谷歌T5预训练模型单次运行成本超130万美元?算力和金钱才是模型训练的王道
作者:Or Sharir、Barak Peleg、Yoav Shoham
机器之心编译
参与:杜伟、小舟
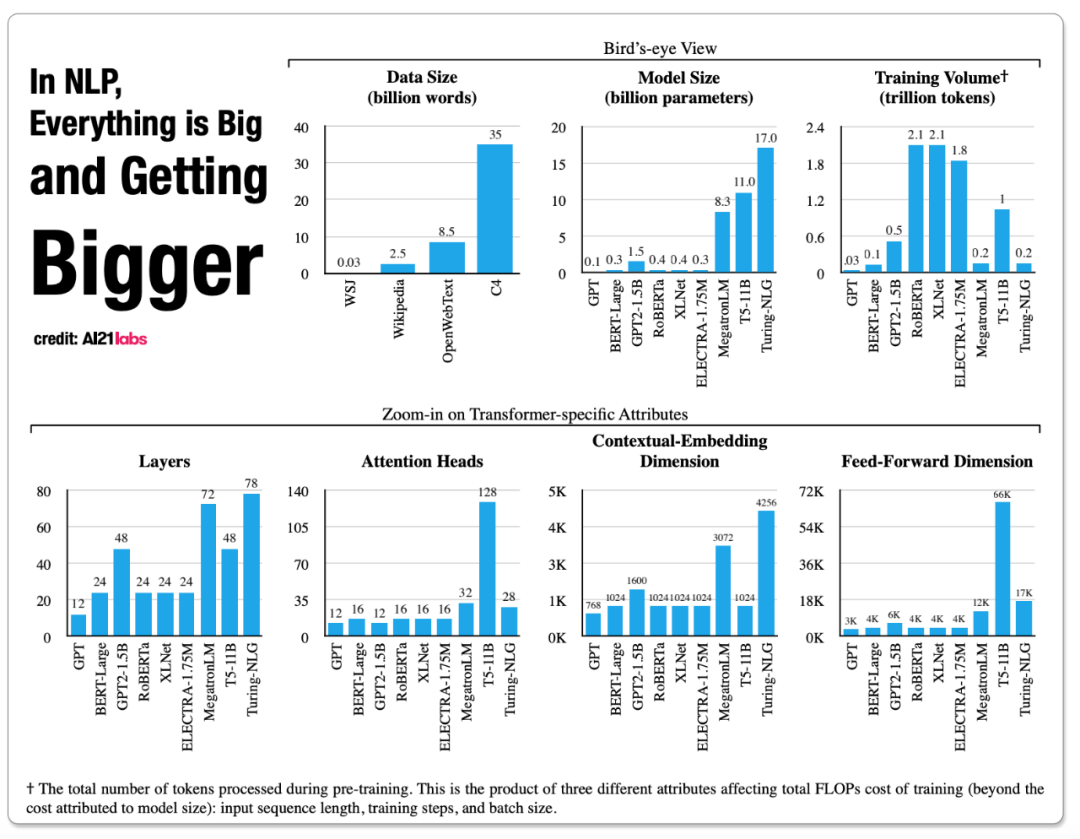
近年来,在自然语言处理领域,各种各样、各种规模的语言模型层出不穷,为该领域的进步提供了充足的动力。但欣喜之余,训练成本过于高昂的问题也随之出现。比如,BERT 训练成本 1.2 万美元、GPT-2 训练成本 4.3 万美元、XLNet 训练成本 6.1 万美元,等等。这就使得个人研究者和一些刚起步的初创公司难以负担。因此,在训练模型时了解成本的多少就变得很重要了,本文会为你提供一份参考性指南。
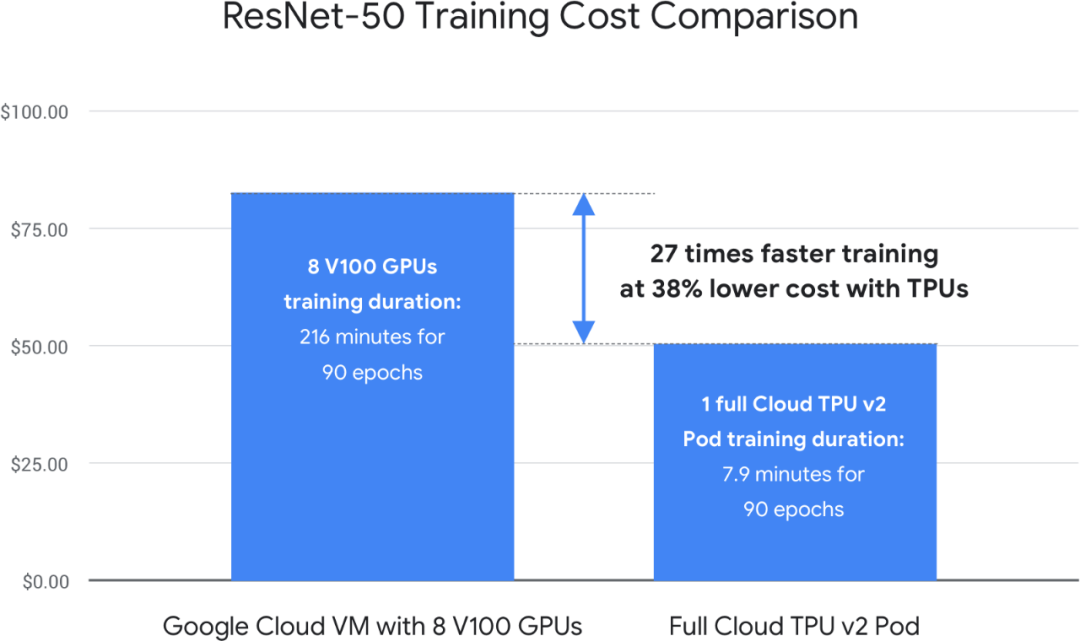
0.25 万美元-5 万美元(1.1 亿参数的模型);
1 万美元-20 万美元(2.4 亿参数的模型);
8 万美元-160 万美元(15 亿参数的模型)。
由于竞争加剧,原始计算的价格进一步降低。根据《New research from TSO Logic shows aws costs get lower every year》博客文章内容,自 2006 年推出以来,亚马逊网络服务(AWS)的价格下降了 65 倍以上,其中 2014 年至 2017 年,下降了 73%。预计面向人工智能的计算产品也会出现同样的趋势;
更高效的神经网络架构,部分受经济因素驱动,部分受环境因素驱动。比如,Reformer 结构使用启发式方法将 transformer 注意力机制的复杂度从二次(quadratic)降低到 O(n log n)。类似地,ALBERT 通过分解嵌入矩阵和分层权重共享,以更少的参数实现了更高的准确性。非常希望看到更多这样的情况;
结束 SOTA 比赛。社区中越来越多的人意识到,在诸多挑战数据集的排行榜上,大量的计算工作都投入到了排行榜顶端,这往往涉及许多次(有时甚至达到数千次)的运行,所有这些只是为了让单个实例幸运地获得第一名。当然,这种过拟合没有什么价值,我们希望看到更少这样的情况。
充分利用有用的数据。已经写成或将要写(有用的)的文本太多。有机会的话,我们将在博尔赫斯的 Universal Library 上进行训练;
有一种学派观点认为统计 ML 和神经网络一样有用且有必要,但目前还不充足,它会使人们走得更远。相反,如果沿着这种思路,则需要将结构化知识和象征性方法结合起来,这就变成了取决于大脑而不仅仅是取决于肌肉。这是研究者发现的一个观点。