自动化数据增强:实践、理论和新方向
选自Stanford AI Lab Blog
作者:Sharon Y. Li
机器之心编译
参与:Panda
对当今需要大量数据的机器学习模型而言,数据增强是一种具有显著价值的技术——既可用于缓解数据量不足的问题,也可用于提升模型的稳健性。常规的数据增强技术往往依赖相关领域的专家,耗时耗力成本高昂,因此研究者开始探索自动化数据增强技术。近日,斯坦福大学 AI 实验室(SAIL)发表了一篇题为《自动化数据增强:实践、理论和新方向》的博客文章,介绍了这一领域及近期的相关研究进展。

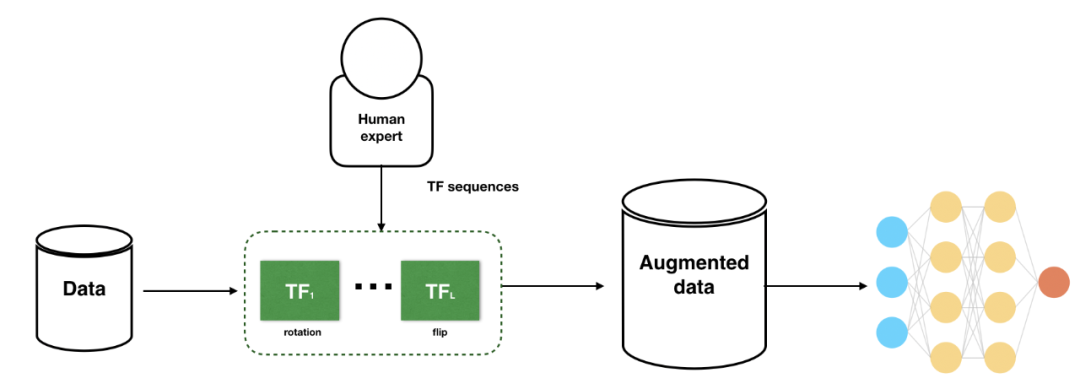
从人工设计到自动搜索算法:不同于执行次优的人工搜索,我们要如何设计可学习的算法来寻找优于人类设计的启发式方法的增强策略?
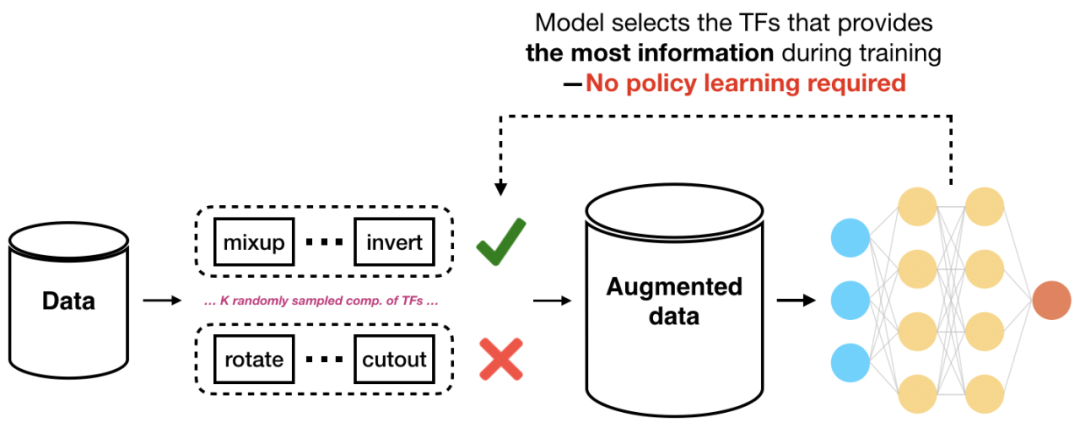
从实践到理论理解:尽管在实际应用中增强技术的设计研发进展速度很快,但由于缺乏分析工具,我们仍然难以理解这类技术的好处。该如何从理论上理解实践中使用的各种数据增强技术?
从粗粒度到细粒度的模型质量保证:尽管现有的大多数数据增强方法的关注重点都是提升模型的整体性能,但通常还需在更细的粒度上关注数据的关键子集。当模型在数据的重要子集上的预测结果不一致时,我们该如何利用数据增强来缩减在相关指标上的表现差距?

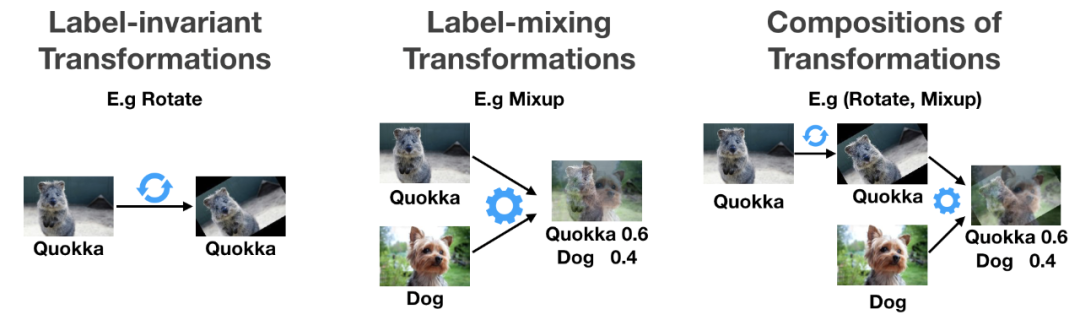

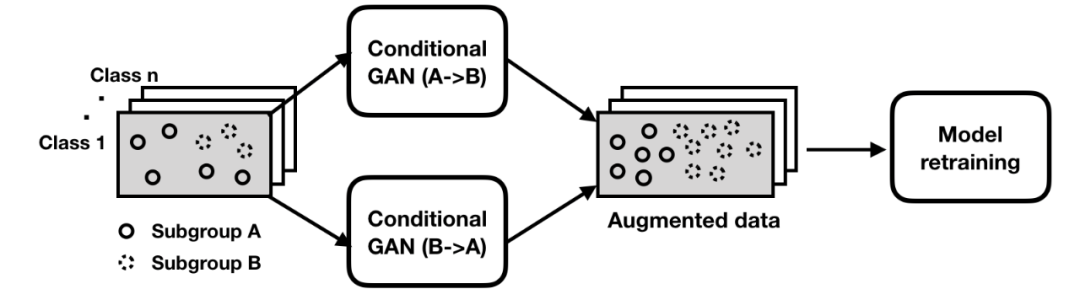
学习不同子分组之间的子分组间变换。这些变换是保留了类别的映射,允许从语义上改变数据点的子分组身份(比如,添加或移除彩色绷带)。
重新训练以使用增强后的数据修补模型,促进分类器稳健地应对数据的变化。