文本增强、半监督学习,谁才是 NLP 少样本困境问题更优的解决方案?
以下文章来源于夕小瑶的卖萌屋 ,作者JayLou娄杰
一只小狐狸带你解锁自然语言处理/深度学习/机器学习秘籍

编辑 | 丛 末
在医疗、金融、法律等领域,高质量的标注数据十分稀缺、昂贵,我们通常面临少样本低资源问题。本文从「文本增强」和「半监督学习」这两个角度出发,谈一谈如何解决少样本困境。
正式介绍之前,我们首先需要思考什么才是一种好的解决少样本困境的方案?本文尝试给出了三个层次的评价策略,我们希望采取相关数据增强或弱监督技术后:
基于此,本文首先总结了nlp中的文本增强技术,然后串讲了近年来9个主流的半监督学习模型,最后主要介绍了来自Google提出的UDA(一种文本增强+半监督学习的结合体)。本文的组织结构为:
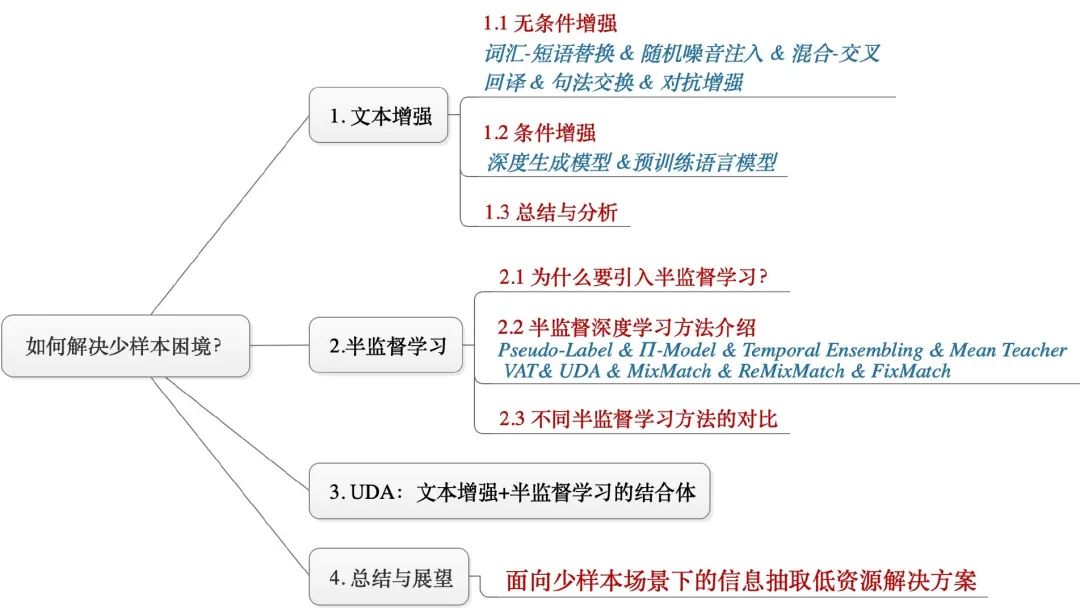
谈起文本增强技术,相信NLPer一定不会陌生,相关方法也是数不胜数。我们通常对标注数据集提供附加的感应偏置进行扩充,如何设计增强变换就变得至关重要。本文尝试从一个新角度——是否条件增强,借鉴文献[1]进行了总结归纳:
 1、无条件增强
1、无条件增强定义:既可以对标注数据进行增强(增强后标签不发生变化),又可以针对无标注数据进行增强,不需要强制引入标签信息。
词汇&短语替换
基于词典:主要从文本中选择词汇或短语进行同义词替换,词典可以采取 WordNet或哈工大词林等。著名的 EDA (Easy Data Augmentation)[2] 就采用了这种方法。 基于词向量:在嵌入空间中找寻相邻词汇进行替换,我们所熟知的TinyBERT[3] 就利用这种技术进行了数据增强。 Masked LM:借鉴预训练语言模型(如BERT)中的自编码语言模型,可以启发式地Mask词汇并进行预测替换。 TF-IDF:实质上是一种非核心词替换,对那些low TF-IDF scores进行替换,这一方法最早由Google的UDA[4]提出:

随机噪音注入
随机插入:随机插入一个词汇、相应的拼写错误、占位符等,UDA[4]则根据Uni-gram词频分布进行了采样。 随机交换:随机交换词汇或交换shuffle句子。 随机删除:随机删除(drop)词汇或句子。
注意:EDA[2]除了进行同义词替换外,也同时采用上述三种随机噪音注入。
混合&交叉
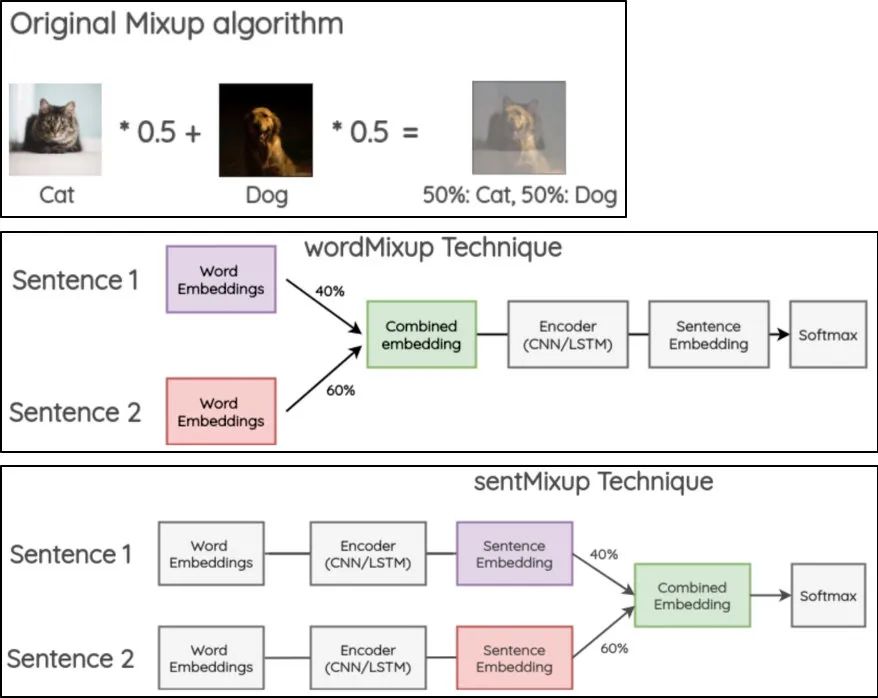
混合增强:起源于图像领域的Mixup[5],这是一种表示增强方法,借鉴这种思想,文献[6]提出了wordMixup和sentMixup将词向量和句向量进行Mixup。
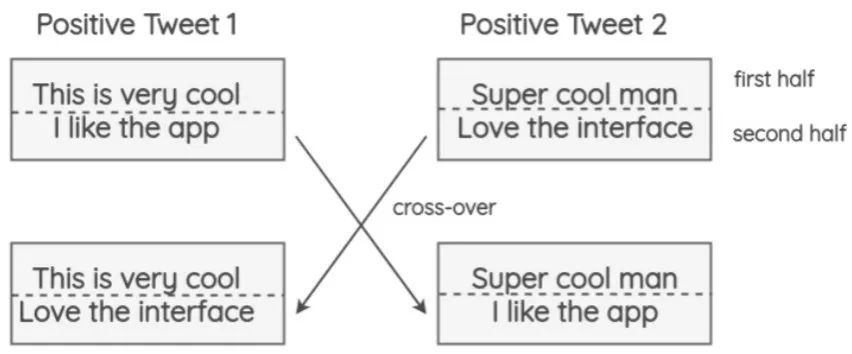
交叉增强:类似于“染色体的交叉操作”,文献[7]将相同极性的文本进行交叉:
回译:基于机器翻译技术,例如从中文-英文-日文-中文;我们熟知的机器阅读理解模型QANet[8]和UDA[4]都采用了回译技术进行数据增强。 句法交换:通过句法树对文本句子进行解析,并利用相关规则进行转换,例如将主动式变成被动式句子。 对抗增强: 不同于CV领域利用GAN生成对抗进行数据增强[9],NLP中通常在词向量上添加扰动并进行对抗训练,文献[10]NLP中的对抗训练方法FGM, PGD, FreeAT, YOPO, FreeLB等进行了总结。
定义:所谓条件增强(Conditional Data Augmentation),就是意味着需要强制引入「文本标签」信息到模型中再产生数据。
深度生成模型:既然条件增强需要引入标签信息进行数据增强,那么我们自然就会联想到Conditional变分自编码模型(CVAE),文献[11]就利用CVA进行增强。想生成一个高质量的增强数据,往往需要充分的标注量,但这却与「少样本困境」这一前提所矛盾。这也正是GAN或者CVAE这一类深度生成模型在解决少样本问题时需要考虑的一个现状。
预训练语言模型:众所周知,BERT等在NLP领域取得了巨大成功,特别是其利用大量无标注数据进行了语言模型预训练。如果我们能够结合标签信息、充分利用这一系列语言模型去做文本增强,也许能够克服深度生成模型在少样本问题上的矛盾。近来许多研究者对Conditional Pre-trained Language Models 做文本增强进行了有益尝试:
Contextual Augment[12]:这是这一系列尝试的开篇之作,其基于LSTM进行biLM预训练,将标签信息融入网络结构进行finetune,是替换生成的词汇与标签信息兼容一致。
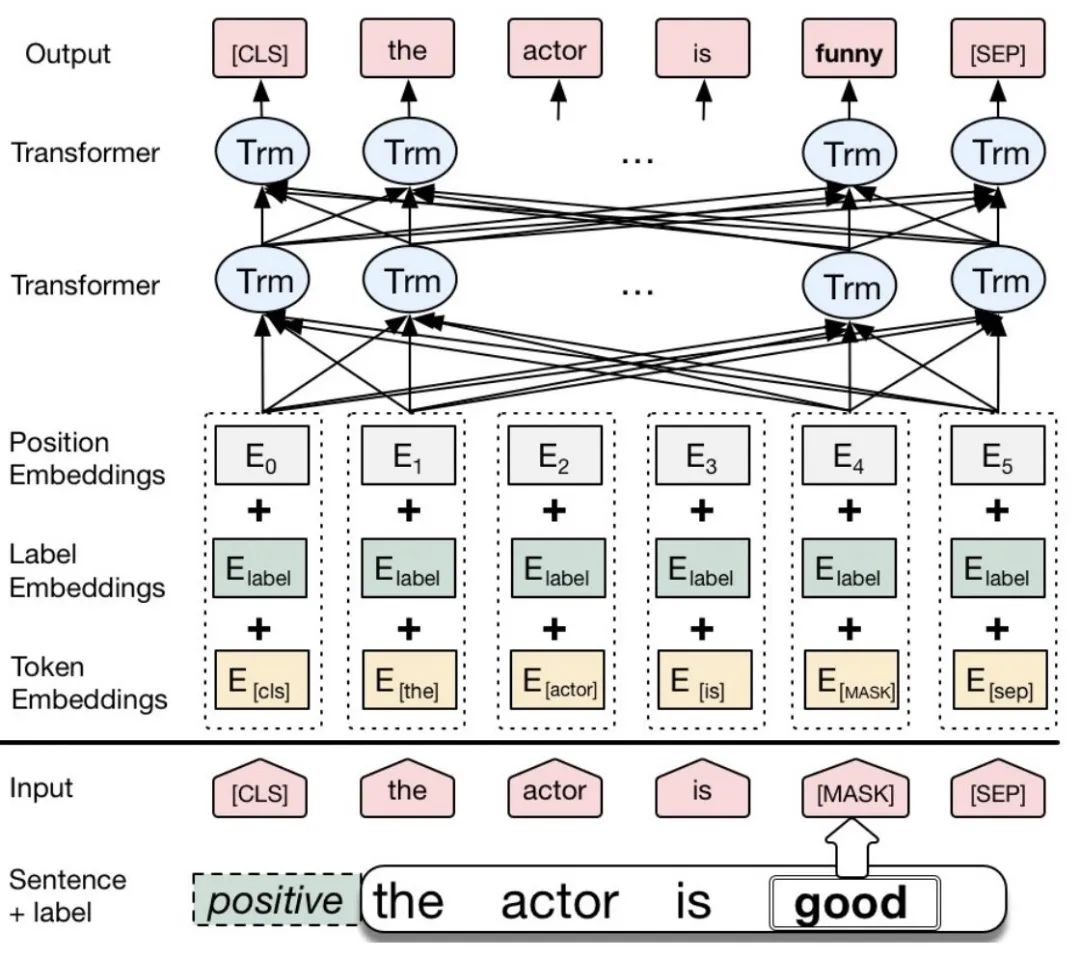
CBERT[13]:其主要思想还是借鉴了Contextual Augment,基于BERT进行finetune,将segment embedding转换融入标签指示的label embedding(如果标签类别数目大于2类,则相应扩充),如下图,替换good生成的funny与标签positive兼容。
LAMBADA [14]:来自IBM团队,其基于GPT-2将标签信息与原始文本拼接当作训练数据进行finetune(如下图所示,SEP代表标签和文本的分割,EOS是文本结束的标志),同时也采用一个判别器对生成数据进行了过滤降噪。

在最近的一篇paper《Data Augmentation using Pre-trained Transformer Models》[15]中,根据不同预训练目标对自编码(AE)的BERT、自回归(AR)的GPT-2、Seq2Seq的BART这3个预训练模型进行了对比。不同于CBERT,没有标签信息变为label embedding而是直接作为一个token&sub-token来于原文拼接。
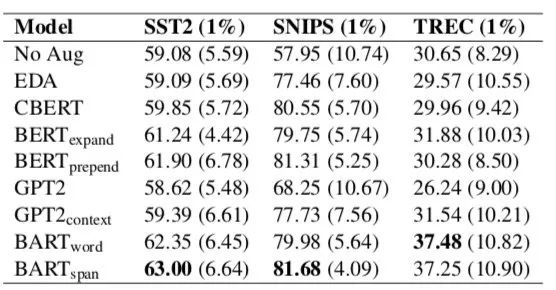
如上图所示,采样原始标注数据的1%作为少样本场景的设置,其发现BART表现最好,文中也做了相应对比实验发现:
1)AE模型BERT在做文本增强后,容易被约束产生相似的文本序列,且擅长保存标签信息。
3)Seq2Seq模型BART位于AE和AR之间,可以在多样性和语义保真度之间取得良好的平衡。此外,BART可以通过更改跨度掩码的长度来控制生成数据的多样性。
3、总结与分析
除此之外,在实践中我们也要去思考:
是否存在一种文本增强技术,能够达到或者逼近充分样本下的监督学习模型性能? 在充分样本下,采取文本增强技术,是否会陷入到过拟合的境地,又是否会由于噪音过大而影响性能?如何挑选样本?又如何降噪?
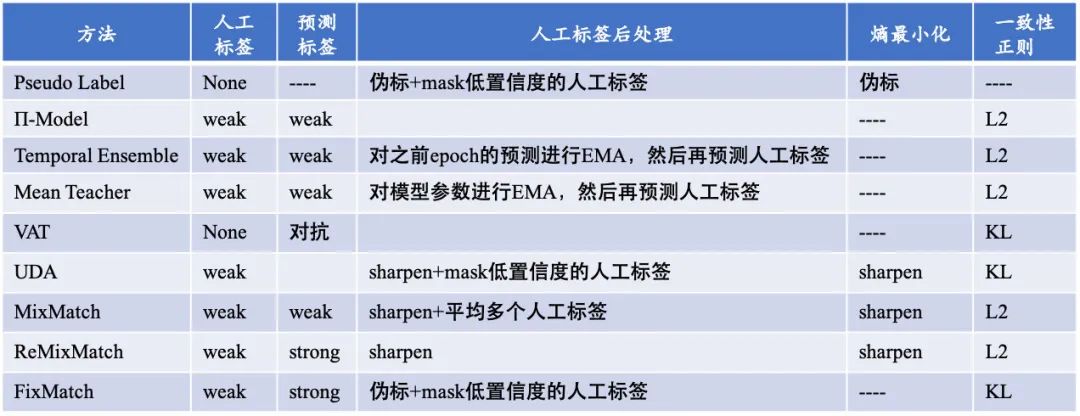
这一部分主要介绍如何结合大量无标注数据解决少样本困境,相应的弱监督方法层出不穷,本文着眼于「半监督学习」,借鉴CV领域的9个主流方法进行介绍,包括:Pseudo-Label 、 Π-Model 、Temporal Ensembling、 Mean Teacher、 VAT 、 UDA 、MixMatch 、ReMixMatch 、 FixMatch。
1、为什么要引入半监督学习?
监督学习往往需要大量的标注数据,而标注数据的成本比较高,因此如何利用大量的无标注数据来提高监督学习的效果,具有十分重要的意义。这种利用少量标注数据和大量无标注数据进行学习的方式称为半监督学习(Semi-Supervised Learning,SSL) 。
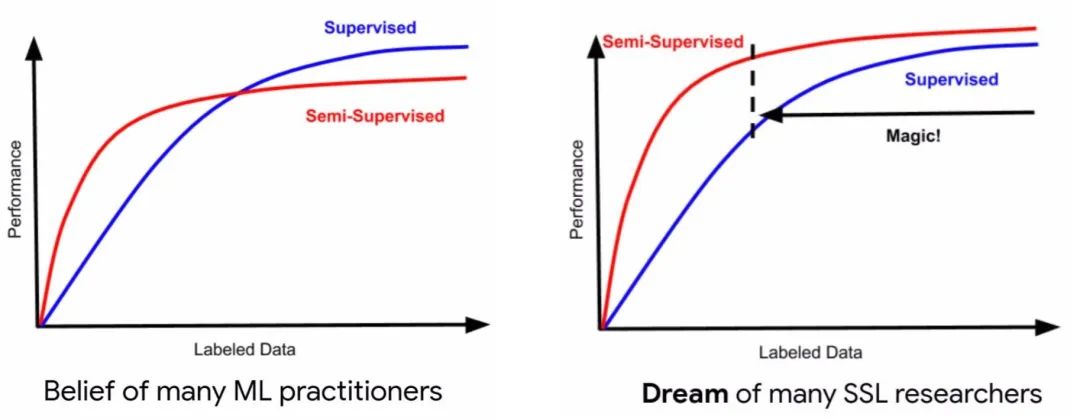
如上图所示,在同等的少量标注样本下,半监督学习通常取得比监督学习较好的性能。进入深度学习时代以来,SSL如何在少量标注样本下达到或超越大量标注样本下监督学习的效果,SSL如何在大量标注样本下也不会陷入到“过拟合陷阱”,是SSL研究者面临的一个挑战。
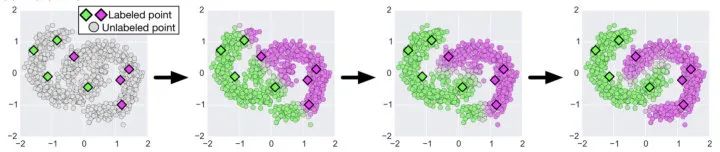
近年来,半监督深度学习取得了长足的进展,特别是在CV领域;相关的研究主要着力于如何针对未标注数据构建无监督信号,与监督学习联合建模;简单地讲,就是如何在损失函数中添加针对未标注数据相关的正则项,使模型能够充分利用大量的未标注数据不断迭代,最终增强泛化性能,正如下图所展示的那样(来自文献 [4] )。
总的来看,深度学习时代的半监督学习,主要针对未标注数据相关的正则化项进行设置,其通常有以下两种:

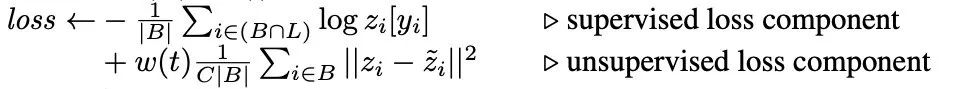
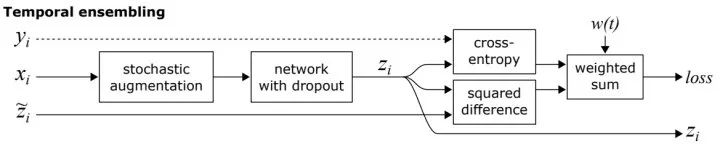
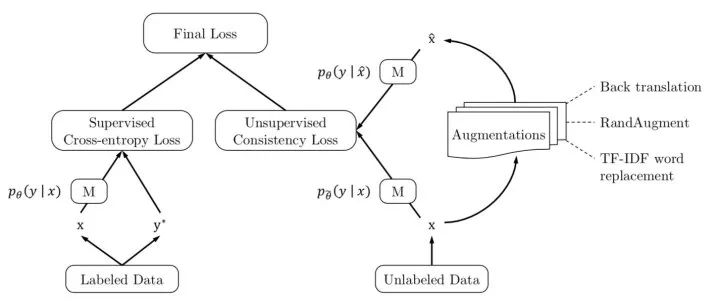
结合了熵最小化正则:对无监督信号进行sharpen操作构建人工标签,使其趋近于 One-Hot 分布,对某一类别输出概率趋向 1,其他类别趋向0,此时熵最低。此外,还直接计算了熵损失。 将人工标签与strong增强后的预测标签共同构建一致性正则,并计算损失时进行了confidence-based masking,低于置信度阈值不参与loss计算。 采用训练信号退火(TSA)方法防止对标注数据过拟合,对于标注数据的置信度高于阈值要进行masking,这与无标注数据正好相反。 使用初始模型过滤了领域外的无标注数据。
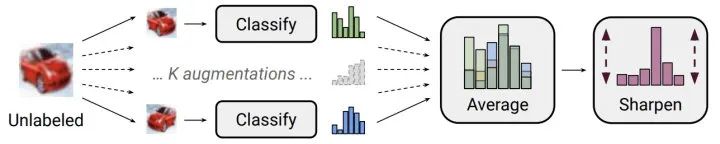

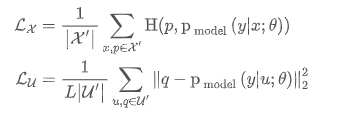
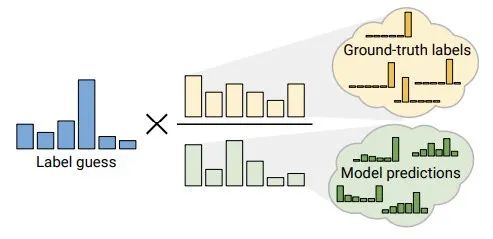
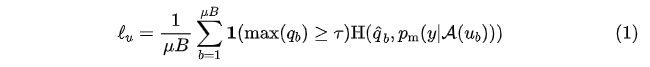
人工标签是构建“标签”指导一致性正则的实施,通常采取weak数据增强方法,也可能来自历史平均预测(Temporal Ensembling)或模型平均预测(Mean Teacher); 预测标签为模型当前时刻对无标注数据的预测,其输入可进行strong增强(UDA/ReMixMatch/FixMatch)或对抗扰动(VAT).
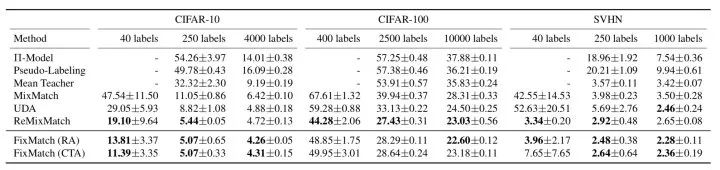
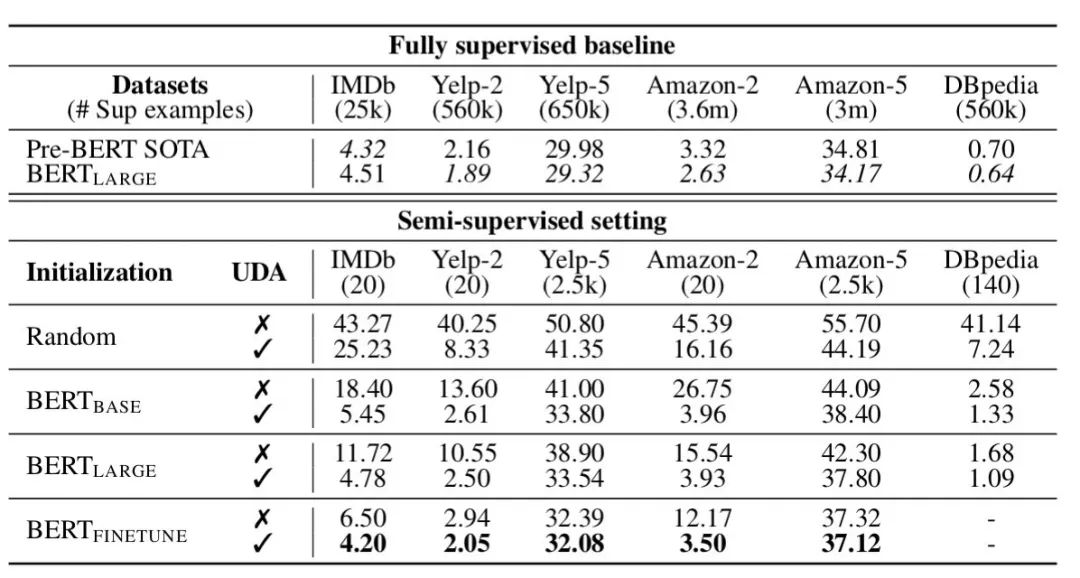
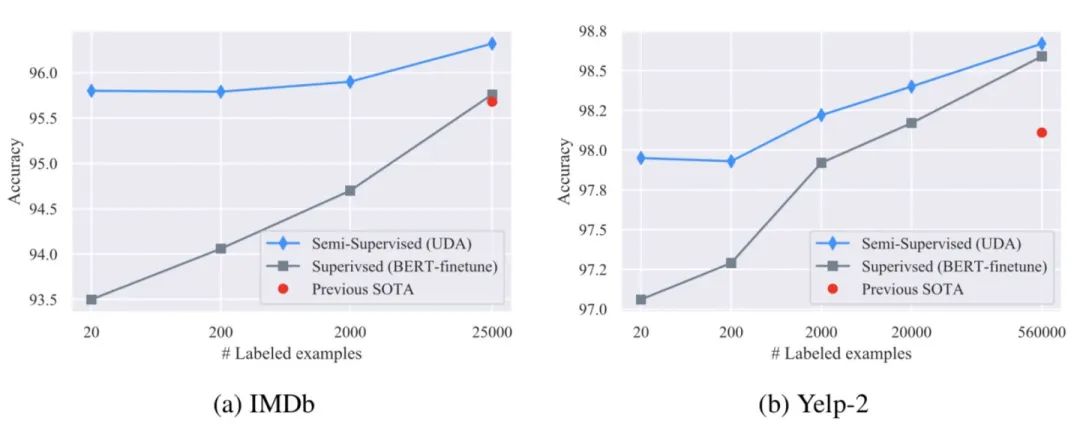
文本增强提供了原有标注数据缺少的归纳偏差,在少样本场景下通常会取得稳定、但有限的性能提升;更高级、更多样化和更自然的增强方法效果更佳。 融合文本增强+半监督学习技术是一个不错的选择。半监督学习中一致性正则能够充分利用大量未标注数据,同时能够使输入空间的变化更加平滑,从另一个角度来看,降低一致性损失实质上也是将标签信息从标注数据传播到未标注数据的过程。
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiangbaoshang@yanxishe.com
