机器之心 & ArXiv Weekly Radiostation参与:杜伟、楚航、罗若天
本周的重要论文包括OpenAI推出的史上最大AI模型GPT-3,以及Facebook AI将Transformer用于目标检测和全景分割的跨界尝试。
Knowledge Graph Embedding for Link Prediction: A Comparative Analysis
Efficient Deep Reinforcement Learning via Adaptive Policy Transfer
The Resurgence of Structure in Deep Neural Networks
End-to-End Object Detection with Transformers
Point2Mesh: A Self-Prior for Deformable Meshes
Language Models are Few-Shot Learners
PyChain: A Fully Parallelized PyTorch Implementation of LF-MMI for End-to-End ASR
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Knowledge Graph Embedding for Link Prediction: A Comparative Analysis摘要:知识图谱(Knowledge graph, KGs)在工业和学术领域有很多应用,这反过来又推动了从各种来源大规模提取信息的研究工作。尽管付出了诸多努力,但不得不承认最先进的知识图谱也是不完整的。链路预测(Link Prediction, LP)是一种根据知识图谱中的已存在实体去预测缺失事实的任务,它是一种有前途、广泛研究且旨在解决知识图谱不完整性的任务。在最近,基于知识图谱嵌入的链路预测技术在一些基准测试中实现了良好的性能。尽管这方面的研究文献在快速增加,但对这些方法中不同设计选择的影响却没有投以充分的注意。此外,这一领域的标准做法是测试大量的事实来报告准确性,其中一些实体被过度表示;这使得链路预测方法只修改包含这些实体的结构属性来展示良好的性能,而忽略知识图谱的主要部分。因此,在这篇综述论文中,来自罗马第三大学和阿尔伯塔大学的研究者对基于嵌入的链路预测方法进行全面比较,将分析维度扩展到常见的文献范围之外。他们通过实验比较了 16 种当前 SOTA 方法的有效性和效率,考虑到了一个基于规则的基准,并提供了文献中最流行基准的详细分析。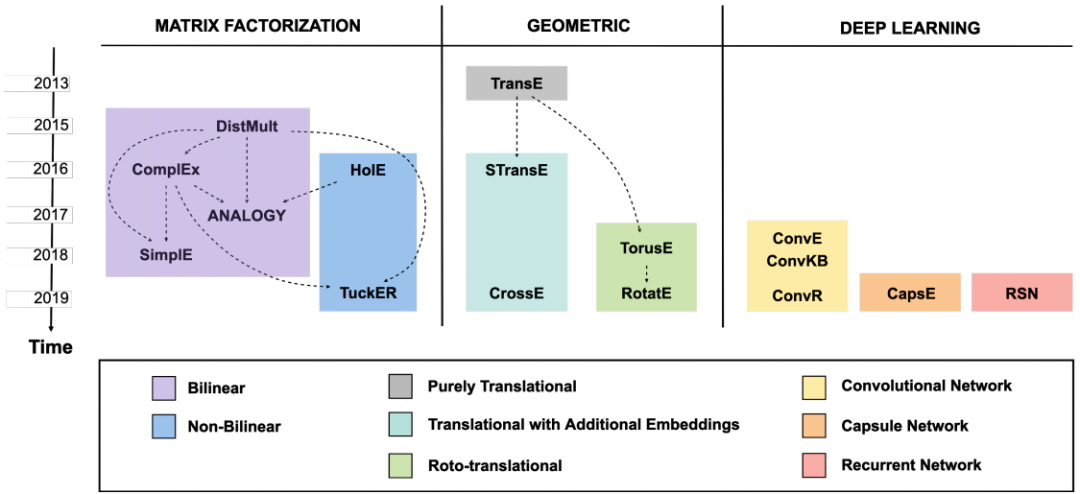
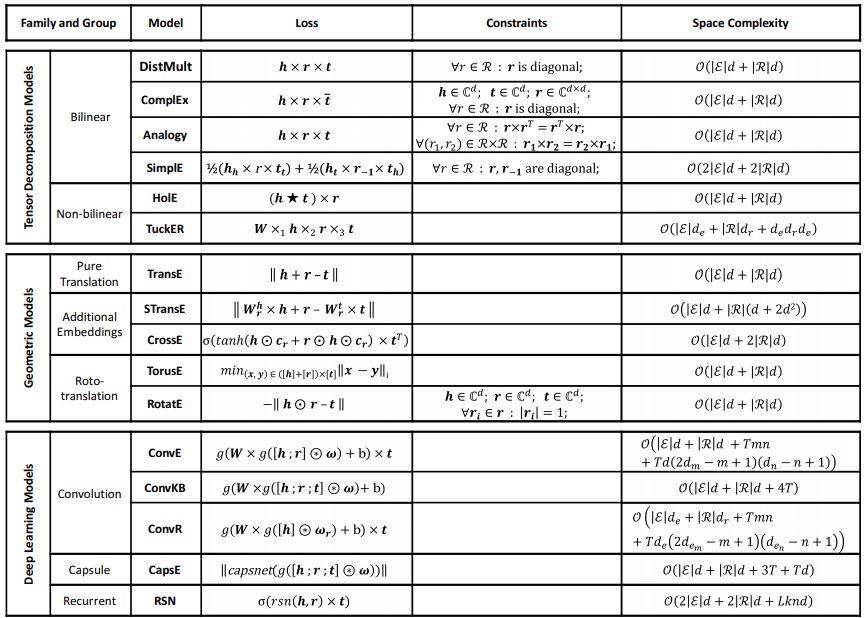
本研究对比分析中模型的损失函数、约束和空间复杂度。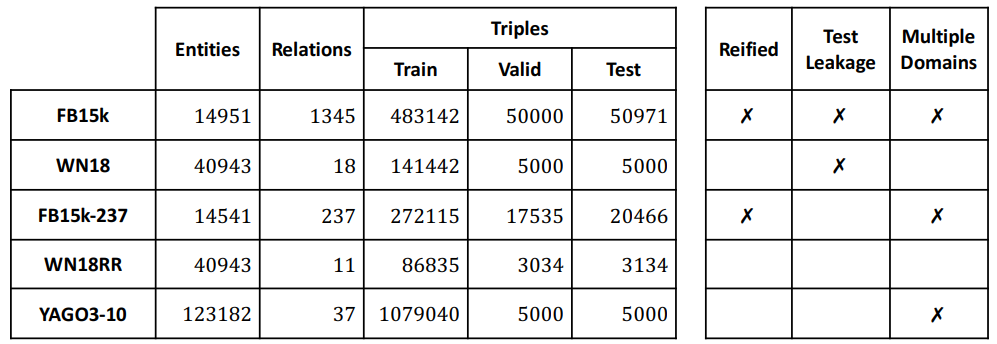
本研究对比分析中采用的 5 个链路预测数据集以及它们的常规属性。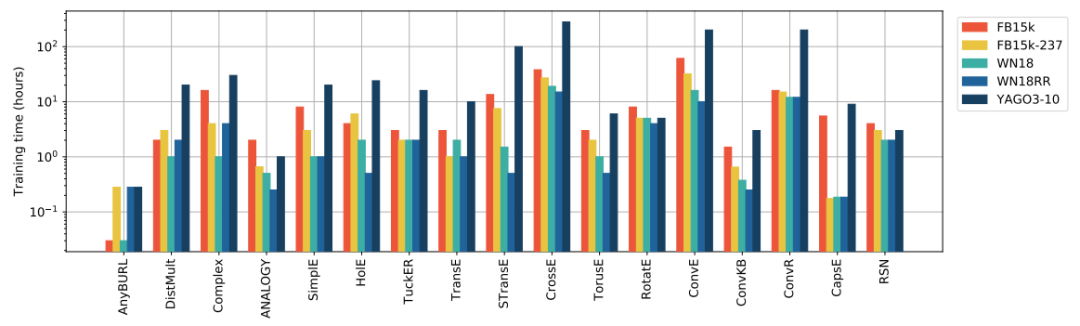
推荐:这篇长达 43 页的综述论文首次对基于知识图谱嵌入的链路预测模型进行了全面的对比分析,囊括 16 个方法和架构各异的链路预测模型,并在 5 个最流行的数据集上验证了它们的有效性和效率。论文 2:Efficient Deep Reinforcement Learning via Adaptive Policy Transfer摘要:通过利用过去学得的相关任务策略的先验知识,迁移学习(Transfer Learning, TL)在加速强化学习方面表现出了极大的潜力。现有的迁移方法要么显式地计算任务间的相似度,要么选择合适的源策略为目标任务提供指导性探索。但是,如何利用合适的源策略知识并且隐式地度量相似度,进而直接优化目标策略,这种思路的研究目前是缺失的。因此,在本文中,来自华为诺亚方舟实验室等机构的研究者提出的新型策略迁移框架(Policy Transfer Framework, PTF)通过利用上述思路来加速强化学习。该框架学习对于目标策略来说何时复用以及复用哪种源策略才能达到最佳效果,以及通过将多策略迁移建模为选择学习问题来确定何时终止这种源策略。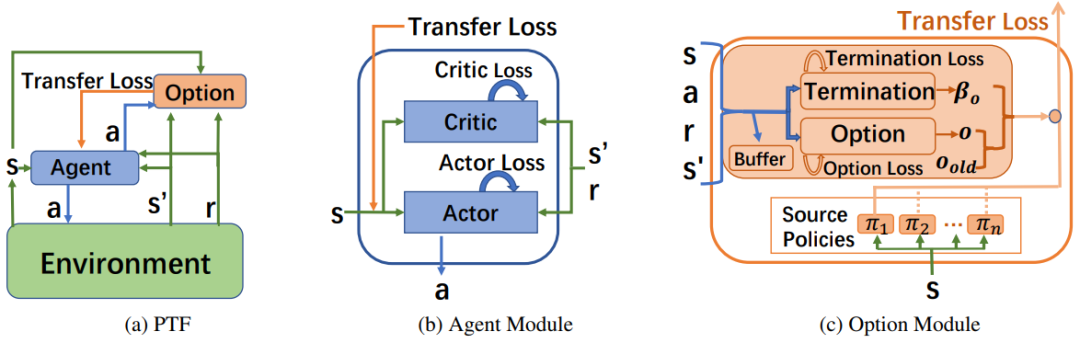

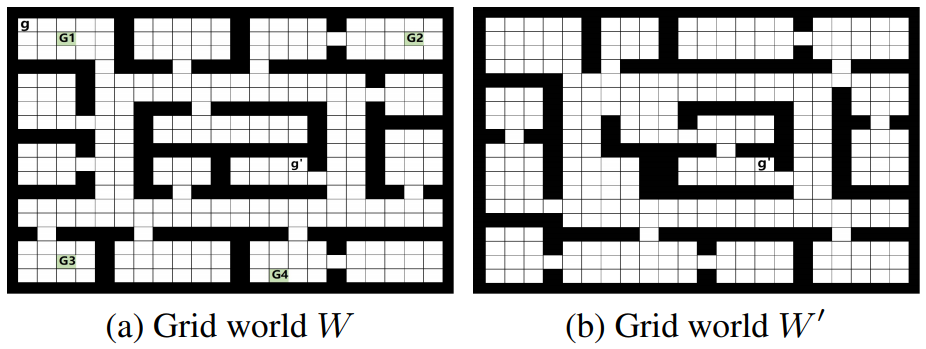
两种风格的网格世界(Grid world)W 和 W』。
推荐:实验表明,这种新型策略迁移框架能够显著加速学习过程,并在独立和连续动作空间中的学习效率和最终性能两方面超越了当前 SOTA 策略迁移方法。论文 3:The Resurgence of Structure in Deep Neural Networks摘要:使用深度神经网络的机器学习(「深度学习」)允许直接从原始输入数据中学习复杂特征,并完全消除了学习流程中手动硬编码的特征提取。这就可以通过以往分裂的研究领域,如计算机视觉、自然语言处理、强化学习和生成建模等来实现最佳性能。这些成功的案例都离不开大量可用的标签训练样本(「大数据」),这些训练样本展现出简单的网格结果(「文本或图像」),并通过卷积或循环网络加以利用。但是由于神经网络的自由度非常大,使得它们的泛化能力易于受到过拟合等的影响。但是,对于很多领域来说,广泛的数据收集并不总是适合、负担得起或者可行的。此外,数据通常以更为复杂的结构组织起来,大多数现有方法也只是不采纳这种结构。这种类型的任务在生物医学领域非常丰富。所以,在本文中,GAT 作者、剑桥大学三一学院博士生 Petar Veličković做出假设,如果深度学习能够在此类环境中充分发挥其潜力,则需要重新考虑「硬编码」方法,即通过结果性归纳偏差,将输入数据中固有结构的假设直接集成到他提出的架构和学习算法中。作者通过自己开发的 3 个 structure-infused 神经网络架构(在稀疏多模态和图结构数据上运算)和 1 个 structure-informed 图神经网络学习算法直接验证了以上假设,并证明了较传统基线模型和算法的显著性能提升。
本文作者 Petar Veličković现为 DeepMind 研究科学家,在剑桥大学三一学院取得计算机科学博士学位,其导师为 Pietro Liò。他的研究兴趣是设计能够在非平凡结构数据(如图)上运算的神经网络架构,以及这些架构在算法推理和计算生物学领域的应用。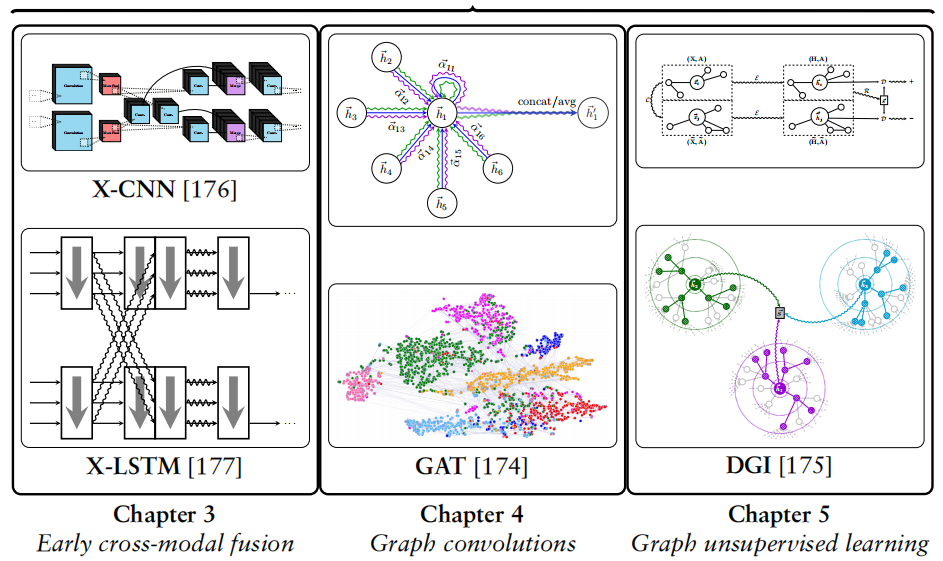
本篇博士论文的主要贡献:早期跨模态融合、图卷积和图无监督学习。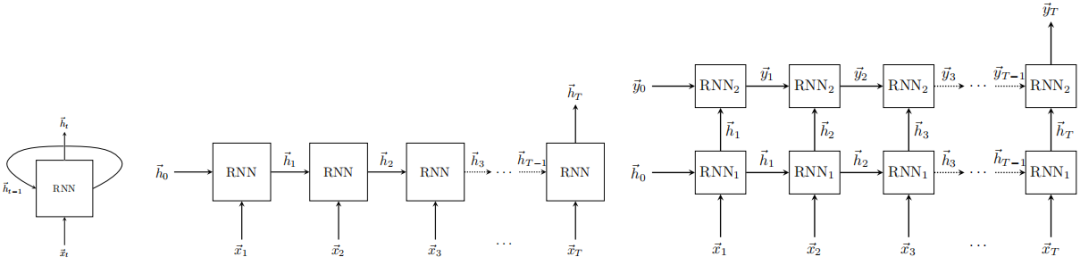
左:单个循环神经网络单元;中:RNN 单元的扩展,以执行反向传播;右:堆叠两个 RNN 单元,得到「深度」RNN。
推荐:最为大家所熟知的是,Peter Veličković为图注意力网络(Graph Attention Network, GAT)和深度图信息最大化(Deep Graph Infomax, DGI)的第一作者。论文 4:End-to-End Object Detection with Transformers摘要:近年来,Transformer 成为了深度学习领域非常受欢迎的一种架构,它依赖于一种简单但却十分强大的机制——注意力机制,使得 AI 模型有选择地聚焦于输入的某些部分,因此推理更加高效。Transformer 已经广泛应用于序列数据的处理,尤其是在语言建模、机器翻译等自然语言处理领域。此外,它在语音识别、符号数学、强化学习等多个领域也有应用。但令人意外的是,计算机视觉领域一直还未被 Transformer 所席卷。为了填补这一空白,Facebook AI 的研究者推出了 Transformer 的视觉版本—Detection Transformer(以下简称 DETR),用于目标检测和全景分割。与之前的目标检测系统相比,DETR 的架构进行了根本上的改变。这是第一个将 Transformer 成功整合为检测 pipeline 中心构建块的目标检测框架。在性能上,DETR 可以媲美当前的 SOTA 方法,但架构得到了极大简化。具体来说,研究者在 COCO 目标检测数据集上将 DETR 与 Faster R-CNN 基线方法进行了对比,结果发现 DETR 在大型目标上的检测性能要优于 Faster R-CNN,但在小目标的检测上性能不如后者,这为今后 DETR 的改进提供了新的方向。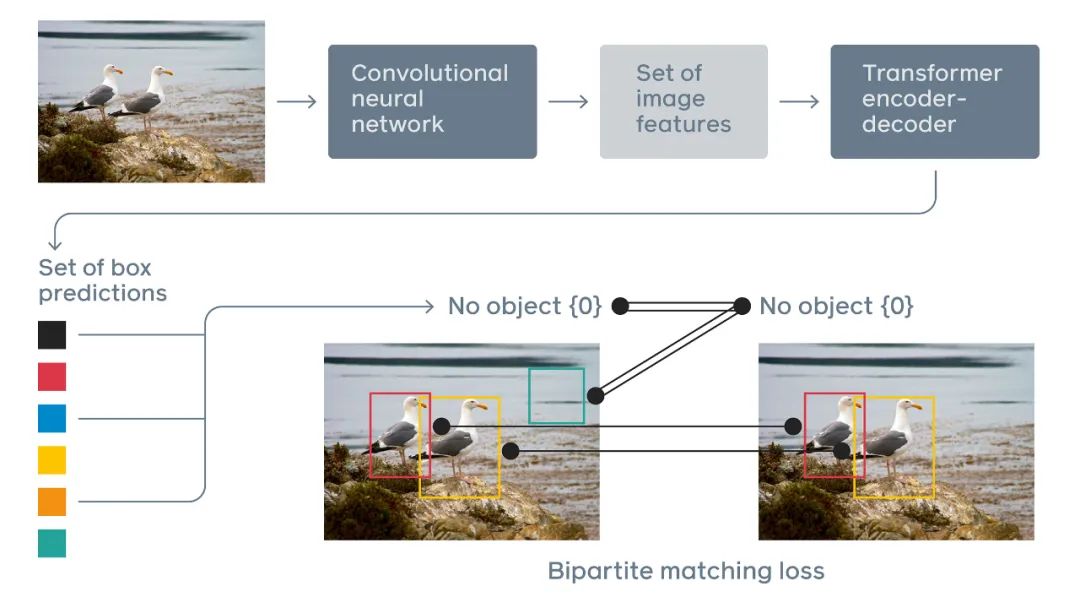
DETR 通过将一个常见 CNN 与 Transformer 结合来直接预测最终的检测结果。在训练期间,二分匹配(bipartite matching)向预测结果分配唯一的 ground truth 边界框。没有匹配的预测应生成一个「无目标」的分类预测结果。
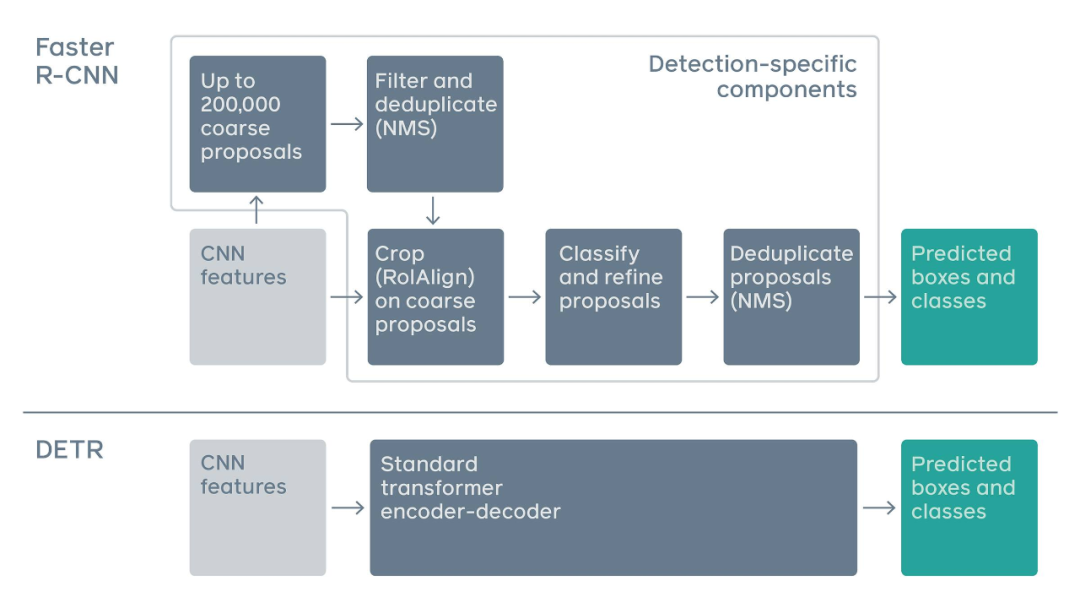
传统两阶段检测系统,如 Faster R-CNN,通过对大量粗糙候选区域的过滤来预测目标边界框。与之相比,DETR 利用标准 Transformer 架构来执行传统上特定于目标检测的操作,从而简化了检测 pipeline。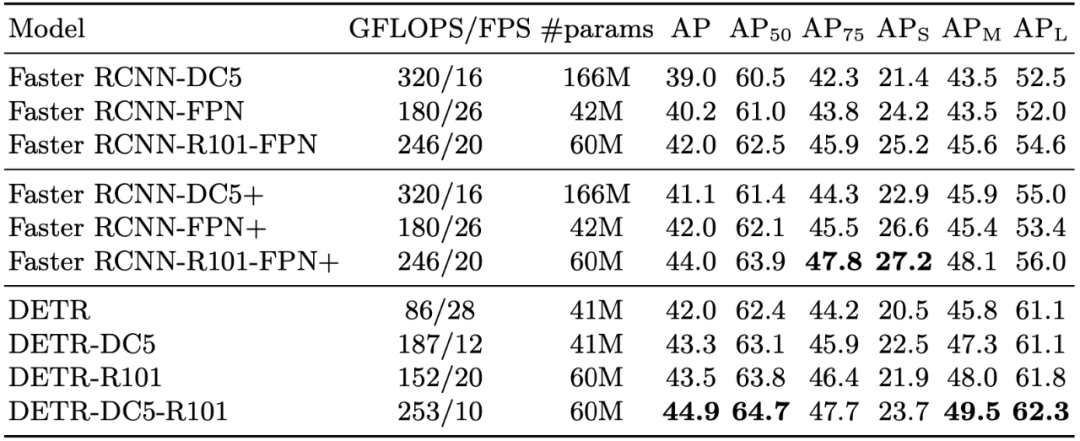
在 COCO 验证集上与 Faster R-CNN 的对比结果。
推荐:这是模型的跨界,Transformer 首次用于目标检测,效果媲美 Faster R-CNN。论文 5:Point2Mesh: A Self-Prior for Deformable Meshes摘要:近日,来自以色列特拉维夫大学的研究者提出了一种从输入点云重构曲面网格的技术——Point2Mesh。与之前方法需指定一个用于编码期望形状的 prior 不同,该研究使用输入点云来自动生成 prior,并称其为 self-prior。该 self-prior 将重复出现的几何形状由单一形状封装在深度神经网络的权重之中。研究者对网络权重进行优化,使得初始网格变形,以收缩包覆(shrink-wrap)单个输入点云。由于共享的局部内核被用来拟合整个物体,因此考虑到了整个重构的形状。将多个卷积核在整体形状上进行全局优化,从而鼓励了局部尺度在形状曲面上的几何自相似性。研究者展示了,与预先设置的平滑 prior(经常陷入不佳的局部最优)相比,使用 self-prior 收缩包覆点云能够收敛至令人满意的结果。传统的重构方法在非理想条件下性能会恶化,并且如非定向法线,噪音和部件缺失(低密度)等情况在现实世界的扫描里经常出现,而 Point2Mesh 在非理想条件下具有一定的鲁棒性。研究者在大量不同复杂度的各种形状上验证了 Point2Mesh 的性能表现。
该方法从单个对象学习,通过优化卷积神经网络(CNN)的权重来使一些初始网格变形,以收缩包覆输入点云。
使用平滑 prior 从有缺失区域的点云中重构完整的网格,该方法会忽略整体形状特征。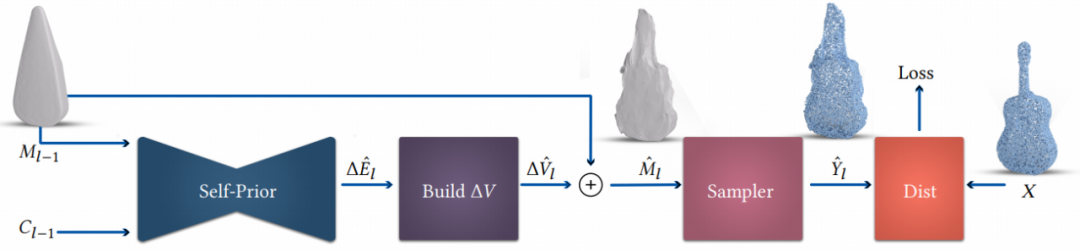

推荐:与使用预先设定的光滑 prior 不同,这篇 SIGGRAPH 论文使用 CNN 自动生成 prior,准确建模细粒度特征的同时过滤噪声与异常值。论文 6:Language Models are Few-Shot Learners摘要:近日,OpenAI 提出的 GPT-3 在社交网络上掀起了新一阵风潮,它的参数量要比 2 月份刚刚推出的、全球最大深度学习模型 Turing NLP 大上十倍,而且不仅可以更好地答题、翻译、写文章,还带有一些数学计算的能力。这样强大的深度学习,不禁让人产生一种错觉:真正的 AI 要来了吗?首先,GPT-3 最令人惊讶的还是模型体量。根据 OpenAI 的算力统计单位 petaflops/s-days,训练 AlphaGoZero 需要 1800-2000pfs-day,而 OpenAI 刚刚提出的 GPT-3 用了 3640pfs-day,看来拥有微软无限算力的 OpenAI,现在真的是为所欲为了。研究者们希望 GPT-3 能够成为更通用化的 NLP 模型,解决当前 BERT 等模型的两个不足之处:对领域内有标记数据的过分依赖,以及对于领域数据分布的过拟合。GPT-3 致力于能够使用更少的特定领域,不做 fine-tuning 解决问题。

人类对 GPT-3 175B 模型生成的约 500 词文章的判断准确率为 52%,不过相比于 GPT-3 control 模型(没有语境和不断增加的输出随机性且只具备 1.6 亿参数的模型),GPT-3 175B 生成的文本质量要高得多。
OpenAI 研究人员在以上 10 项任务中测试了 GPT-3 做简单计算的能力,且无需任何任务特定的训练。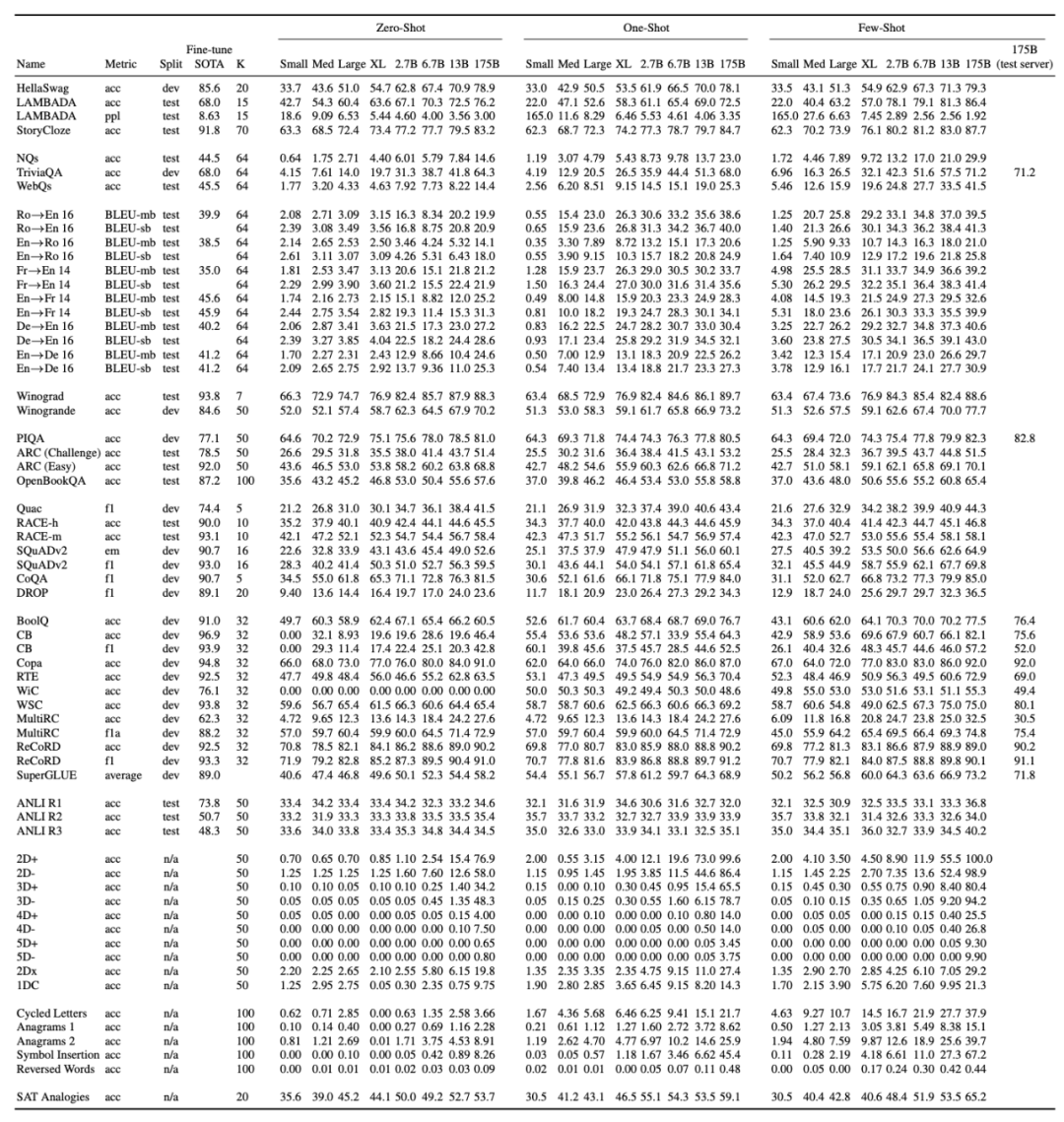
OpenAI 在多项任务中对 GPT-3 的性能进行了测试,包括语言建模、补全、问答、翻译、常识推理、SuperGLUE 等任务。推荐:包含 1750 亿参数,GPT-3 成为史上最大 AI 模型,不仅会写文章、答题,还懂数学。论文 7:PyChain: A Fully Parallelized PyTorch Implementation of LF-MMI for End-to-End ASR摘要:在本文中,来自约翰霍普金斯大学和小米的研究者(Daniel Povey)提出了 PyChain,对于 Kaldi 自动语音识别(automatic speech recognition, ASR)工具包中链式模型的端到端无网格最大交互信息(lattice-free maximum mutual information, LF-MMI)训练,PyChain 可以实现完全并行化 PyTorch 实现。与其他基于 PyTorch 和 Kaldi 的 ASR 工具包不同,PyChain 在设计上尽可能轻巧灵活,这样可以轻松地插入新的 ASR 项目或者其他基于 PyTorch 的 ASR 工具。PyChain 的效率和灵活性体现在以下这些新特征上,如在分子/分母图上的完全 GPU 训练以及对不规则长度序列的支持。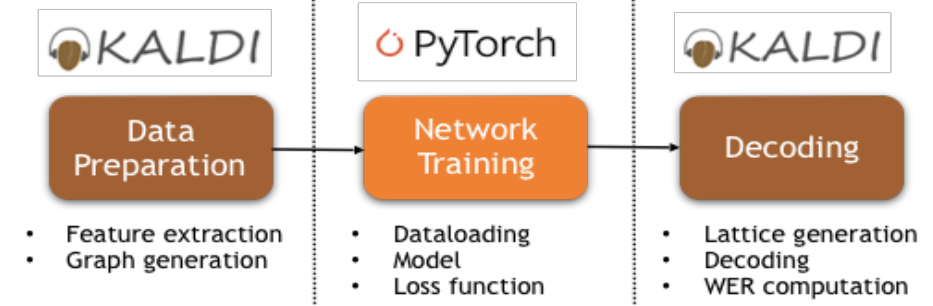
利用本研究中 PyChain 做端到端 LF-MMI 训练的 pipeline。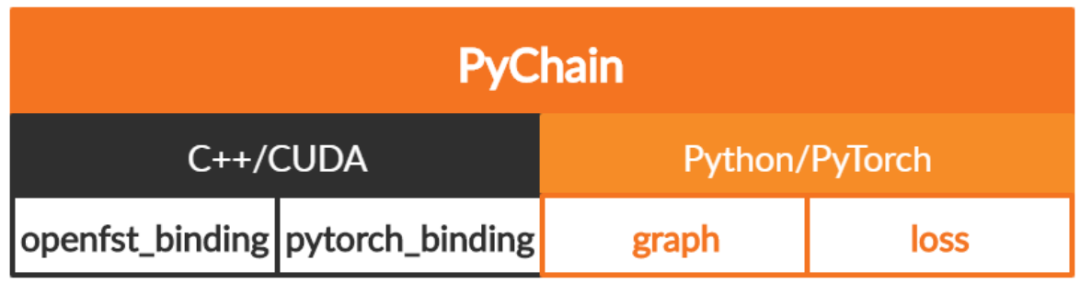

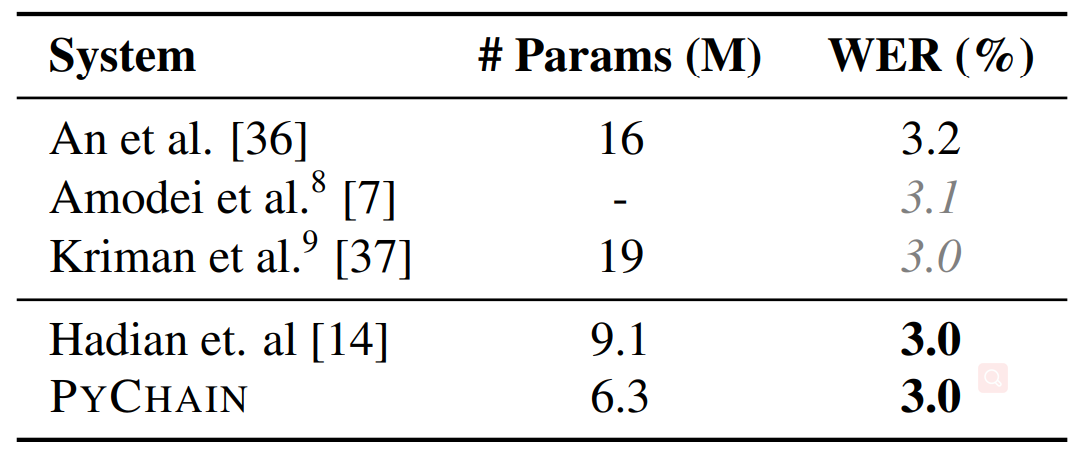
推荐:在 WSJ 数据集上的实验表明,利用简单的神经网络和常用的机器学习方法,PyChain 可以实现媲美 Kaldi 甚至优于其他端到端 ASR 系统的结果。ArXiv Weekly Radiostation机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:10 NLP Papers.mp3 来自机器之心 00:00 21:06 本周 10 篇 NLP 精选论文是:
1. Language Models are Few-Shot Learners. (from Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child等)2. Verification and Validation of Convex Optimization Algorithms for Model Predictive Control. (from Raphaël Cohen, Eric Féron, Pierre-Loïc Garoche)3. Counterfactual Detection meets Transfer Learning. (from Kelechi Nwaike, Licheng Jiaoo)4. T-RECS: a Transformer-based Recommender Generating Textual Explanations and Integrating Unsupervised Language-based Critiquing. (from Diego Antognini, Claudiu Musat, Boi Faltings)5. Syntactic Structure Distillation Pretraining For Bidirectional Encoders. (from Adhiguna Kuncoro, Lingpeng Kong, Daniel Fried, Dani Yogatama, Laura Rimell, Chris Dyer, Phil Blunsom)6. Investigating Label Bias in Beam Search for Open-ended Text Generation. (from Liang Wang, Jinlong Liu, Jingming Liu)7. K{\o}psala: Transition-Based Graph Parsing via Efficient Training and Effective Encoding. (from Daniel Hershcovich, Miryam de Lhoneux, Artur Kulmizev, Elham Pejhan, Joakim Nivre)8. A Corpus for Large-Scale Phonetic Typology. (from Elizabeth Salesky, Eleanor Chodroff, Tiago Pimentel, Matthew Wiesner, Ryan Cotterell, Alan W Black, Jason Eisner)9. Exploring aspects of similarity between spoken personal narratives by disentangling them into narrative clause types. (from Belen Saldias, Deb Roy)10. The Discussion Tracker Corpus of Collaborative Argumentation. (from Christopher Olshefski, Luca Lugini, Ravneet Singh, Diane Litman, Amanda Godley)10 CV Papers.mp3 来自机器之心 00:00 22:59 1. Symbolic Pregression: Discovering Physical Laws from Raw Distorted Video. (from Silviu-Marian Udrescu, Max Tegmark)2. Learning to Simulate Dynamic Environments with GameGAN. (from Seung Wook Kim, Yuhao Zhou, Jonah Philion, Antonio Torralba, Sanja Fidler)3. Detecting Scatteredly-Distributed, Small, andCritically Important Objects in 3D OncologyImaging via Decision Stratification. (from Zhuotun Zhu, Ke Yan, Dakai Jin, Jinzheng Cai, Tsung-Ying Ho, Adam P Harrison, Dazhou Guo, Chun-Hung Chao, Xianghua Ye, Jing Xiao, Alan Yuille, Le Lu)4. Robust Object Detection under Occlusion with \\Context-Aware CompositionalNets. (from Angtian Wang, Yihong Sun, Adam Kortylewski, Alan Yuille)5. Novel Human-Object Interaction Detection via Adversarial Domain Generalization. (from Yuhang Song, Wenbo Li, Lei Zhang, Jianwei Yang, Emre Kiciman, Hamid Palangi, Jianfeng Gao, C.-C. Jay Kuo, Pengchuan Zhang)6. Hashing-based Non-Maximum Suppression for Crowded Object Detection. (from Jianfeng Wang, Xi Yin, Lijuan Wang, Lei Zhang)7. Region-adaptive Texture Enhancement for Detailed Person Image Synthesis. (from Lingbo Yang, Pan Wang, Xinfeng Zhang, Shanshe Wang, Zhanning Gao, Peiran Ren, Xuansong Xie, Siwei Ma, Wen Gao)8. Towards Fine-grained Human Pose Transfer with Detail Replenishing Network. (from Lingbo Yang, Pan Wang, Chang Liu, Zhanning Gao, Peiran Ren, Xinfeng Zhang, Shanshe Wang, Siwei Ma, Xiansheng Hua, Wen Gao)9. A Convolutional Neural Network with Parallel Multi-Scale Spatial Pooling to Detect Temporal Changes in SAR Images. (from Jia-Wei Chen, Rongfang Wang, Fan Ding, Bo Liu, Licheng Jiao, Jie Zhang)10. Fine-Grain Few-Shot Vision via Domain Knowledge as Hyperspherical Priors. (from Bijan Haney, Alexander Lavin)10 ML Papers.mp3 来自机器之心 00:00 22:27
1. Instability, Computational Efficiency and Statistical Accuracy. (from Nhat Ho, Koulik Khamaru, Raaz Dwivedi, Martin J. Wainwright, Michael I. Jordan, Bin Yu)2. Non-IID Graph Neural Networks. (from Yiqi Wang, Yao Ma, Charu Aggarwal, Jiliang Tang)3. Parameter Sharing is Surprisingly Useful for Multi-Agent Deep Reinforcement Learning. (from Justin K Terry, Nathaniel Grammel, Ananth Hari, Luis Santos, Benjamin Black, Dinesh Manocha)4. Accelerating Antimicrobial Discovery with Controllable Deep Generative Models and Molecular Dynamics. (from Payel Das, Tom Sercu, Kahini Wadhawan, Inkit Padhi, Sebastian Gehrmann, Flaviu Cipcigan, Vijil Chenthamarakshan, Hendrik Strobelt, Cicero dos Santos, Pin-Yu Chen, Yi Yan Yang, Jeremy Tan, James Hedrick, Jason Crain, Aleksandra Mojsilovic)5. A Feature-map Discriminant Perspective for Pruning Deep Neural Networks. (from Zejiang Hou, Sun-Yuan Kung)6. Multi-Source Deep Domain Adaptation with Weak Supervision for Time-Series Sensor Data. (from Garrett Wilson, Janardhan Rao Doppa, Diane J. Cook)7. Incidental Supervision: Moving beyond Supervised Learning. (from Dan Roth)8. Approximation in shift-invariant spaces with deep ReLU neural networks. (from Yunfei Yang, Yang Wang)9. FedPD: A Federated Learning Framework with Optimal Rates and Adaptivity to Non-IID Data. (from Xinwei Zhang, Mingyi Hong, Sairaj Dhople, Wotao Yin, Yang Liu)10. COVID-19 and Your Smartphone: BLE-based Smart Contact Tracing. (from Pai Chet Ng, Petros Spachos, Konstantinos Plataniotis)