专访ACL2020最佳论文二作:全新NLP模型评测方法论,思路也适用于CV


论文方法一览

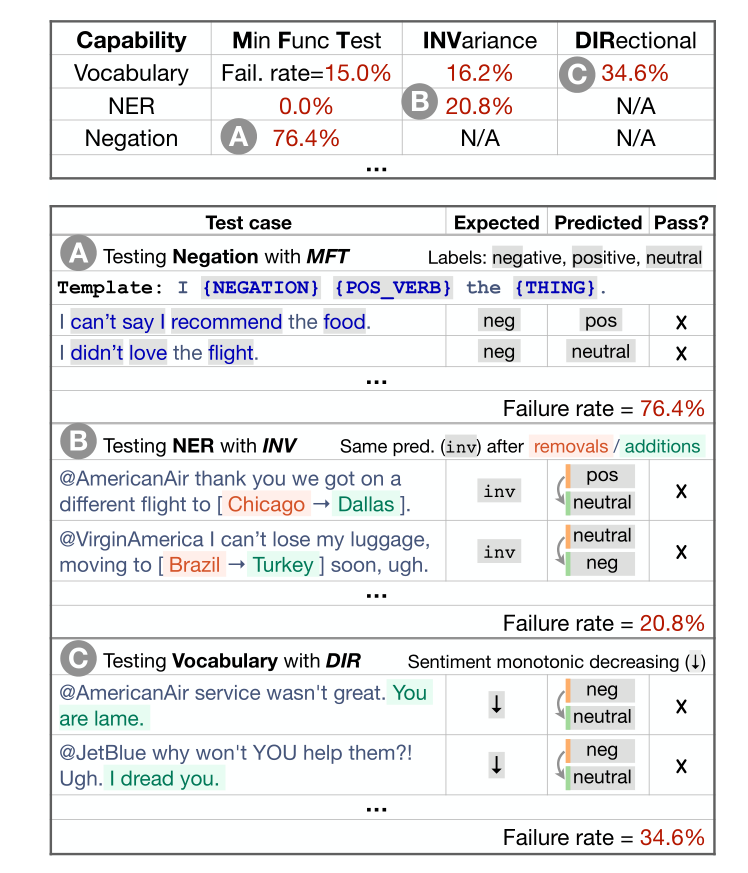
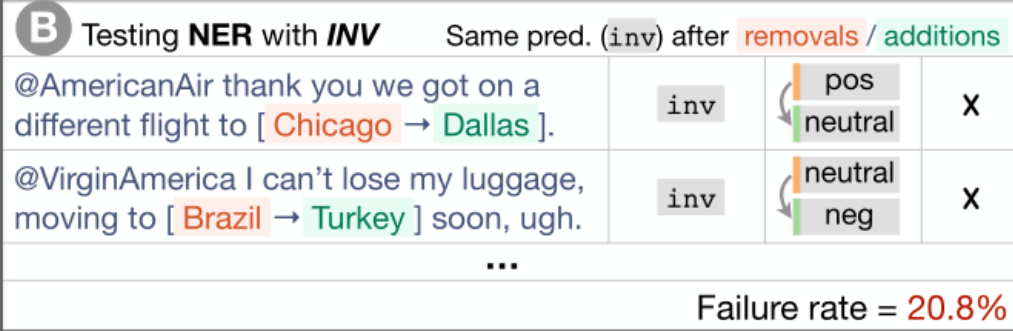
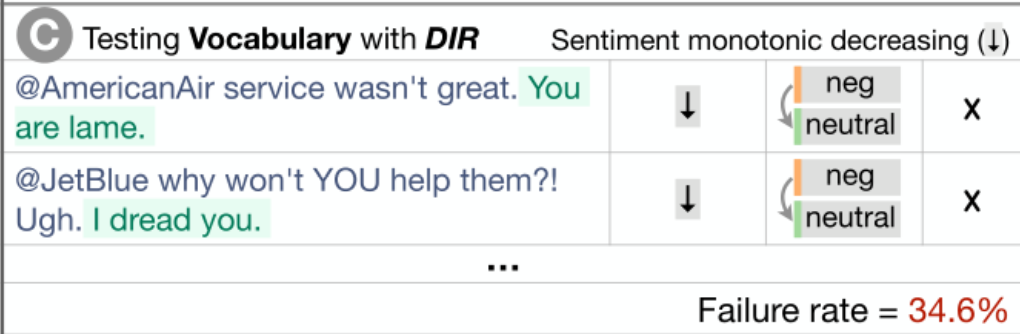
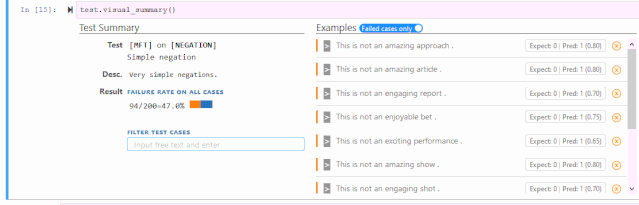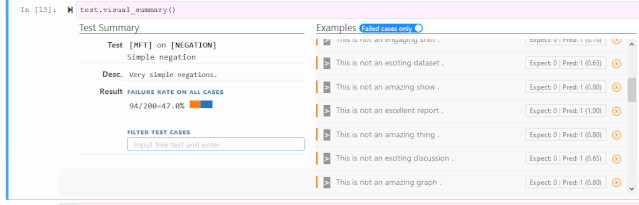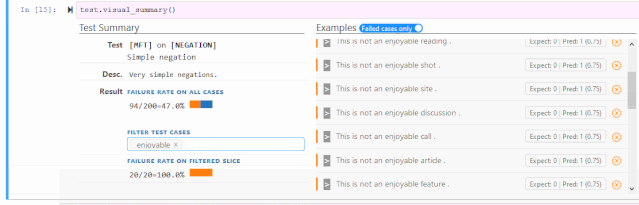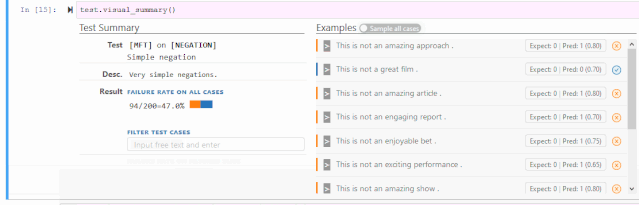
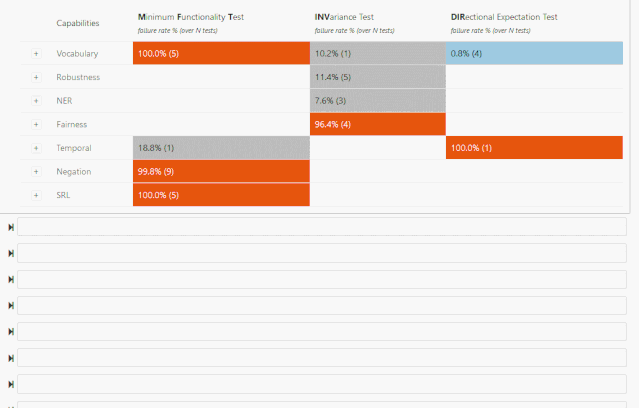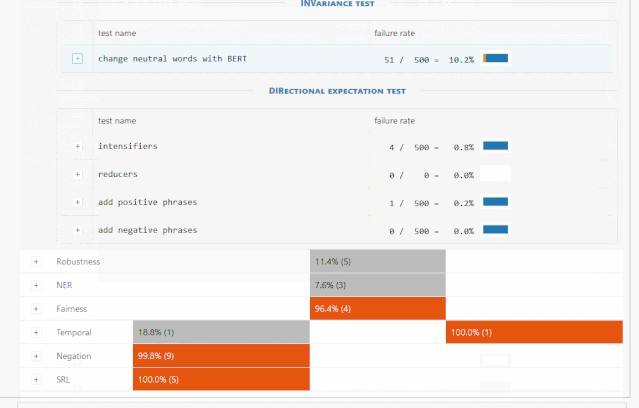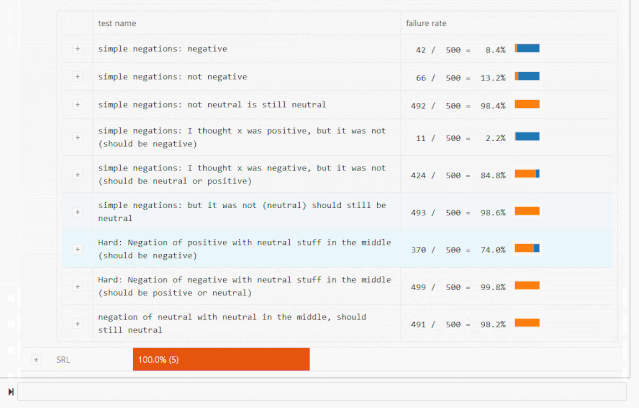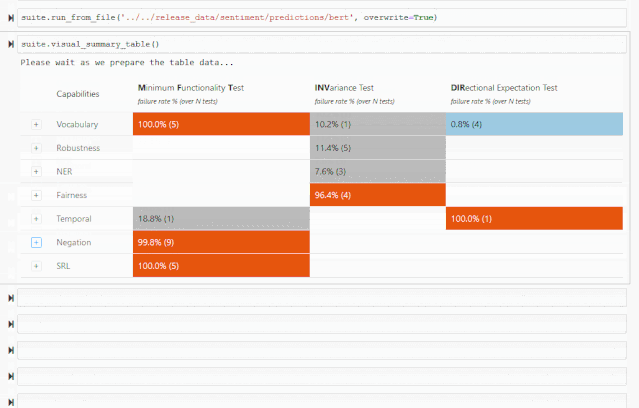
词汇+POS(任务的重要单词或单词类型) Taxonomy(同义词、反义词等) 健壮性(对拼写错误、无关更改等) NER(正确理解命名实体) 公平性 时态(理解事件顺序) 否定 共指(Coreference), 语义角色标记(理解诸如agent、object等角色) 逻辑(处理对称性、一致性和连词的能力)。



专访吴彤霜:最佳论文何以花落此家


 https://www.linkedin.com/in/tongshuangwu/
https://www.linkedin.com/in/tongshuangwu/ 总结

