飞腾携手比特大陆,本土CPU加速切入AI深度学习领域
摩尔芯闻
今天
来源:内容来自「飞腾PHYTIUM」,谢谢。
近日,
飞腾 FT-2000/4
和
FT-2000+/64
两款处理器与
比特大陆
算丰
AI
计算模组 SM5
、
AI
计算加速卡 SC5
、
AI
计算加速卡 SC5+
、
AI
计算加速卡 SC5H
四款
人工智能
产品
以及
BMNNSDK2
人工智能
软件
开发包
完成产品
兼容性
互认证,
比特大陆
算丰系列
人工智能
产品成为与飞腾
CPU
完成互认证的国内首批
AI
组件。这四款人工智能产品在飞腾 FT-2000/4 和 FT-2000+/64 两款处理器上均能顺利安装,在以
飞腾处理器
为核心的服务器和 PC 主机
设备
上均能稳定运行。这标志着
比特大陆
算丰系列
人工智能
产品可以完全支持飞腾国产处理器,飞腾
CPU
应用加速切入人工智能
深度学习
领域,双方将合力共建国产
AI
生态圈,推进产业智能化升级。
算丰系列
人工智能
产品(SM5/SC5/SC5+)是以
比特大陆
自研芯片 BM1684 为核心,在此基础上研发出不同形态的
人工智能
加速产品。其中,算丰 SC 系列产品主要部署在云端计算集群中,用以视频处理和分析;SM 系列产品为高密度计算模块,在云端和边缘端拥有广泛的应用场景,其主要角色是作为
CPU
的协处理器完成高并行度的深度卷积
神经网络
推理计算;BMNNSDK2-V2
软件
开发包作为统一的工具链和系统软件平台,支持众多
深度学习
框架在飞腾+算丰的硬件平台上顺畅运行。
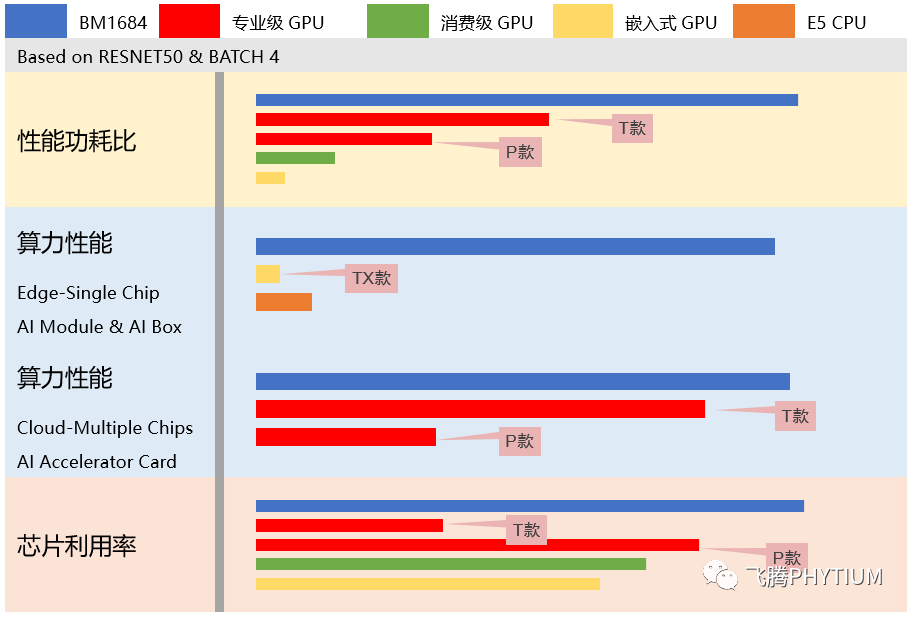
算丰 BM1684 在飞腾服务器上运行的性能指标
以此次完成飞腾适配认证的算丰 SC5+ 高性能云端
AI
加速卡为例,作为三年内连续推出的第三代 AI 加速卡,其能够在 75W 的标准 PCIE
接口
下提供高达 105.6T 的峰值算力以及 3000 fps 的视频解码能力,同时提供视频前后处理的硬件加速能力,且无需外接供电;具备算力强劲、利用率高、全流程加速能力强大、易用易维护等多项优势。该产品
设计
架构先进,总体芯片利用率和算力功耗比均居于业内最前列,同等算力规格可获得 1.5-2 倍的实际性能;在性能满足视频分析业务需求的前提下,与飞腾服务器搭配使用,可实现
人脸识别
、视频结构化等
AI
云端计算业务的单路成本最优。
飞腾-
比特大陆
测试
视频
与
比特大陆
4 款 A 产品完成适配的飞腾 FT-2000+/64 处理器是飞腾面向高性能服务器领域的产品。该款处理器
设计
了数据亲和的多核处理器体系架构,突破了高效乱序超标量流水线、层次化片上并行存储结构、多级异构片上互连网络、高可用处理器设计等关键技术,实测性能达到了国际主流服务器
CPU
同等水平,填补了国产高端通用 CPU 领域的空白,是中国首款自主
设计
的 64 核通用 CPU,也是国际上首款兼容 ARMv8 指令集的 64 核通用 CPU。
飞腾处理器
作为国产高性能、
低功耗
通用计算处理器的代表,和算丰系列
人工智能
产品搭配,可以高效地实现大型视频分析。飞腾处理器负责处理复杂且密集的业务逻辑,算丰系列人工智能产品负责高并行度密集计算的视频图像解析,二者 “ 双核联动、比翼双飞 ”,组合成一个协同度高、性能强悍的系统。今后,双方将在
人脸识别
、视频结构化、城市大脑、智能安防等领域合作发力,为行业客户提供国产化的高质量产品及解决方案,携手共建国产
AI
生态圈,共同服务 “ 新基建 ”。
了解更多
BM1684 是
比特大陆
算丰系列第三代
人工智能
加速芯片,每个芯片包含 1 颗
ARM Cortex-A5
3 8 Core 2.3
GHz
CPU
、64 个 550MHz 的
NPU
计算单元以及 VPU/JPU 等编解码单元。其主要功能包括视频图像的编解码、
CV
基础
算法
加速,以及最核心的深度
神经网络
算法
推理加速,理论算力可达 2.2TFP32/17.6TINT8/35.2TINT8(Winograd Enable)。作为一款为
AI
计算加速研发的
ASIC
芯片,BM1684 可以在高性能、
低功耗
的情况下完成图像解码、预处理、内容解析(
算法
推理)以及结果编码等过程。
比特大陆
第三代
人工智能
芯片:算丰BM1684
福利
摩尔精英
粉丝福利:半导体行业资料,免费下载
点击阅读原文,了解
摩尔精英
!
阅读原文
阅读
在看
已同步到看一看
写下你的想法
前往“发现”-“看一看”浏览“朋友在看”
前往看一看
看一看入口已关闭
在“设置”-“通用”-“发现页管理”打开“看一看”入口
我知道了
已发送
取消
发送到看一看
发送
飞腾携手比特大陆,本土CPU加速切入AI深度学习领域
最多200字,当前共
字
发送中