浅谈NVMe端到端数据保护
壹:什么是端到端数据保护

“静默错误”一词在存储界广为人知,特别是在做存储系统设计的时候,都会把”数据静默错误”的识别和修复作为一个重要的设计项考虑进去。那什么是数据静默错误呢?我们知道数据在传输、存储过程中,会经过多个软件模块、多种传输通道,而数据最终的存放又涉及到多种存储介质,其中任意一个环节发生错误都可能会导致数据错误。但是这种错误一般无法被立即检测出来,而是后续通过应用在访问数据过程中,才发现数据已经出错,在应用层体现出现数据不一致,这类错误我们称为静默数据破坏,即Silent Data Corruption。
数据产生静默数据错误的原因有很多种,总结起来可以归结为两类:硬件错误和软件BUG。
硬件错误:内存、CPU、硬盘、数据传输链路等,硬件错误产生的原因可能是受电磁辐射、温湿度、震动等环境的影响
软件bug:操作系统、驱动、以及应用程序等
本文主要讲述在HOST和NVME SSD硬盘间,NVME协议是怎么来实现DIF/DIX的数据传输以及怎么开启NVME硬盘的端到端数据保护的功能。
NVME协议称数据保护的数据块为元数据,DIF和DIX采用不同元数据传输方案。
DIX是data buffer和metadata buffer分离的一种模式,最后会在SSD端把它们拼接在一起。

DIF是data buffer和metadata buffer连接在一起传输的模式,如match下图所示,本文主要介绍DIF。


贰:T10 DIF

metadata 中一个重要的组成部分是PI(protection information)。PI的大小是8B,格式如下:
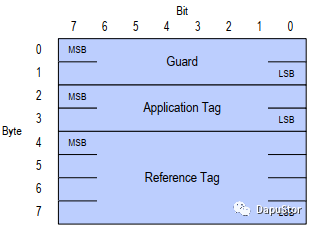
包括2B的Guard区域,2B的Application Tag和4B的Reference Tag,以上的3个参数的数据类型都是大端。
Guard:这个部分的构成是16-CRC,CRC的数据源是Guard之前的所有数据,包括data以及如果前面有metadata的话,metadata也包含在内。
Application Tag:是HOST自定义的数据,spec没有做特殊的说明。
Reference Tag:这个部分的构成主要是SLBA, 若是为0xFFFFFFFFF,则忽略此项的检查;
PI的类型有3种:Type1,Type2,Type3.
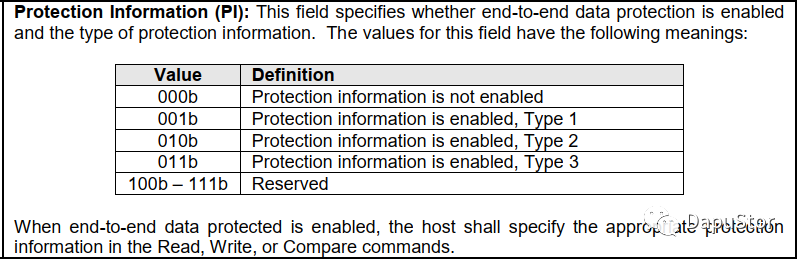
Type3只包含CRC保护,Type1,2包含CRC以及reference tag保护。Type1要求HOST设置EILBRT为slba的低四字节,主要是防止数据读错位置。Type2则对EILBRT没有要求,可设置成任何的值,但是一般也是设置成slba的低四字节。在一个命令中,数据的长度大概率是由多个lba构成,那么对于其他的lba对应的EILBRT应是前一个EILBRT+1的结果。

叁:如何使用DIF

1. Identify


首先通过identity CNS=0,获取到SSD支持的PI类型,以及支持的数据传输类型。如果MC的bit0为1则指出DIF,DPC的低3Bits为1分别表示支持type1,2,3。确定SSD支持DIF之后再选择一个MS大于等于8的LBAF。

2. Format
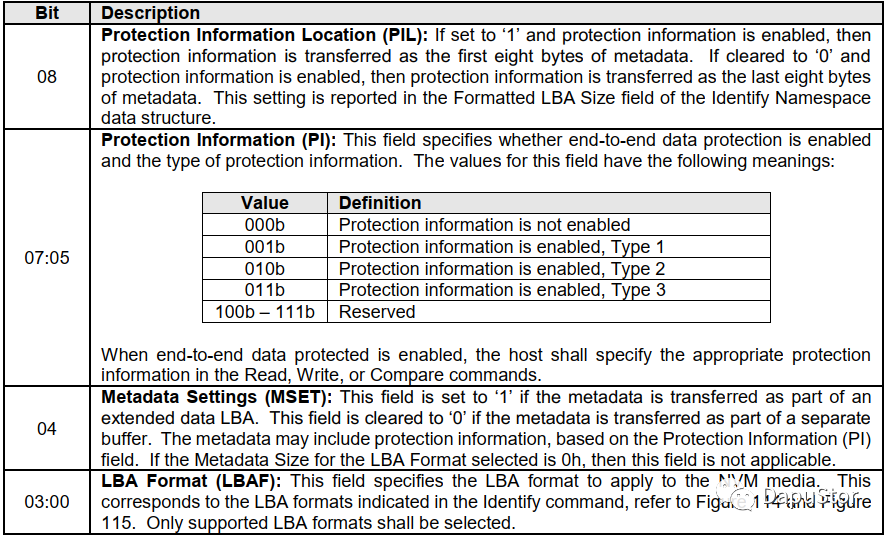
HOST通过nvme format命令,可以将指定的NS格式化成所需的格式。如下图所示:
PIL:指定PI在metadata中的位置,为1则是metadata的首8B,为0则是metadat 的尾8B.
PI:指定数据保护的类型。
MEST:指定metadata的传输方式,1为DIF, 0为DIX。
LBAF:则是指定的数据格式,包括lba的大小以及metadata的大小。
3. READ/WRITE
IO命令主要关注两个参数PRINFO和EILBRT/ILBRT.
EILBRT/ILBRT:这个参数的作用在于SSD将metadata中的reference tag与之进行对比。
PRINF的组成如下图所示:
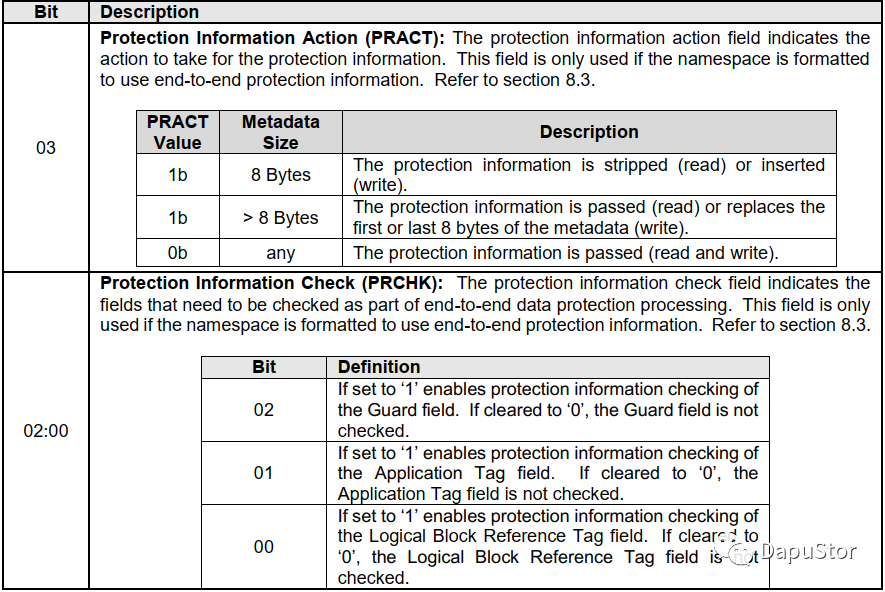
PRACT=0:
HOST生成PI,NVME驱动将调用t10-pi的接口,根据PI的类型,生成CRC以及reference tag。由于标准驱动不支持此功能,原因是在驱动层做数据的拷贝会拖慢内核的运行速度,所以需要开发者自行修改驱动来支持此功能,需要在nvme init iod的时候做dif remap。
Metadata size=8
当matedata的大小为8B时,那么metadata就是PI。
WRITE
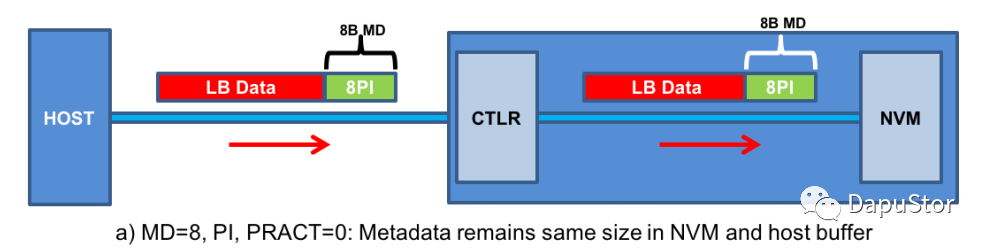
在这种场景下,SSD的主要行为是在收到数据后,根据HOST设置的PRCHK,然后对PI进行检查。若某一项没有通过检查则返回err,否则将数据以及元数据一同写进flash。
READ
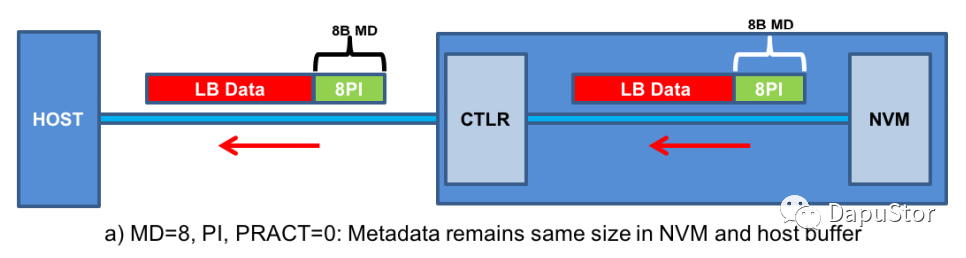
在这种场景下,SSD的主要行为是从flash读到数据后,根据HOST设置的PRCHK,然后对PI进行检查。若某一项没有通过检查则返回err,否则将数据以及元数据一同返回给HOST。
Metadata size>8
当matedata的大于8B时,那么PI只是metadata的一部分,根据设置PI会置于meta的头部或者尾部。
Write
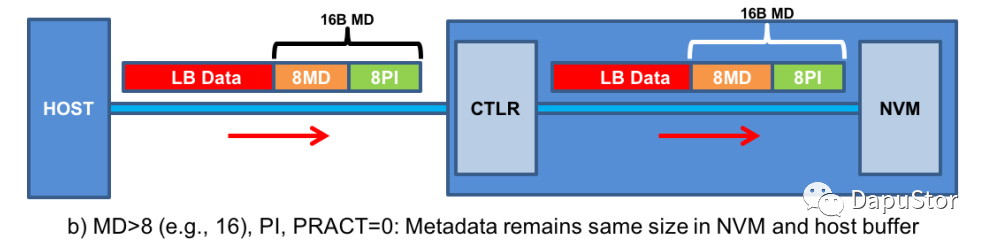
Read
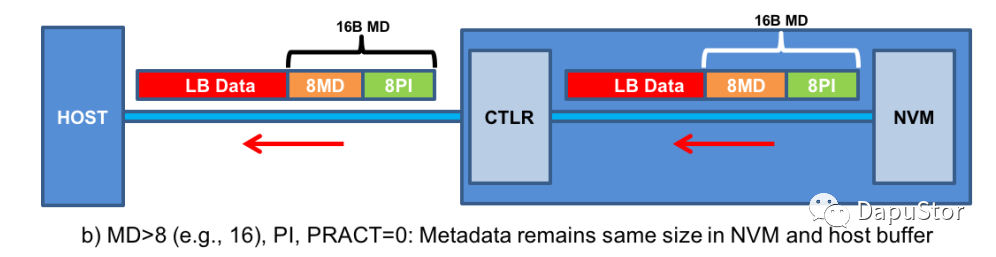
PRACT=1:
NVME标准驱动目前只match支持这种形式的端到端数据保护,就是由控制器产生PI,并由控制器来校验PI.
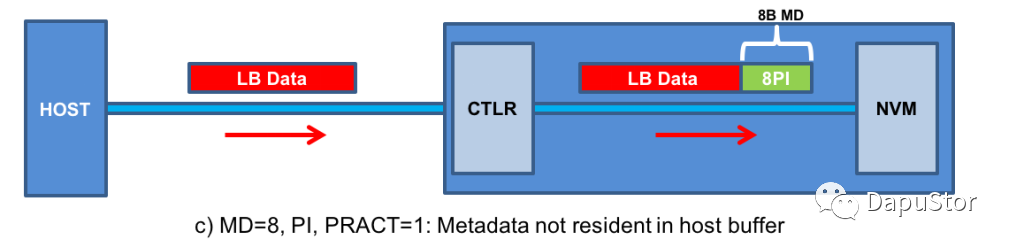
Metadata size=8
Write
控制器根据ILBRT以及NLB来生成对应的PI,然后插入到每个lba数据的末尾。
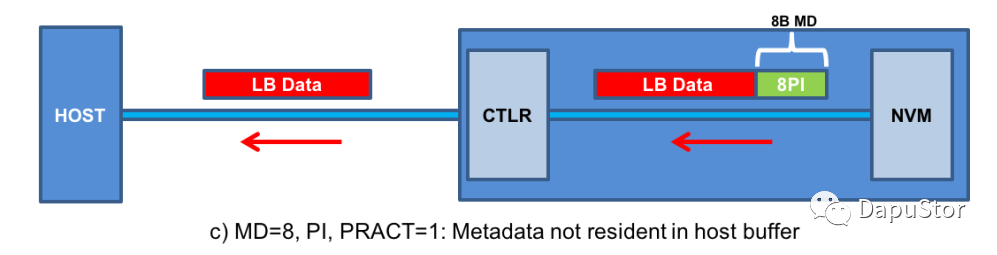
Read
控制器根据EILBRT以及NLB对每个lba的pi进行校验,若校验失败则报端到端数据出错。
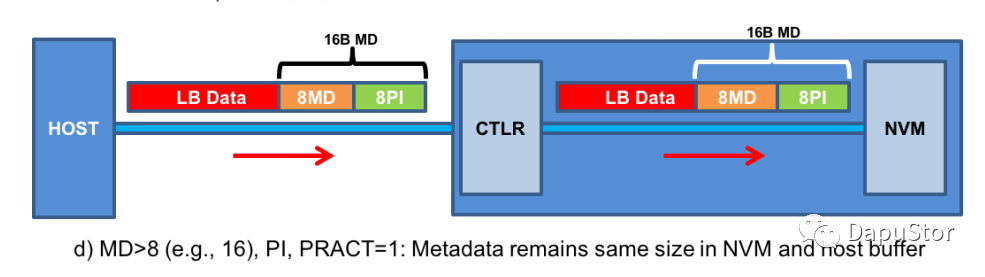
Metadata size>8
Write
Metadata size大于8B的时候,控制器依据ILBRT生成PI,然后依据identity或者format设置的PIL为0或1将PI置于metadata的末尾或者是开头,下图所示的只是其中的一种放置在末尾的情况。
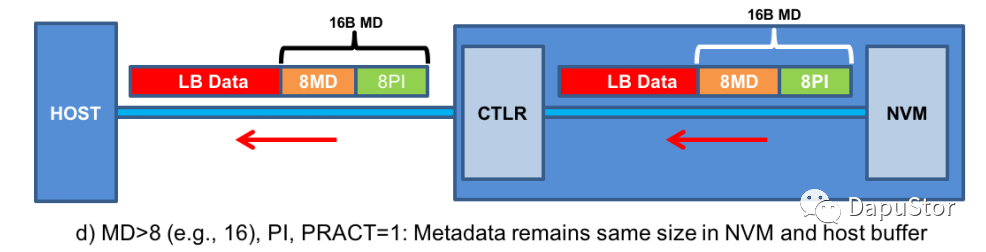
Read
控制器根据EILBRT以及identity或者format设置的PIL得到PI是置于metadata的末尾还是开头,然后进行校验,若校验失败则报端到端数据校验出错,校验成功则往HOST传输LBA Data以及MetaData。
从协议来看这里不同于8Byte的场景,控制器传输的数据是连同MetaData 的PI也一同传输了,这样的话Host需要根据PIL来拷贝有效的metadata。
本文主要结合Spec分享了NVME协议中DIF的数据传输方式以及介绍了如何使用NVME 的Identity、Format的命令来开启NVME SSD的DIF功能。但是由于DIF要求用户数据每个扇区中都带有metadata数据,几乎大部分应用层是没有生成PI保护数据的,这就要求在驱动层生成DIF的meta数据并进行数据拼接,这样做会降低驱动层的性能,并且linux通用驱动对硬盘的DIF支持还不是很好,部分硬盘厂商支持DIF的硬盘都带有发布支持对应功能驱动程序,当前硬盘DIF功能的主要使用者主要集中在存储阵列厂商。


肆:参考资料
1.NVM Express (NVMe) 1.3 Base Specification
2.https://blog.csdn.net/swingwang/article/details/61661117


识别图中二维码
关注我们