图形学+深度学习:来看下神经渲染完成的神仙操作!

From: EUROGRAPHICS 2020 编译:T.R
语义图像合成与操控
在语义图像合成方面,目前主要基于条件生成目标,将用户指定的语义图映射为逼真的图像。用户输入还包括了颜色、草图、纹理等形式。从pix2pix等方法开始,研究人员们就开始对场景和图像的生成进行深入的探索,并不断提高生成图像的分辨率与细节,同时从静态图像向动态视频的语义操控扩展。

于是为解决这些问题,研究人员们提出了非条件GAN来作为神经图像先验,同时通过生成结果与原始图像的融合来得到输出结果。此外,包括自动编码器等多种内部结果的使用和后处理的有效应用也使得图像编辑取得了良好的效果。


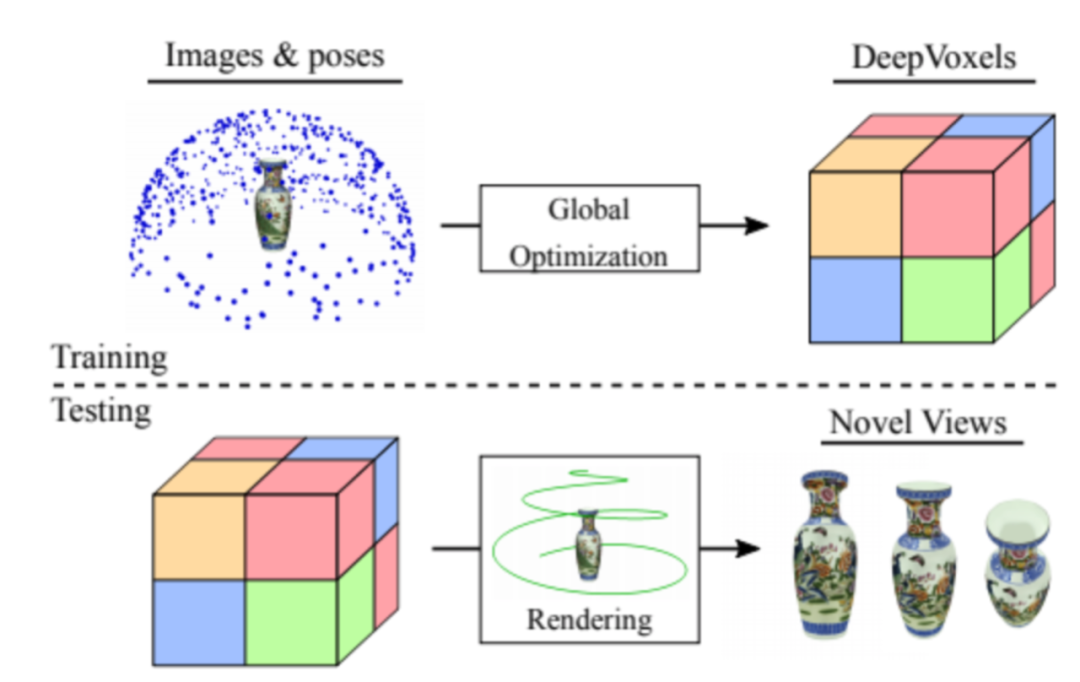
目标和场景的新视角合成
下图显示了神经渲染从大规模网络图像中重建3D模型的结果。模型被渲染为了深度、颜色和语义标签等缓存中,渲染器将这些缓存转换为了多种不同的场景结果。


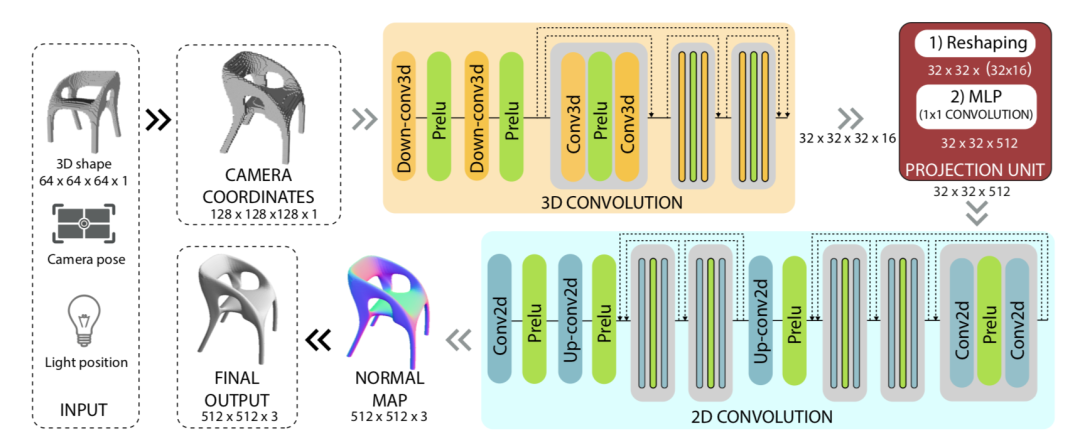
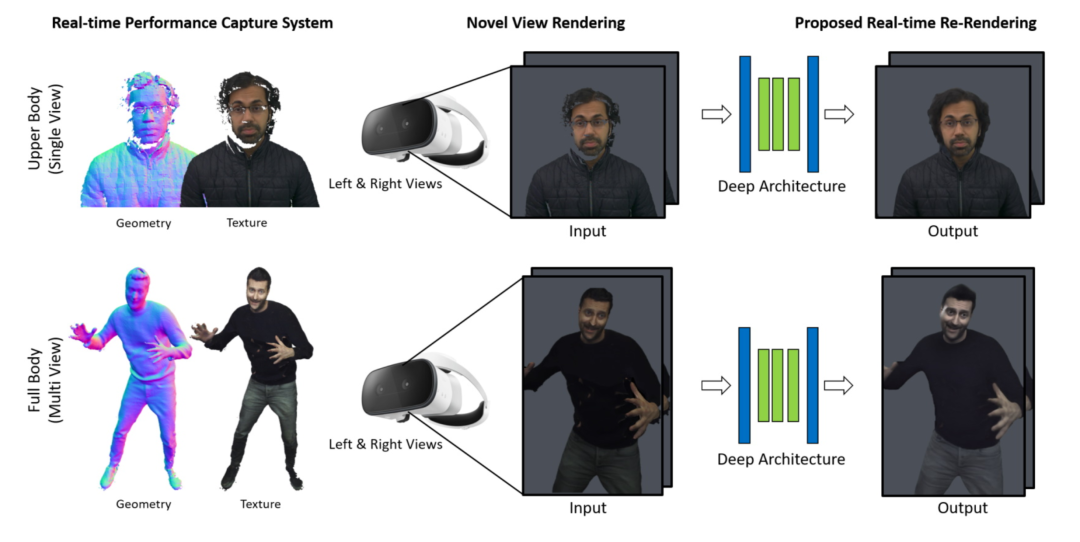
自由视点视频合成

学习重新打光的神经渲染
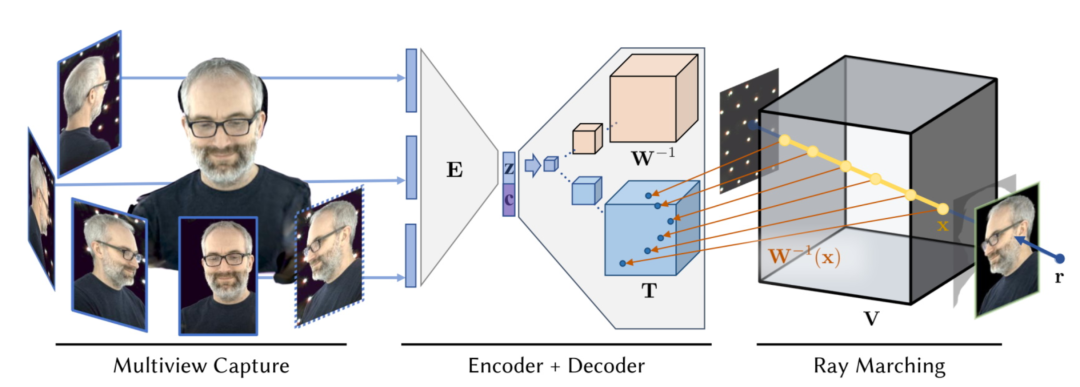
此种方法的实现原理很好理解:通过神经渲染技术,研究者能让系统从少数几张图像中学习出场景的光照方向和重光照函数。在此基础上,人们也可利用多视角来学习场景几何构成以实现更好的重光照。


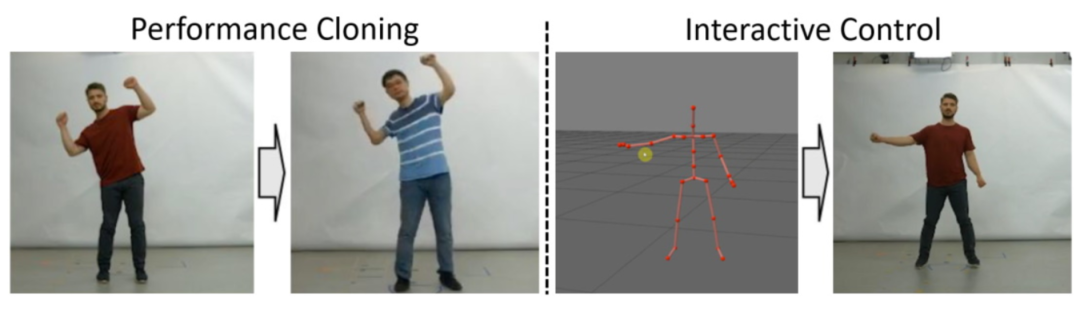
人体重建渲染
其中一个有趣的应用是修改视频中人说话内容的同时,将人物的口型也进行相应的修改。下图显示了Text-based Editing of Talking-head Video,视频中说话人的文字被改变,对应的嘴形也被改变并渲染出了逼真的结果。


虽然神经渲染技术在各个方面已经取得了巨大的突破,成为了图形学领域和计算机视觉、机器学习领域交融共生的新兴方向,但其目前还面临着泛化性、规模化、可编辑性以及多模态数据场景表达能力的限制,还有很大的发展空间。相信随着技术的进步,会有更多通用、易用、高效稳定的方法被提出,让神经渲染达到与现代图形学一样的适用范围的同时,还能激发其深度学习的强大能力。
如果想要了解更多详细信息、理论方法和参考文献,请参看论文:
https://arxiv.org/pdf/2004.03805.pdf


来扫我呀
关于我门
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
将门创新服务专注于使创新的技术落地于真正的应用场景,激活和实现全新的商业价值,服务于行业领先企业和技术创新型创业公司。
将门技术社群专注于帮助技术创新型的创业公司提供来自产、学、研、创领域的核心技术专家的技术分享和学习内容,使创新成为持续的核心竞争力。
将门创投基金专注于投资通过技术创新激活商业场景,实现商业价值的初创企业,关注技术领域包括机器智能、物联网、自然人机交互、企业计算。在近四年的时间里,将门创投基金已经投资了包括量化派、码隆科技、禾赛科技、宽拓科技、杉数科技、迪英加科技等数十家具有高成长潜力的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: bp@thejiangmen.com


将门创投
让创新获得认可!
微信:thejiangmen
bp@thejiangmen.com
点击“❀在看”,让更多朋友们看到吧~