英特尔封装技术深入解读
点 击 上 方 “ 公众号 ” 可 以 订 阅 哦 !




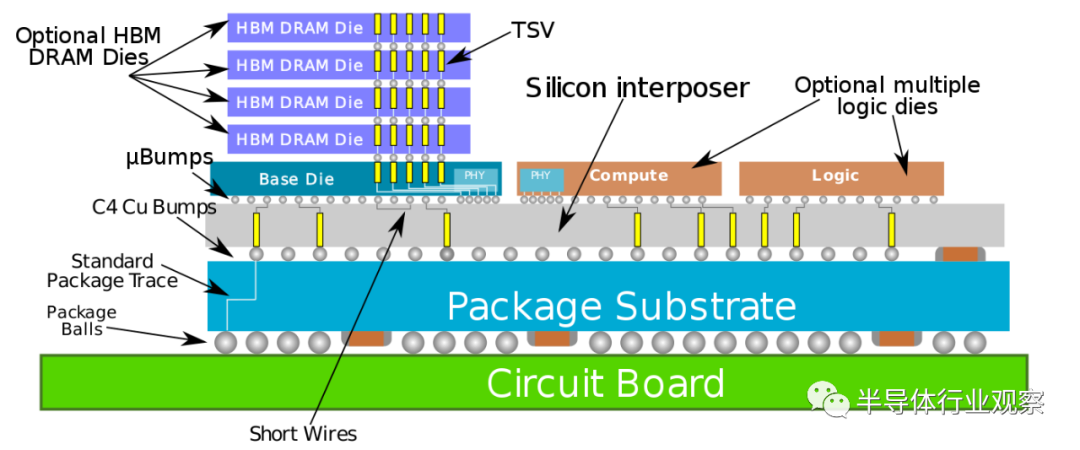
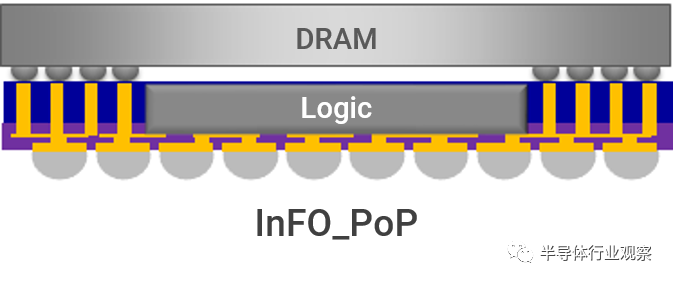
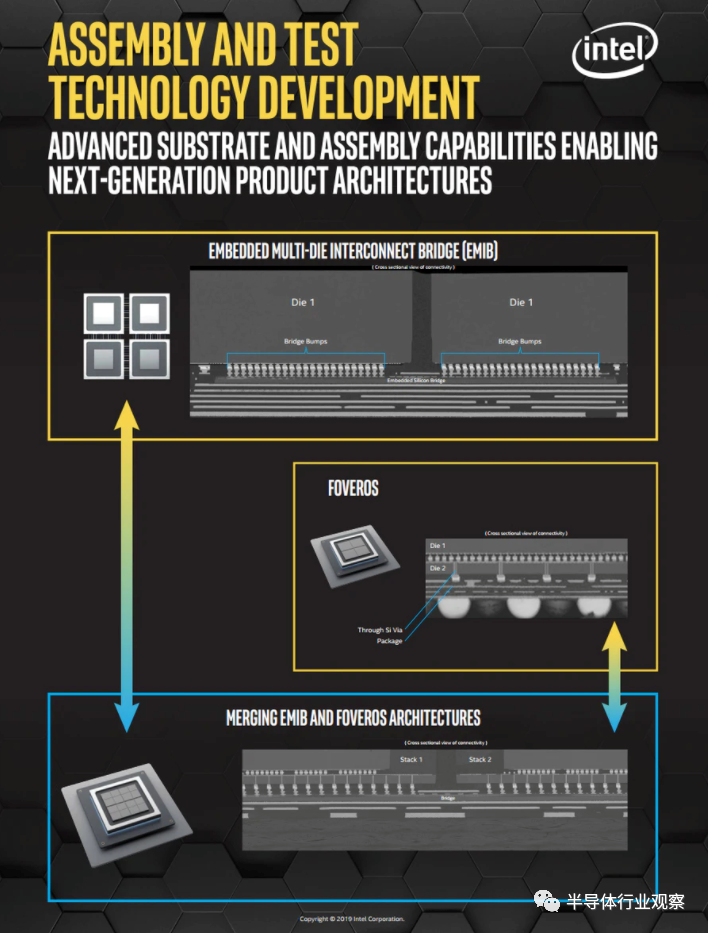
突破SiP限制的2.5D封装
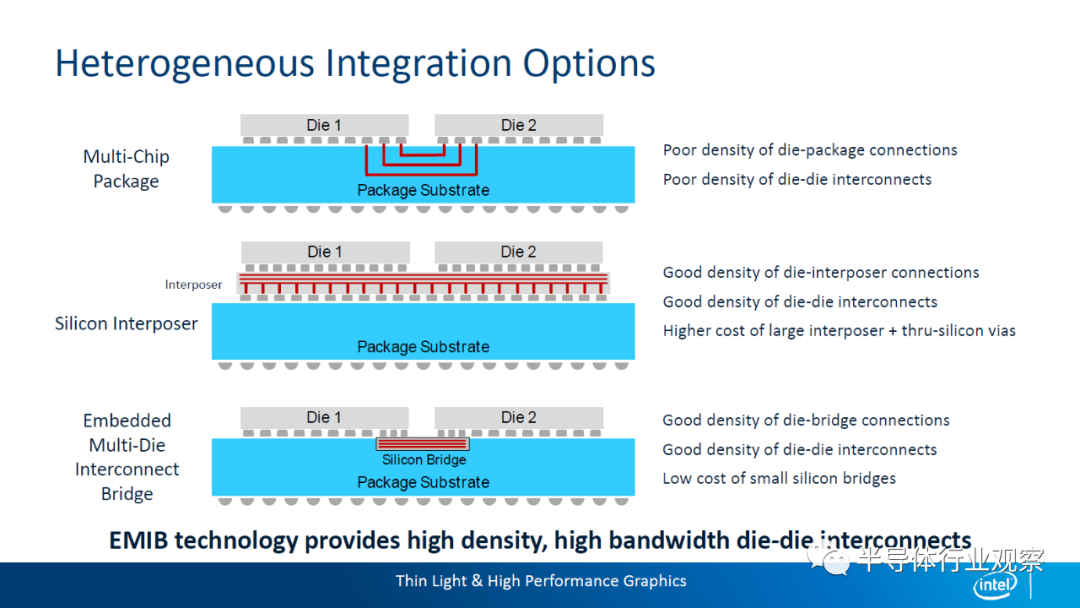
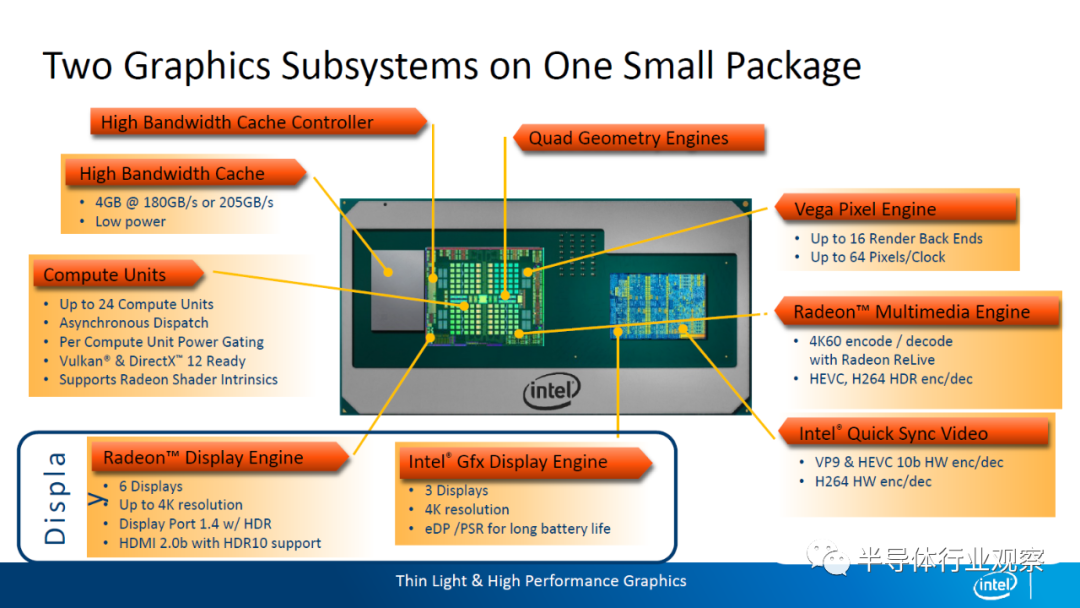
Intel阵营:2.5D的EMIB与3D的Foveros

EMIB + Foveros = Co-EMIB
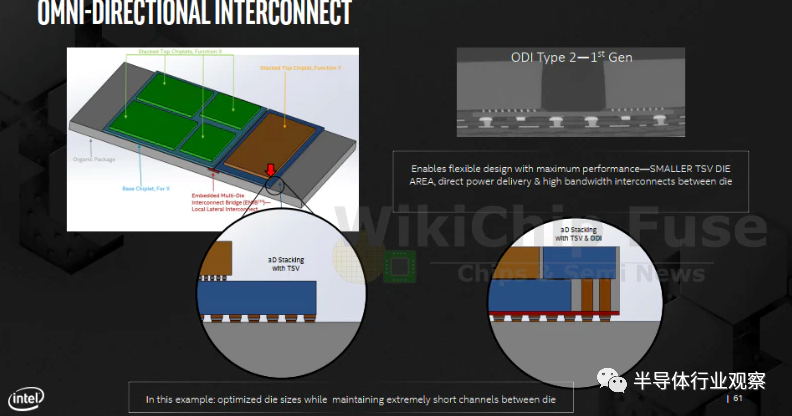
EMIB概念延伸的ODI

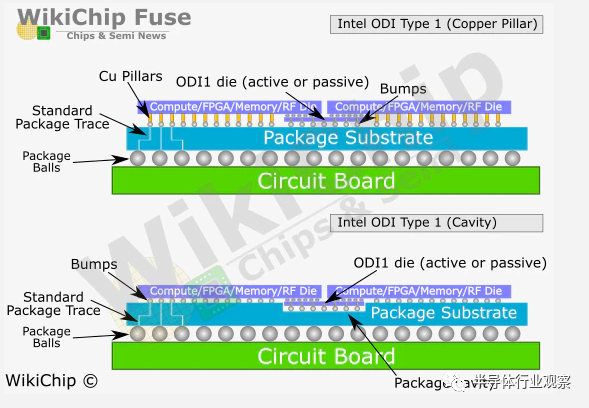
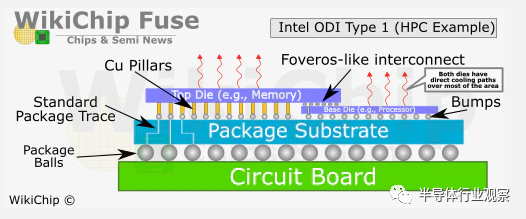


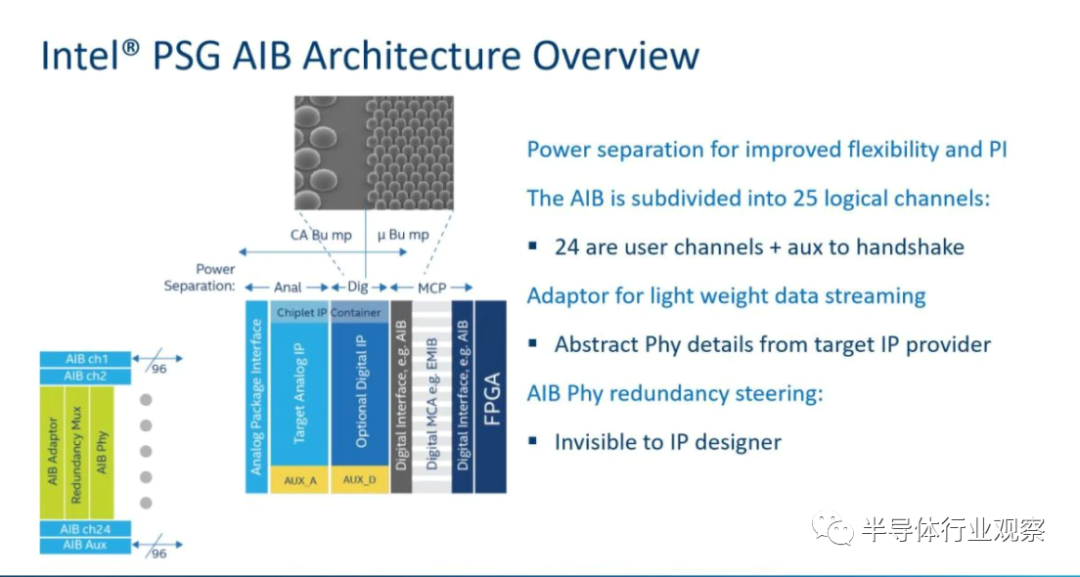
用来「推己及人」的下一代AIB:MDIO

「包水饺大赛」方兴未艾
来源:半导体行业观察
免责声明:本文系网络转载,版权归原作者所有。但因转载众多,或无法确认真正原始作者,故仅标明转载来源,如涉及作品版权问题,请与我们联系,我们将在第一时间协商版权问题或删除内容!内容为作者个人观点,并不代表本公众号赞同其观点和对其真实性负责


长按识别二维码关注我们