arXiv preprint arXiv:1805.06201 (2018).
Wu, Xing, et al. "Conditional BERT contextual augmentation." International Conference on Computational Science. Springer, Cham, 2019.
Liu, Ting, et al. "Generating and exploiting large-scale pseudo training data for zero pronoun resolution." arXiv preprint arXiv:1606.01603 (2016).
Hou, Yutai, et al. "Sequence-to-sequence data augmentation for dialogue language understanding." arXiv preprint arXiv:1807.01554 (2018).
Dong, Li, et al. "Learning to paraphrase for question answering." arXiv preprint arXiv:1708.06022 (2017).
Radford, Alec, et al. "Improving language understanding by generative pre-training." URL https://s3-us-west-2. amazonaws. com/openai-assets/researchcovers/languageunsupervised/language understanding paper. pdf (2018).
Radford, Alec, et al. "Language models are unsupervised multitask learners." OpenAI Blog 1.8 (2019): 9.
Hu, Zhiting, et al. "Toward controlled generation of text." Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017.
Guu, Kelvin, et al. "Generating sentences by editing prototypes." Transactions of the Association for Computational Linguistics 6 (2018): 437-450.
Kim, Yoon. "Convolutional neural networks for sentence classification." arXiv preprint arXiv:1408.5882 (2014).
Strubell, Emma, et al. "Fast and accurate entity recognition with iterated dilated convolutions." arXiv preprint arXiv:1702.02098 (2017).
Tang, Gongbo, et al. "Why self-attention? a targeted evaluation of neural machine translation architectures." arXiv preprint arXiv:1808.08946 (2018).
推荐阅读 GitHub标星2.4W!五分钟带你搞定Bash脚本使用技巧 EfficientNet 解析:卷积神经网络模型尺度变换的反思 【图解机器学习】人人都能懂的算法原理 真·干货!标星1.3k的网红深度学习教程,由浅入深,适合深度学习新手 我,斯坦福AI读博,李飞飞是师娘,5年5篇顶会论文,依然一度抑郁怀疑人生 下载 | 621页《 Linux 命令行与 shell 脚本编程大全 》
