ECCV2020 | 将投票机制引入自下而上目标检测,整合局部和全局信息


简介

本文的方法:oughNet: the method and the models
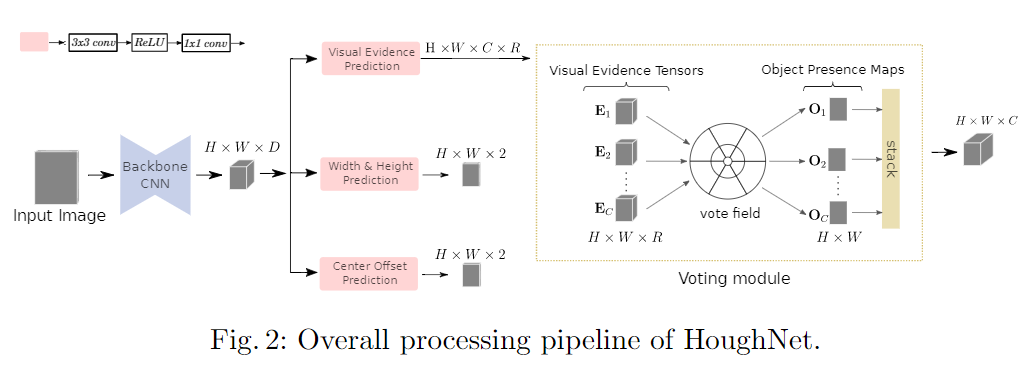
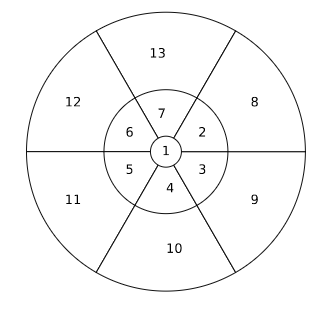

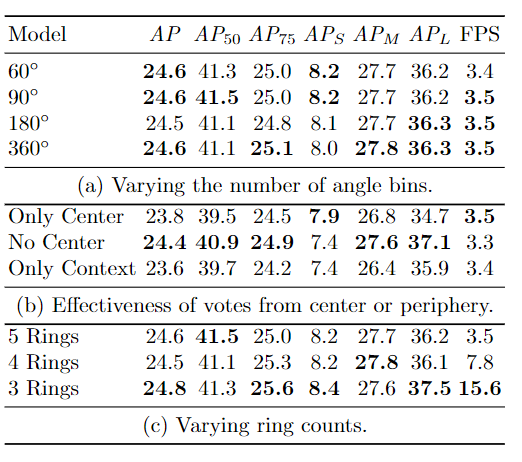
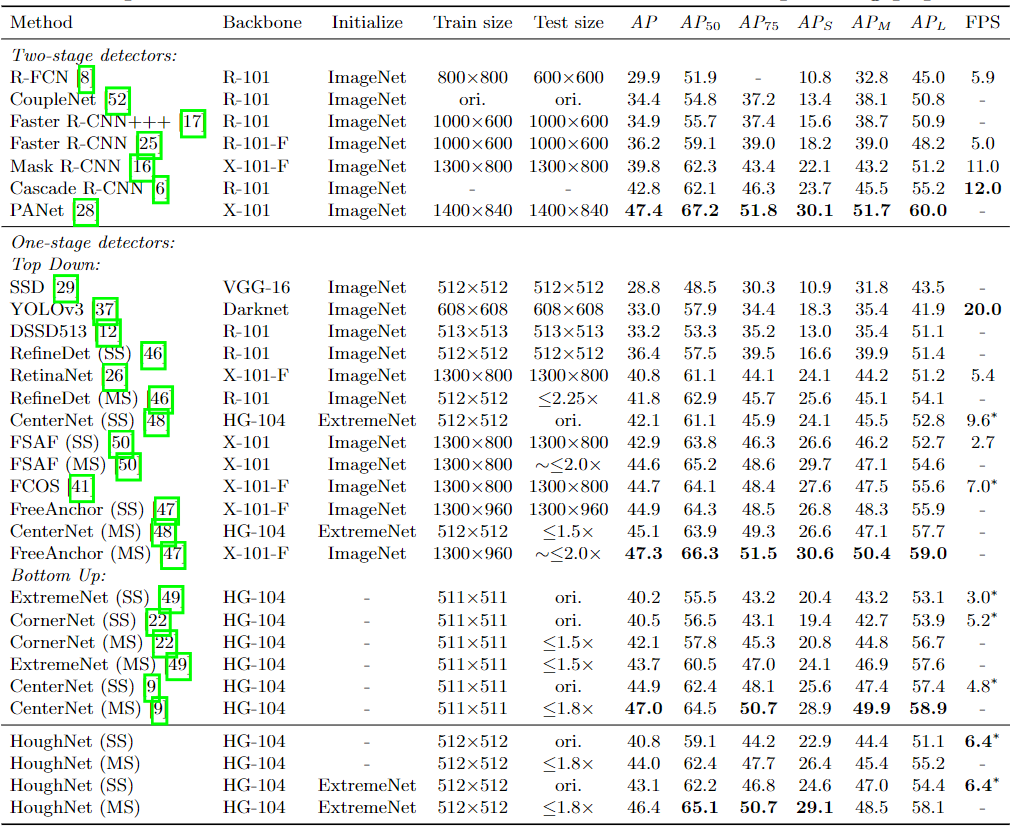
实验与结果

4、迁移实验

AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
