ECCV 2020 Oral | 当AI遇见三维时装: 来会会现今最大的三维服装数据集


ECCV 2020系列文章专题
第·1·期
福利来啦!
▼
你还知道哪些将AI用于时装行业的科研成果呢?


作者:CUHKSZ访问学生, 浙江大学硕士生 朱鹤鸣
论文:https://arxiv.org/pdf/2003.12753.pdf
近些年来,深度学习技术的发展,让基于图像的三维人体数字化领域有了前所未有的进展:通过一张图像作为输入,现有工作能够实现准确的估计三维人体姿态、恢复图像中非穿衣的三维人体模型。
然而,与开展的如火如荼的单张图像估计人体三维姿态、非穿衣人体形状相比,以单张图像作为输入,恢复图像中三维服装的研究进展相对缓慢。除去重建三维服装模型任务自身的难度外,另一个更重要的原因是研究领域内缺乏大规模的、包含现实中多种服装的三维服装数据集。相比二维服装图像能够通过网络进行高效的搜集,高质量的三维服装模型往往需要在实验室环境内,通过扫描、或多视角重建的方法才能获得;由于服装的形状具有极大的复杂性,从采集的三维人体点云剥离出边界分明的服装部分往往需要费时费力的人工操作,也进一步增加了建立大规模三位服装数据集的困难。
为解决现今三维服装数据集模型数量以及服装种类缺乏的问题,本文首先提出了现今最大的三维服装数据集Deep Fashion3D,该数据集在服装模型数目、服装种类以及服装标注多样性方面都胜于现有的三维服装数据集。
此外,为充分利用本文提出的Deep Fashion3D数据集,本文提出了一个新颖的单幅图像三维服装重建基准方法,实现了通过单张图像对Deep Fashion3D数据集中所有种类服装的三维重建。通过本文方法生成的三维时装模型相比已有的单视角三维重建方法,能够更加准确的恢复图像中人物穿着时装的宏观性状以及表面褶皱细节。
一、真实三维服装数据集 Deep Fashion3D
近些年来,随着各类电子商务平台以及社交平台的出现与发展,如Deep Fashion [9]、DeepFashion2 [8] 以及 FashionAI [7] 等大规模服装数据集被陆续建立起来。与此相比,真实三维服装数据集无论在服装模型数量还是在服装的种类方面都远远不足:现今最大的真实三维服装数据集MGN(Multi-GarmentNet) [2] 只包含穿有5类服装的共356个经三维扫描获得的真实三维穿衣人体模型,远远不足以训练一个具有较强表达能力的以单幅图像作为输入的三维服装重建模型。
为解决当前三维人体数字化领域真实三维服装数据集的缺失,本文首先提出了当今最大的真实三维服装数据集Deep Fashion3D,它具有模型数量多(相较现有的真实三维服装数据集MGN在服装模型数目上多一个数量级)、服装样式多(在服装样式方面包含最多种类的服装)、标注种类多(包含最丰富的服装标注)的特点。
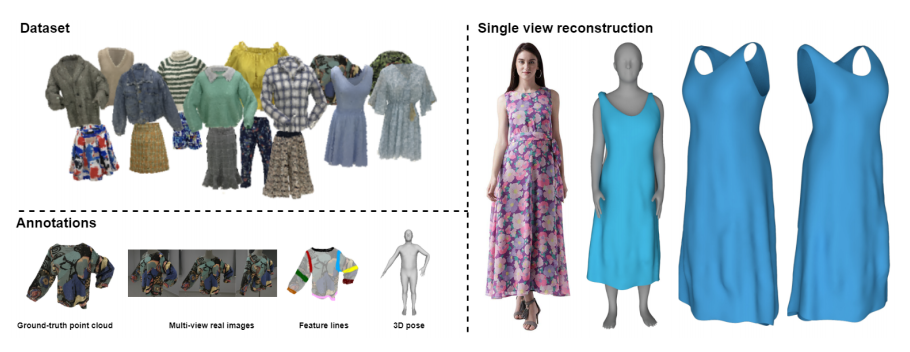
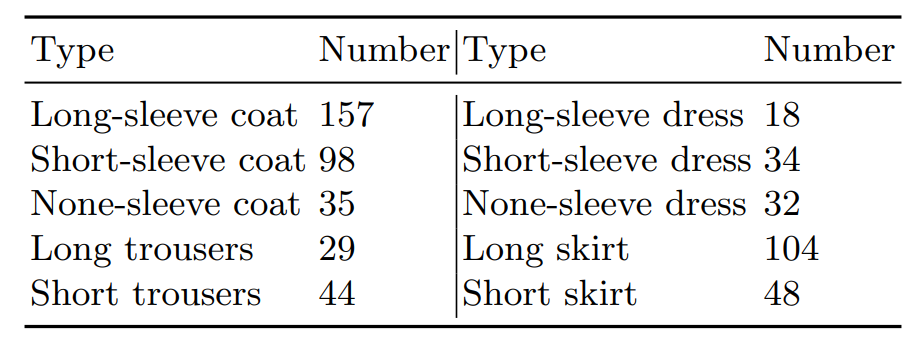
为体现现实世界中服装款式与种类的多样性,Deep Fashion3D采集了10个服装种类共563件不同的服装,数据集中包含的服装种类包括:长袖衫、短袖衫、无袖衫、长裤、短裤、长袖连衣裙、短袖连衣裙、无袖连衣裙、长裙以及短裙。对于每一件待采集服装,本文将其穿着于假人或真人模特身上,并摆出不同的动作以产生多样化的真实褶皱。最终,经过对每一件待采集服装进行姿态上的增强,一共563件三维服装模型通过上文提出的数据采集流程被重建出来。
为推动三维服装重建领域与分析领域相关的研究,研究团队在Deep Fashion3D数据集中加入了丰富的标注。Deep Fashion3D 数据集中的每一个三维服装模型都包括多视角真实图片、三维服装特征线以及三维服装姿态。
特别的,本文首次提出了三维服装特征线的标注方式。与人脸关键点相似,三维服装特征线展现了如服装开放边界、颈线、腰线、下摆线等服装最为显著的特征,能够为三维服装重建及分析等相关任务提供强大的先验知识。
除三维服装特征线外,Deep Fashion3D中每一个服装模型都标注有使用SMPL参数表示的三维服装姿态。由于三维服装的姿态与穿衣的三维人体具有很强的耦合度,三维服装姿态的提供能够在很大程度上帮助研究者研究三维服装网格与人体姿态相关的形变。

表2 三维服装特征线标注以及每一种服装包含的三维服装特征线
现今对研究者开放的三维服装数据集只有三个。相比现有的服装数据集,Deep Fashion3D具有更多的服装模型(模型数量多),以及远远超过其他三维服装数据集的服装种类(服装样式多)。
除Deep Fashion3D外,只有MGN数据集中提出的三维服装模型是由真实服装数据采集获得的,而另外两个数据集提供的服装模型都为合成数据。在数据集的标注方面,Deep Fashion3D对于每一件服装都标注有多视角真实图像、三维服装特征线以及三维服装姿态等标注,在标注种类的丰富性方面也远优于现有的三维服装公开数据集(标注种类多)。此外,Deep Fashion3D中首次提出了三维服装特征线的标注,为三维服装重建、分割以及检索等三维服装相关的推理任务提供重要的位置信息。
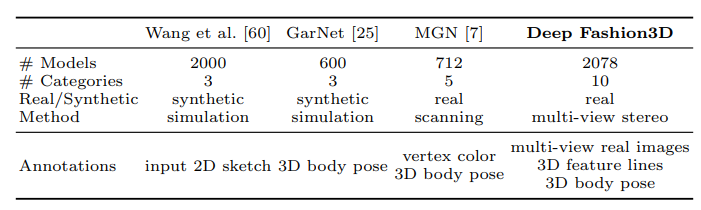
表3 Deep Fashion3D数据集与其他数据集的对比
二、单视角服装重建基准方法
为进一步展现Deep Fashion3D数据集的有效性,本文提出一种结合多种形状表示方式的方法,充分结合基于隐式曲面表达的方法对于三维服装表面细节的建模能力以及基于模版网格形变的方法对于开放曲面的建模能力。本文提出的单视角服装重建基准方法可被分为三个阶段:服装模板网格生成,特征线引导的网格生成以及拟合隐式重建的表面细化。
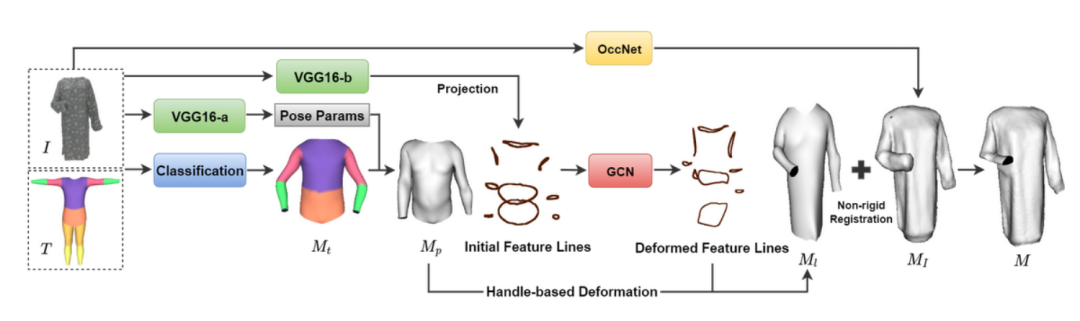
图1 本文提出的单幅图像三维服装重建流程图
本文提出了自适应三维服装模板,用于通过一个模板网格表示并生成Deep Fashion3D中所有种类的三维服装。在模型训练与计算的过程中,整个模板网格都模型的输入,使用自适应模板掩码控制每一个顶点的激活状态,用于表示不同种类的服装模板。只有模板顶点被激活时,该模板网格的顶点才会被用于网络参数的更新,并呈现于输出的三维服装网格中。反之,该顶点则不会被用于网络参数更新,也不会呈现在最终输出的三维服装网格中。
众所周知,服装的领口、袖口、下摆线等位置的三维服装特征线在展现服装的轮廓中起到决定性的作用。因此,本文首先根据输入图像,使用图像引导的图卷积神经网络(GCN)预测三维服装特征线的位置和性状,并以此作为基于手柄的形变方法(Handle-baseddeformation) 的硬性约束,将服装模板网格首先形变至与输入图像中服装宏观性状接近的形状。
在通过基于手柄的网格形变获得宏观形状与目标服装形状接近的平滑服装网格后,为在服装表面添加输入图像中服装的几何细节,最为直接的方法便是以三维服装模板网格作为Pix2Mesh算法的输入,预测模板网格上每一个顶点的偏移,生成具有丰富细节的三维服装表面网格。
然而,对比实验部分的结果表明,由于在保证生成服装模型表面光滑度的同时学习服装表面的高频几何细节的任务具有内在的困难性,通过Pixel2Mesh等基于网格表示的方法很难捕捉到服装表面褶皱等几何细节。与此相反,基于隐式曲面表达的三维重建方法OccNet [5] 能够忠实地捕获并重建输入图像中服装的高频细节,但只能够生成闭合的表面网格。因此,本文使用改进过的非刚性注册方法,将经过OccNet生成网格上高频细节迁移到特征线形变后的网格上,获得最终的服装网格输出。
三、结果与对比
本文将当今最为先进的8种单视角重建方法与本文提出的单视角服装重建算法进行比较。用于对比的8种方法包含基于网格、点云、体素、隐式曲面等不同的形状表示方法的单视角三维重建方法:PSG(Point SetGeneration),3DR2N2,AtlasNet,Pixel2Mesh,MVD (generating multi-view depthmaps),TMN(topologymodification network),MGN(Multi-Garment Net), OccNet(Occupancy Net)。
(1)基于点集、体素以及多视角深度图的方法很难生成光滑的表面;
(2)从固定模板形变的方法很难在正确拟合服装的宏观性状与生成丰富的几何细节之间取得平衡;
(3)基于隐式曲面的表达方法能够生成丰富的细节,但是它只能用于生成封闭的形状,很难被用于具有多个开放边界的服装网格的生成。通过显式的结合基于模版网格形变的方法以及基于隐式曲面的方法,本文提出的方法不仅能够准确的重建出服装的整体形状,也能生成丰富的服装表面细节。

图3 用于对比的单视角重建方法在Deep Fashion3D测试集上的重建结果,(j)列为本文的方法
希望进一步了解该工作的朋友点击下方视频,查看作者详解~
你还知道哪些将AI用于时装行业的科研成果呢?
我们将从中选出 3 位送出大红包一个~
更有机会与论文一作深入交流切磋哦!
//
关于团队:
该工作由香港中文大学(深圳)GAP实验室主导完成。GAP实验室取名于Generation and Analysis ofPixels, Points and Polygons。基于深圳市大数据研究院与香港中文大学(深圳),该实验室在韩晓光博士的带领下,致力于探索和解决图片、视频及三维内容的生成与分析方面的难题,其主要研究方向涵盖计算机视觉、计算机图形学和机器学习。
该工作主要由浙江大学的硕士生朱鹤鸣、西安电子科技大学的硕士生曹宇以及香港中文大学(深圳)的硕士生金航在GAP实验室完成。团队成员还包括北美腾讯高级研究员陈伟凯老师、中国科学与技术大学杜冬博士、浙江大学王章野副教授、香港中文大学(深圳)崔曙光教授。
GAP实验室主页:
常年招收优秀博士后、博士、硕士以及访问学生,简历请发送至
hanxiaoguang@cuhk.edu.cn
参考文献

将门ECCV 2020专题活动 ●●
// 1
// 2
为了让更多小伙伴的优秀工作拥有更大的展示舞台,本周开始,我们将不间断分享来自将门技术社区的群友们在本次ECCV中的优质工作,共计20期。欢迎中paper的小伙伴前往后台回复“ECCV”获取投稿方式!坑位有限,先到先得~
【预报名开启】
点击下方小程序报名
交易担保 报名工具丨活动接龙统计预约 【预报名】开启,抢占席位,刻不容缓 小程序


扫码观看!
本周上新!



来扫我呀
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
将门创新服务专注于使创新的技术落地于真正的应用场景,激活和实现全新的商业价值,服务于行业领先企业和技术创新型创业公司。
将门技术社群专注于帮助技术创新型的创业公司提供来自产、学、研、创领域的核心技术专家的技术分享和学习内容,使创新成为持续的核心竞争力。
将门创投基金专注于投资通过技术创新激活商业场景,实现商业价值的初创企业,关注技术领域包括机器智能、物联网、自然人机交互、企业计算。在近四年的时间里,将门创投基金已经投资了包括量化派、码隆科技、禾赛科技、宽拓科技、杉数科技、迪英加科技等数十家具有高成长潜力的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: bp@thejiangmen.com


将门创投
让创新获得认可!
微信:thejiangmen
bp@thejiangmen.com
点击“❀在看”,让更多朋友们看到吧~