AI Weekly|民法典为 AI 换脸划定法律红线,特朗普推文被Twitter打上“事实检查”标签,医学AI临床表现有待提高
民法典为 AI 换脸划定法律红线
近日,民法典草案提请十三届全国人大三次会议审议,针对近年来愈演愈烈的“深度伪造”“AI换脸”侵犯肖像权的现象作出明确规定:
明确任何组织或者个人不得以丑化、污损,或者利用信息技术手段伪造等方式侵害他人的肖像权。其他人格权的许可使用和自然人声音的保护,参照适用本章的有关规定。

AI换脸,简单来说,就是PS的视频版。PS可以将某人的面部替换成另一个人;AI换脸则通过人脸特征自动提取、编码等技术,将视频中的角色进行“改头换面”。
2019年8月30日,一款名为“ZAO”的软件上线,下载量迅速攀升至苹果商店免费榜第一名。不少用户上传自己的照片,把明星塑造的角色换成自己的脸,并上传“改头换面”的视频片段到朋友圈等社交平台,过了把主角瘾。
但火爆并没有持续多久。由于“ZAO”用户协议中暗藏涉嫌侵犯用户隐私权的霸王条款,后被工信部约谈。霸王条款删除后,争议并未终止。有网友担心,自己会不会成为受害人或者侵权人,如果面部信息泄露,被人非法利用怎么办?如果“被换脸”明星提起侵犯肖像权诉讼,又该怎么办?

实际上,肖像权、版权、人格权等,在以往的不少法规中也多有界定和规范,只是,由于网络智能化因素的介入,让一些法理问题变得模糊和复杂起来。随着人工智能等新兴技术的进一步发展,法律法规能否根据技术发展现状和趋势及时跟进,适应社会发展的要求是一项重要议题。
此次提请审议的民法典草案响应了上述呼声,充分考虑了互联网、人工智能等新技术对人类经济社会的影响,对它们的发展方向和基本原则进行了规范。
特朗普推文被Twitter打上“事实检查”标签
本周二,Twitter首次在美国总统唐纳德·特朗普Twitter帐户的两条推文中添加了“事实检查”标签,标签显示这两条推文包含“潜在误导(potentially misleading)”信息。
该标签被贴在@realDonaldTrump本周二发的两条推文上,推文称,邮寄选票“实质上是欺诈性的”,并将导致“人为操纵的选举”。
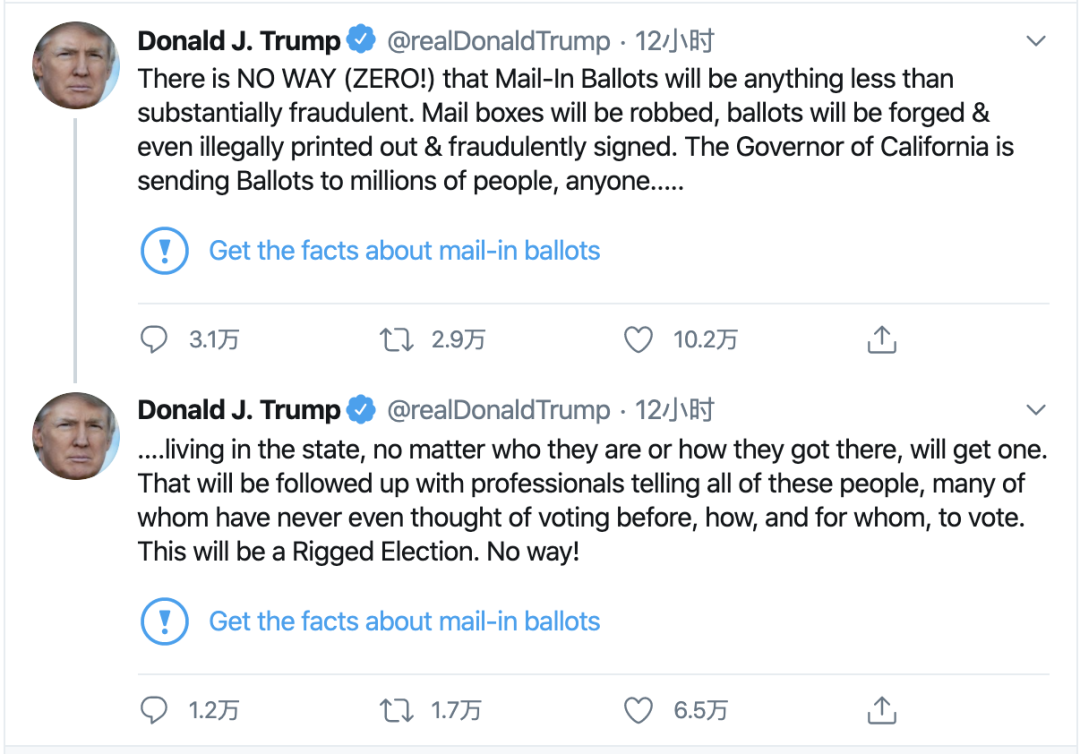
Twitter发言人表示,这些推文“包含有关投票程序的潜在误导性信息,并已被标记提供有关邮寄选票的更多背景信息。”当用户看到特朗普的推文时,Twitter上会附有一个链接,上面写着“获取有关邮寄选票的事实”,该链接指向一系列有关该主题的推文和新闻文章。在事实检查页面的顶部,Twitter写道:“特朗普错误地声称邮寄投票会导致‘人为操纵的大选’。然而,事实检查人员说,没有证据表明邮寄投票与选民欺诈有关 。”
Twitter发言人表示,此举符合公司于本月初出台的“事实检查”新政策,旨在限制与新冠病毒大流行有关的“潜在有害和误导性内容的传播”。

特朗普竞选经理布拉德·帕斯卡尔(Brad Parscale)在一份声明中回应了Twitter的决定:“与有偏见的假新闻媒体‘事实检查员’建立伙伴关系,是Twitter试图为其明显的政治策略提供虚假信誉的烟幕。”
Google医学AI应用于真实临床,表现差强人意
许多人希望 AI能够加快疾病筛查速度并减轻临床人员的压力,但是Google Health的一项最新研究表明,如果不针对临床环境进行量身定制,即使是最精确的AI系统,在实际应用中的表现也可能差强人意。
具体研究内容,是Google Health在泰国进行的首次真实临床环境下的AI系统测试。由于泰国卫生部此前设定了年度目标,需要在今年完成对60%的糖尿病患者进行糖尿病性视网膜病筛查。然而泰国大约有450万名患者,却只有200名视网膜专家。
所有,一方面为了减缓医护人员压力,另一方面为了解AI是否可以为疾病筛查提供真实帮助,Google Health的研究人员在泰国的11家诊所配备了Google的医学AI系统,该系统经过训练后可以发现糖尿病患者的眼部疾病迹象。

据介绍,糖尿病性视网膜病的传统筛查过程,是由护士对患者的眼睛进行扫描拍摄,然后将图像发送给国内的专家进行诊断,从检查到出确诊,可能需要长达10周的时间。
而Google Health声称,他们开发的AI系统可以在对眼睛扫描的过程中自动识别出糖尿病性视网膜病变的迹象,准确率超过90%,可以说达到了“人类专家水平”,并且原则上可以在不到10分钟的时间内得出诊断结果。
但Google Health团队在过去的几个月中,收集了大量的使用反馈,发现结果并不如他们想象中那样理想:AI系统在正常运行时,确实可以加快筛查速度,但是会存在无法识别图像的情况。
与大多数图像识别AI一样,在训练阶段,用于筛查糖尿病性视网膜病的深度学习模型采用的是高质量扫描图像。为了确保筛查结果的准确性,该系统会拒绝质量低于特定阈值的图像。
但是在实际应用过程中,由于护士每小时要对数十名患者进行扫描检查,并且经常会在光线不足的情况下拍摄图像,因此约有20%的图像质量较差,达不到系统设定的阈值,最终被AI系统拒绝识别。
目前,Google Health小组正在与当地医务人员合作设计新的工作流程。例如,培训护士在极端情况下使用自己的判断,通过Google也在考虑对模型本身进行调整,让它能够更好地处理不完美的图像。
受数据集性别偏斜影响,AI模型准确性堪忧
近期,DeepMind推出一款AI模型,能够预测哪些患者会出现肾功能损伤。但该模型被揭示出存在“性别偏斜”的问题:训练数据集中女性患者仅占6%,并且模型对女性进行测试时效果更差。
根据阿根廷某研究团队近期在PNAS期刊发布的研究成果显示,当女性患者被排除在训练数据外或在数据集中明显不足时,受到胸部区域的影响,算法在对女性患者进行诊断测试时结果表现往往较差。当男性被排除在外或人数不足时,也显示出相同结果。
研究人员评估了三种开源机器学习算法——DenseNet-121、ResNet和Inception-v3,这些算法被广泛应用于研究实验,但尚未应用于临床。
研究人员分别采用这算法对两个开放源数据集的数据进行训练,这两个数据集由NIH(美国国立卫生研究所)和斯坦福大学维护,数据集中包含成千上万患者的胸部X射线图像。
这两个数据集的患者性别分布相对合理——NIH数据集中56.5%的图像来自男性患者,而斯坦福数据集中的图像大约为60%。因此,在正常的研究环境中,不用担心会训练数据出现性别偏斜问题。

但是出于实验目的,来自阿根廷的研究人员有目的地引入了“性别偏斜”。基于这两个基础数据集,他们建立了五种不同的训练数据集,这些数据集图像数量相同,但性别分布各自不同,分别是:女性患者占比100%、男性患者占比100%、女性患者占比75%和男性患者占比25%、男性患者占比75%和女性患者占比25%、男性患者与女性患者各占50%。
研究人员在经过测试后,趋势很明显:当对训练数据中性别占比不足的一方性别患者进行测试时,算法效果会显著变差。
往期回顾




