ISSCC 2020热门技术:Chiplet、5G和车用处理器
原创
Kevin Krewell
电子工程专辑
前天
在2020年国际固态电路研讨会(ISSCC)处理器分会现场,首先由
AMD
的两场演讲(这还是第一次)拉开了序幕。随后三星和联发科就各自最新的
5G
智能手机芯片分别发表了演讲,还有来自CEA技术公司的研究项目/概念
验证
(POC)
设计
、
德州仪器
(TI)的车用系统级芯片(
SoC
),以及
IBM
最新的Z系列大型主机处理器。
由于该会议主要聚焦于
电路设计
,每家公司仅重点介绍其处理器中一个或多个独特的电路
设计
特点。
ISSCC是半导体行业历史最悠久的技术会议之一,每年二月举办。参会者都是来自学术界和产业界的专家,大家共同探讨IC
电路设计
中的最新挑战。
今年的会议涵盖了一系列主题,包括
锁相环
、
低功耗
电路、
存储器
、
SerDes
、
DSP
和处理器
设计
等。特别值得一提的是,几家领先的芯片供应商参与了处理器分会场演讲,当然还有研究机构和学术界的一些研究项目演讲,全部都是围绕高密度芯片的设计。下面是处理器分会场上最有趣的精彩环节。
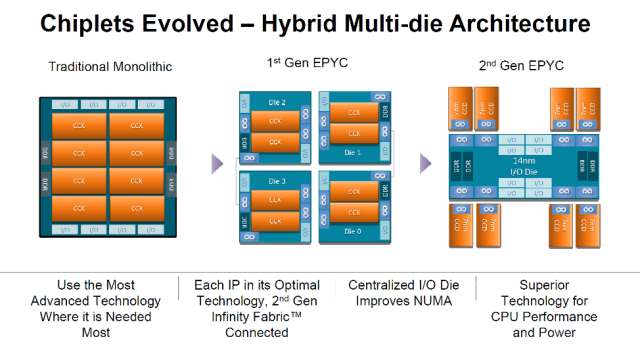
AMD Zen
2和EPYC
chiplet
(芯粒)
AMD
连续发表了两场演讲 ,首先谈论了其最新EPYC服务器处理器所采用的
Zen
2
CPU
内核
设计
,然后探讨了EPYC
chiplet
(芯粒)架构,
AMD
采用这种架构将64个
CPU
内核集成到一个小
封装
内,而没有造成一个大尺寸的裸片。这种芯粒
设计
也让AMD能够将三种裸片设计应用于众多产品和市场中。
在
Zen
2 现场演示PPT中,
AMD
演讲者介绍了使用
台积电
7nm
工艺
制造第一款x86处理器时所遇到的挑战。EPYC服务器处理器的
设计
目标是使一颗芯片中的
CPU
内核数量增加一倍,而且不能超出
芯片封装
插槽的功耗上限。此外,每个
CPU
内核的每周期指令执行性能要在SPECint2006基准上提升15%。此前关于
Zen
2 架构的变化已经有了很多论述。在此次ISSCC的演讲中,
AMD
着重讨论了
电路设计
方面的挑战。
AMD
的
设计
非常模块化,其基本单元包括:内含4个
CPU
内核的CPU模组(CCX)、L2和L3高速
缓存
,以及
Infinity Fabric
系统互连。利用这种4核
CPU
模组,
AMD
可以将
设计
范围从笔记本电脑(4-8核)扩展到服务器(高达64核)。即便增加了更多L3
缓存
,CCX模组的尺寸还是从上一代的44mm2缩减至
Zen
2架构的31.3mm2。
7nm
工艺
制程
设计
需要添加更多的金属层。结果,金属层布线规则发生了变化,设计迹线从10.5减少到6条。迹线的减少带来了挑战(高度降低且驱动强度也下降),但又带来了许多好处,比如
漏电
流降低、每周期
电容
减少9%,并缩减了裸片尺寸。
AMD
采用了多种
设计
技术,如
时钟
整形,并采用了五种不同的
触发器
设计
,这对关键的时序环路很重要。为了获得更好的性能,设计人员还将3%的功率预算转移到了组合逻辑上。通过这一系列电路优化设计 ,AMD可以将
时钟
速率提高到4.7
GHz
,并在
时钟
速率接近原
Zen
内核时降低了工作电压。
AMD
的第二场演讲介绍了针对
Zen
2服务器产品做出的
chiplet
策略改变。
AMD
获得的主要优势之一是,仅流片三个裸片,就能打造出能够满足多个市场需求的产品。当芯片分散在整个
封装
中时,使用芯粒还
能带
来
散热
的好处。
AMD
的目标是将每个插槽的芯片性能大幅提升,其结果是第二代EPYC处理器的
CPU
内核数量增加了一倍。这使得AMD有望每隔2.5年将性能提升一倍(SPECint 2006)。新的EPYC处理器也改善了内存延迟。由于使用了芯粒架构,AMD得以成功打造出更具竞争力的服务器芯片,若按照以往在单芯片上实现的方法根本是不可行也不经济的,因为它很容易就会超出64内核的上限。
AMD
还通过使用更小的芯粒优化了成本结构,提高了裸片
良率
。AMD将昂贵的
7纳米
工艺
用于内核
缓存
裸片(CCD),而将
DRAM
和
PCIe
逻辑转移到由
GlobalFoundries
制造的
12nm
I/O裸片上。每个CCD由两个CCX模组(一个CCX模组包含四个
Zen
2内核),以及L2和L3
缓存
组成,其中86%的CCX专用于
CPU
和L3
缓存
。每个CCD就是一个微型
SoC
,还需要在裸片上集成
电源管理
、Infinity Fabric系统互连、
时钟
等。
要满足所有这些要求面临着许多挑战。由于存储控制器集中在一个独立芯片上来控制所有CCX模组,新的EPYC处理器的平均内存延迟得到了优化。但是,最佳情况下的延迟仍然需要脱离CCD来访问内存。结果,
AMD
的
设计
重点转向减少Infinity Fabric的延迟,最终最佳情况下的延迟只有4纳秒。
由于
AMD
决定保持EPYC
封装
尺寸和
引脚
不变,因此当裸片数量从第一代EPYC的4个增加到第二代EPYC的9个时,就需要紧密的芯片/封装协同
设计
。布线路径非常紧密,需要较深的CCD芯粒下的布线信号到达离中心I/O裸片较远的CCD裸片。
ISSCC的其它演讲讨论也涉及了这种
电路设计
问题,就是在处理器承受重
负载
时需要补偿内部
压降
的电路。
AMD
为此采用了电流分流器,即额外电流,来抑制
压降
,还可以延长
时钟
。相同的低压差(
LDO
)
设计
能够实现单个内核的线性调节,并根据每个内核的功能调整电压以节省能耗。
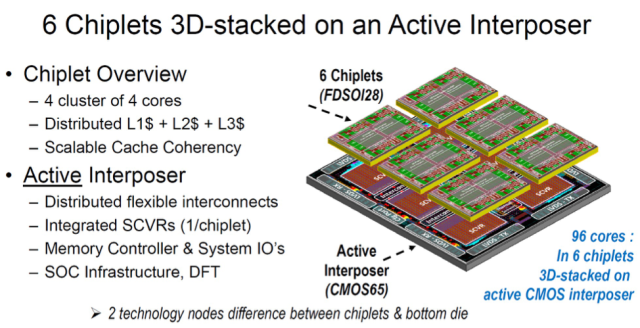
概念
验证
(POC)处理器集成96个内核和一个有源内插器
在此次会议中亮相的还有一款尚未量产的96核处理器芯片,同样也采用了芯粒
设计
。但区别在于,
AMD
使用带有专用I/O裸片的
多芯片模块
,而这颗96核芯片则使用整合I/O逻辑的有源
硅
内插器(interposer)。
该
设计
包含6个芯粒,集成了96个内核,其运算能力达到220 GOPS。它由CEA-
Leti
设计
,
意法半导体
制造。其目的是为了
验证
双裸片
设计
的概念,即芯粒和有源内插器(active interposer)。虽然这种设计使用的是同质芯粒,但未来的设计可能使用异质处理单元。与
AMD
EPYC的
设计
一样,CEA的目标是,在单个裸片处理能力不足的情况下,添加更多的处理单元。该芯片的一个潜在应用是
自动驾驶
,这类应用通常需求数百GOPS的处理能力。
采用有源内插器就可以从处理单元中卸载那些能够工作于旧的
工艺
节点的许多功能模块,其中包括
电源管理
、内存
接口
和I/O。对于这种特殊
设计
,CEA采用带有2D网格的分布式互连。内插器上的互连采用混合设计,即短距离用无源信道,而长距离用有源信道。该设计还使用一种创新的异步QDI逻辑,与片上
路由器
的异步网络进行通信。
处理单元芯粒采用带有体偏的
FDSOI
28nm LPLV制程
工艺
,而有源内插器则采用65 nm工艺。该芯片使用较老的工艺节点,其目标是展示其自身的
设计
与制造方式 。芯粒使用传统的标准裸片
测试
技术进行测试,但只有当所有单元都组装完成后才测试有源内插器。进入量产后,由于会采用更先进的工艺节点,制造流程可能会有所不同。
三星和联发科的7 nm
5G
手机芯片
大会展示的两款
5G
手机
SOC
分别来自联发科(
MediaTek
)和三星(
Samsung
),两者都专注于针对
Arm
big.LITTLE架构的处理器内核混合
设计
问题。此外,两者都探讨了处理单元在重
负载
下的内部
压降
检测问题。
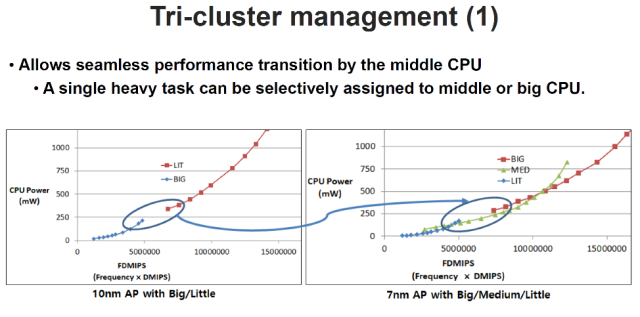
首先演讲的是三星,他们选择构建一组三集群
CPU
内核,而非
Arm
的big.LITTLE提供的双集群架构。在这种三集群架构中,有两个是Arm授权的内核,但性能最高的内核则是由三星自己根据Arm架构
许可
而
设计
的,即两个M4内核。双M4内核包含一个单独的3 MB L3高速
缓存
,对标
Intel
i5性能级别。
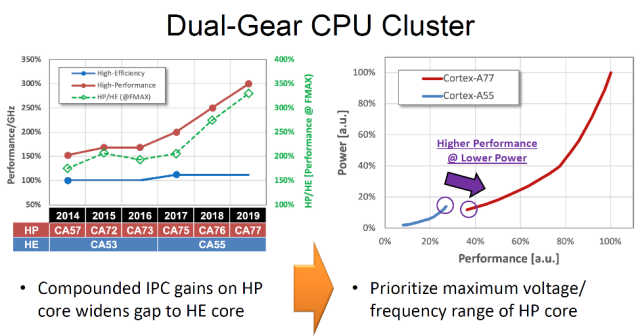
在中等功耗/性能范围内,三星使用
Arm
Cortex-A75内核。而高效能的“小”内核则是大名鼎鼎的Cortex-A55。三星M4内核与Cortex-A55内核在功耗/性能上的差距太大,因此三星增加了Cortex-A75内核来弥补这一差距。三星还添加了一个具有1024
MAC
的神经处理单元,但没有提供更多细节。
压降
在高性能处理器中是一个问题。若通过维持高供电电压来增加过多保护带,那么功耗就会比较高。在一个更高效的标称电压下,当某个特别耗电的单元(如运行高分辨率游戏的
GPU
)处于
负载
状态时,内部
电阻
下降会导致内部电压下降到规格要求以下。
SOC
厂商会
设计
专用电路来检测这些
压降
,并采取措施来缓解这个问题。他们的方法是延长
时钟
以减慢电路运行速度,并通过有效降低时钟速度来降
低功耗
。三星使用的
环形
振荡器
电路可以根据电压的变化改变速度。
振荡器
配置一个
计数器
与阈值进行比较,在
时钟
管理单元(CMU)中设置一个标志,检测到
压降
时就使时钟速度减半。
而联发科则采用另一种方法来选择
CPU
内核,它坚持采用
Arm
big.LITTLE 方案,联发科称之为双齿轮
设计
。联发科使用新推出的Cortex-A77
CPU
,用作实现较高性能的大核。联发科还指出,Cortex-A55的小核并没有跟上性能核心的发展。他们没有增加中等性能的内核,而是努力将A77的电压范围扩大到更低的速度。三星只有两个性能内核,联发科有四个A77内核。四个A77和四个A55内核共享一个中等大小的2 MB L3
缓存
。
为解决
压降
问题,联发科最初的做法是在裸片(
电容
)上设置一个可以提供瞬时电流的存储
电荷
,但这样增加了宝贵的裸片尺寸。最终,他们决定采用
时钟
延伸来节省裸片空间。
联发科的最大改变是选择使用锁频环(FLL),而非
锁相环
(
PLL
)。FLL采用双
时钟
设计
,不会丢失时钟周期,但由于其允许
振荡器
随电压变化,因此
设计
的确定性较低。借助FLL电路,
联发科技
能够将最低电压Vmin提高约35mV,从而节省了约10%的功耗。联发科还为该芯片
设计
了一种新颖的
JTAG
解决方案,该方案带有一个
网关
TAP,可对
测试
电路进行分层访问。
联发科芯片还带有WiFi 6功能,支持
5G
独立组网模式(SA)和非独立组网模式(NSA)。该
CPU
芯片总尺寸只有9.4 mm2,内置的Cortex-A77内核可支持高达2.6
GHz
的
时钟
速度。该芯片还配有一个
Arm
Mali G-77九核
GPU
。
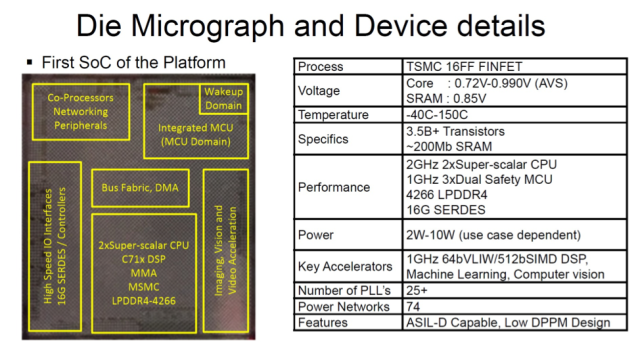
TI
汽车芯片
支持ASIL-D标准
TI的处理器是专为汽车应用而
设计
的。这款芯片属于Jacinto 7
SoC
系列,其
设计
融合了
Arm
Cortex处理器和TI自家的C71
DSP
。在这种
设计
中,TI在单芯片上创建了多个隔离域,这样芯片的某些部分能够达到ISO26262 ASIL-D的
安全
要求,而其它部分只要求符合ASIL-B标准。
唤醒域符合ASIL-D标准,带有一个专用Cortex-M处理器,用于引导管理、加密加速、可信执行环境和
安全
存储等。
MCU
域也达到了ASIL-D标准,配有一个Cortex-R处理器。它可以与对
安全
有严格要求的外围
设备
进行通信。
主域符合ASIL-B等级,配有Cortex-A处理器和TI的C71x
DSP
,以及用于音频处理和后向兼容支持的C66 DSP。C71x DSP采用64位、16发射超长指令集(VLIW)结构,可以支持4240个整数
MAC
/周期(8位)。TI为
ADAS
视觉
传感器
增加了许多视觉预处理功能,以增强传感器数据处理能力。此外,TI还增加了一个深度和运动感知加速器(DMPA),用于判断2D物体的运动,并在两幅图像之间建立矢量场。这些信息可用于评估物体穿过车辆路径的可能性。
IBM
Z系列大型机处理器集成更多内核
IBM
久负盛名的大型计算机还在不断进化。其最新的Z15处理器包括12个内核,无需热气管即可达到5.2
GHz
的
时钟
速度,因为
IBM
使用
水冷
技术来应对高功耗。当别家的处理器已经转向
7nm
制程时,IBM却继续使用
GlobalFoundries
久经考验的
14nm
工艺
,因为需要
嵌入式
DRAM
(eDRAM)。
IBM
Power
和Z系列处理器都依赖eDRAM在芯片上配置大容量
缓存
,但GlobalFoundries的
14nm
制程将是eDRAM扩展道路的终结。
尽管与前代产品处于同一
工艺
节点,但Z15
设计
者却在同一裸片区域内增加了两个额外的
CPU
内核,并将单线程性能提高了10%。缩小内核的大部分工作都依赖于更紧凑的
电路设计
。为进一步缩减裸片面积,他们从芯片上移除了调压器,并重新
设计
了eDRAM以提高密度。
除了添加了两个额外
CPU
内核之外,
设计
人员还增加了一个密码加速器和排序/归并加速器。芯片的最终面积是696mm2,与其前代产品基本一样。保持相似的裸片尺寸减少了热设计和机械设计的重新设计工作。
由于时间的限制,每场演讲只能涵盖芯片
设计
的几个要点。但是,此次会议让我们直观地体会到,以最
低功耗
达到最高性能的
设计
权衡事实上极其复杂。同时,我们还可以看出,随着新
工艺
节点的优势减弱(尤其是在成本方面),芯片
设计
的重心正转向架构强化和更高级的
电路设计
。
作者:Kevin Krewell
责编:Amy Guan
本文为EET
电子工程专辑
原创文章,如需转载,请留言
↓↓ 点击阅读原文 免费订阅杂志 ↓↓
阅读原文
阅读
在看
已同步到看一看
写下你的想法
前往“发现”-“看一看”浏览“朋友在看”
前往看一看
看一看入口已关闭
在“设置”-“通用”-“发现页管理”打开“看一看”入口
我知道了
已发送
取消
发送到看一看
发送
ISSCC 2020热门技术:Chiplet、5G和车用处理器
最多200字,当前共
字
发送中