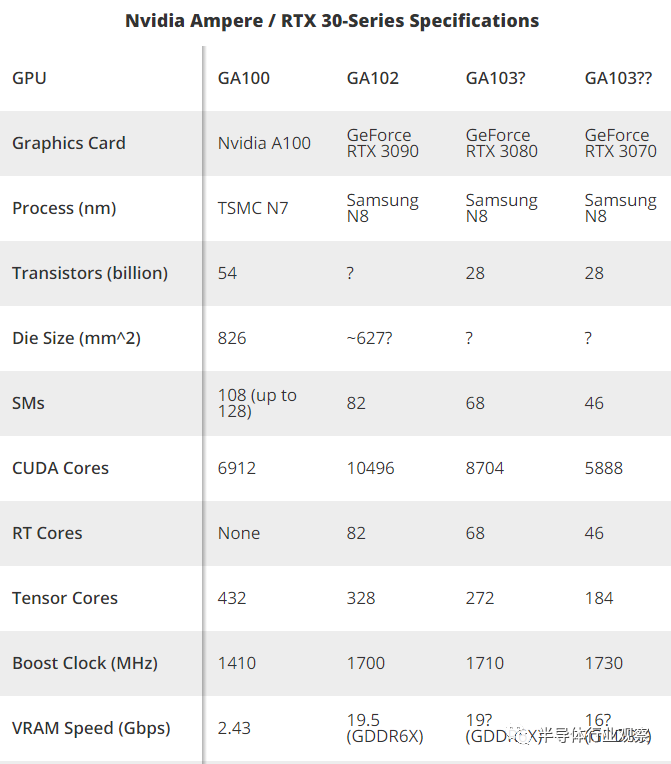
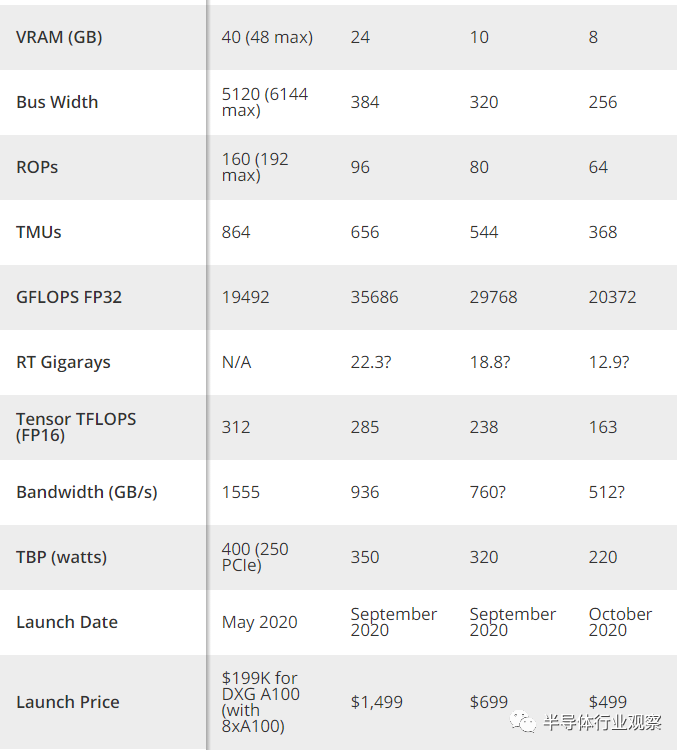
Ampere架构将为GeForce RTX 3090,GeForce RTX 3080,GeForce RTX 3070和其他即将推出的Nvidia GPU提供动力。它代表了Team Green的下一次重大升级,因为这次在性能上它有可能实现巨大飞跃。该显卡将于本月晚些时候上市,而3070要等到10月份。根据当前消息,这些GPU可以轻松迁移至我们的GPU层次结构的顶部,并将一些最好的显卡淘汰一两个。下文将详细介绍Ampere架构,主要内容包括规格,功能和其他性能增强。Ampere架构标志着NVIDIA的重要转折点。这是该公司的首款7纳米GPU,或用于消费类零件的8纳米GPU。无论以何种方式,制程减小都能使其在比以前更小的面积内封装更多的晶体管。它也是第二代消费者光线追踪和第三代深度学习硬件。较雄昂的制程为Nvidia极大程度上改进以前的RTX 20系列硬件和技术创造了条件。我们知道Ampere架构将在即将到来的GeForce RTX 3090,RTX 3080和RTX 3070显卡中得到应用(预计明年RTX 3060和RTX 3050发布)。它也是Nvidia A100数据中心GPUs的一部分,该GPUs是完全独立的硬件。在这里,我们将逐步分析Ampere体系结构的消费者和数据中心的变体,然后深入探讨其中的一些差异。Nvidia的Ampere GPU发布感觉就像是2016年的Pascal和2018年的Turing GPus的融合。Nvidia首席执行官黄仁勋(Jensen Huang)于5月14日发布了用于数据中心的A100,让我们了解到即将推出的产品的官方消息,但A100不是为GeForce卡设计的。A100替代了Volta GV100,而GV100替代了GP100。消费类模型具有不同的功能集,并由单独的GPU(如GA102,GA103等)提供支持。消费类显卡还使用GDDR6X / GDDR6,而A100使用HBM2。除了底层的GPU架构,Nvidia还改进了核心图形卡设计,重点放在散热和功耗上。正如Nvidia在视频中所描述,“每当我们谈论GPU性能时,其实就是在讲我们可以赋予和散去的功率,这种功率越大,性能就越好。”经过改进的散热解决方案,风扇和PCB(印刷电路板)都是改善Nvidia Ampere GPU整体性能计划的一部分。当然,第三方设计可以自由调整Nvidia的设计。随着台积电从12nm FinFET节点转移到台积电N7和三星N8,许多人期望Ampere在更低的功耗水平下提供更好的性能。与之相反的是,Nvidia以多多益善的方式采取了所有额外的晶体管并且提升功率(至少在产品堆栈的顶部是如此)。例如,GA100拥有540亿个晶体管,其方形芯片尺寸是826mm。与GV100相比,晶体管数量增加了156%,而die尺寸仅增加了1.3%。我们预计消费类GPU也会有类似的变化。虽然7nm / 8nm在相同性能下确实可以有更高的功率,但其在相同功率下也可以表现出更好的性能。Nvidia迈出了一步,并在更高的功率水平下提供了更高的性能。V100数据中心模型的功率是300W,而新发布的Nvidia A100则将其提高到400W。我们在消费者模型上得到了相同的结果。GeForce RTX 2080 Ti的功率为250 / 260W,Titan RTX的功率为280W。有传言称RTX 3090超越了它,并配备有历史最高的TDP,可用于350W功率的单个GPU(显然不包括A100)。这对终端用户意味着什么?除了可能需要升级电源以及在Nvidia自己的型号上使用12针电源连接器之外,还意味着性能的度量标准会做出相应改变。在我的印象中,这次是Nvidia性能上最大的单代提升。Nvidia表示,结合即将进行的体系结构更新,RTX 3080的性能是RTX 2080的两倍。如果这些工作负载包括光线跟踪和/或DLSS,那么差距可能会更大。值得庆幸的是,最终价格不会比上一代GPU差很多(这取决于定价的比较方式)。GeForce RTX 3090的首发价为1,499美元,创下了单GPU的 GeForce显卡的记录,有效取代了Titan系列。RTX 3080的价格为699美元,RTX 3070的价格为499美元,与上一代RTX 2080 Super和RTX 2070 Super保持相同的价格。Ampere架构是否价格公道?我们需要再作等待才能实际测试硬件,但是这些规格至少看起来非常有吸引力。Ampere GA100使Nvidia以前的GPU相形见绌,其晶体管的数量是GV100的2.5倍。(图片来源:Nvidia)Nvidia Ampere体系结构规格除了用于数据中心的GA100之外,Nvidia还计划在2020年至少再推出三个Ampere GPU。来年,可能还会有多达三个额外的Ampere解决方案,尽管这些解决方案尚未得到证实(也不再下表中)。规格最大并且性能最差的GPU是A100。它具有多达128个SM和6个8GB的HBM2堆栈,其中Nvidia A100当前仅启用108个SM和五个HBM2堆栈。未来的版本可能具有完整的GPU和RAM配置。但是,GA100不会像普通的GP100和GV100那样仅用作数据中心和工作站,而是成为消费类产品。如果没有光线追踪硬件,GA100不会像GeForce卡那样遥不可及(因为无需考虑大型裸片,HBM2和硅中介层的成本)。在把方向下调至消费者模型后,Nvidia进行了一些重大更改。我们还没有完整的外观,但是Nvidia显然使每个SM的CUDA内核数量增加了一倍,从而在着色器性能上取得了巨大的进步。有了GA102和RTX 3090,Nvidia可能会削减相对于GA100轴上两个SM集群,从而保留96个SM的最大配置。其中,RTX 3090仅启用了82个。HBM2和硅中介层也消失了,取而代之的是12个GDDR6X芯片。每个SM的CUDA内核增加一倍之后(相当于10496个CUDA内核),每个SM可能有两个支持FP64的CUDA内核。Nvidia去除了剩余的FP64功能,并在其位置添加了第二代RT内核。至于四个第三代Tensor核心,其中每个核心的吞吐量是上一代Turing Tensor核心的每时钟吞吐量的四倍。1700 MHz的boost频率可提供FP32计算性能的35.7 TFLOPS,而19.5 Gbps GDDR6X可提供936 GBps的带宽。大致来讲,RTX 3090的性能可能会是RTX 2080 Ti的两倍以上。值得注意的是,目前有一大批SM被禁用。将来是否会完全启用GA102的Titan卡?当然如此。也许它还将配备21 Gbps内存,并配上相应的高价。(友情提示:即便你壕气冲天,也不要为了游戏而购买Titan GPU。3-5%的性能提升绝对不值这个价。)相对于GA102,GA103做出了进一步修整。目前GA103有6个SM集群,最多72个SM。RTX 3080使用几乎完整的GA103,其有68个SM和8704 CUDA内核,而我们认为RTX 3070使用仅具有46个active SM和5888 CUDA内核的harvest芯片(可能是GA104,但这并不重要)。3080还具有10GB的GDDR6X内存和320位总线,而3070禁用了两个通道,最终在256位的总线上具有8GB的GDDR6内存。与前几代产品不同,所有三个RTX 30系列GPU的工作频率都较为相似:1700-1730MHz。从理论性能上讲,RTX 3080可以完成29.8 TFLOPS,并具有760 GBps的带宽,Nvidia表示它的速度是即将发布的RTX 2080的两倍。同时,RTX 3070提供20.4 TFLOPS和512 GBps的带宽。Nvidia表示RTX 3070的最终运行速度也将比RTX 2080 Ti快,尽管在某些情况下11GB与8GB VRAM相比,会让前重量级冠军略胜一筹。同样,架构上的改进肯定会有所帮助。A100是Nvidia有史以来规格最大的GPU,相比之下各种消费类芯片要小得多(图片来源:Nvidia)随着GA100和Nvidia A100的发布以及GeForce RTX 30系列的面世,我们现在对预期会有一个很好的了解。英伟达将继续拥有两条独立的GPU系列,其中一条专注于数据中心和深度学习,另一条专注于图形和游戏。数据中心GA100所做的一些更改会延伸至消费类产品线,但这并没有扩展到FP64的Tensor核心增强功能。这就是我们对Ampere架构始于GA100的了解。
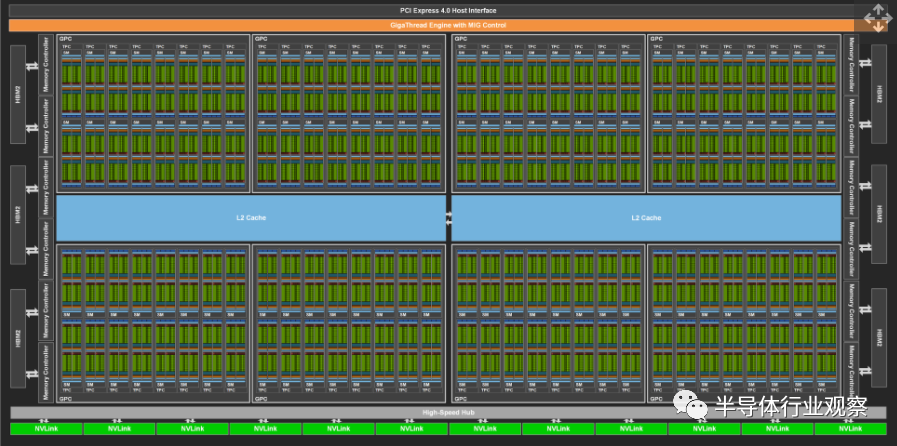
首先,GA100包含许多新内容。从较高的角度来看,GPU已从GV100中的最多80个SMs / 5120 CUDA内核增加到GA100中的128个SMs / 8192 CUDA内核。虽然核心数量增加了60%,但GA100使用的晶体管数量是其2.56倍。所有这些额外的晶体管都用于增强架构。如果您想深入了解所有细节,请查看Nvidia的A100 Architecture白皮书,我们只对其进行简要总结。GA100中的Tensor核心取得了最重要的升级。上一代GV100 Tensor内核在两个4x4 FP16矩阵上运行,并且可以计算两个矩阵的4x4x4融合乘加(FMA),每个周期具有第三个矩阵。每个Tensor内核每个周期可以进行128个浮点运算,而Nvidia将GV100评为FP16的125 TFLOPS峰值吞吐量。相比之下,GA100 Tensor内核每个工作频率可以完成8x4x8 FMA矩阵运算,每个Tensor内核总共可以进行256 FMA或512 FP(吞吐量是其四倍)。即使它每个SM的Tensor内核数量只有上一代GV100 Tensor内核的一半,但它仍然是上一代GV100 Tensor内核每个SM的性能的两倍。GA100还增加了对Tensor内核稀疏性的支持。该改进考虑到许多深度学习操作最终会产生一堆不再重要的加权值,因此随着训练的进行,这些值基本上可以忽略。稀疏性将Tensor核心吞吐量提高了一倍。FP16的Nvidia A100的额定值为312 TFLOPS,而有稀疏性支持的Tensor 内核则为624 TFLOPS。除了大幅提高原始吞吐量外,GA100 Tensor内核还增加了对更低精度的INT8,INT4和二进制Tensor运行的支持。INT8容许具有稀疏性的624 TOPS和 1248 TOPS,而INT4则将其翻倍,达到了1248/2496 TOPS。二进制模式不支持稀疏性,可能用途有限,但是A100可以在该模式下进行4992 TOPS。另一方面,A100中的Tensor内核也支持FP64指令。FP64的性能在19.5 TFLOPS时远低于FP16。但是,对于FP64工作负载,它仍然比GV100的最大FP64吞吐量快2.5倍。最后一点,A100添加了两种新的浮点格式。BF16(Bfloat16)已被其他一些深度学习加速器(例如Google的TPUv4)使用。就像FP16一样,BF16使用16位,但是使用8位指数和7位尾数进行转换,匹配FP32的8位指数范围,同时降低了精度。事实已经证明,这可以提供比普通FP16格式更好的训练和模型精度。第二种格式是Nvidia在Tensor Float 32(TF32)上的格式,该格式保留8位指数,但将尾数扩展到10位,使FP16的精度与FP32的范围相匹配。TF32的性能也与FP16相同,因此深度学习仿真的额外精度基本上是“免费”的。哇,这是一个具有公制对接晶体管的大芯片!(图片来源:Nvidia)Tensor的核心增强功能很多,这也表明了Nvidia在GA100上的重心。深度学习和超级计算工作负载的性能大大提高。GA100还具有其他一些体系结构更新,我们将在此处作简要介绍。SM晶体管的数量增加了50-60%,所有这些晶体管都必须放在某个地方。多实例GPU(MIG)是一项新功能。这使得单个A100可以划分为多达七个独立的虚拟GPU。每个虚拟GPU(使用Tensor操作运行推理工作负载)都可能与单个GV100的性能相匹配,从而极大地增加了云服务提供商的横向扩展机会。每个SM的A100 L1高速缓存大了50%,与V100上的128KB相比为192KB。L2缓存的增加幅度更大,从V100的6MB增加到A100的40MB。它还具有新的分区交叉开关结构,可提供GV100 L2缓存的读取带宽的2.3倍。请注意,总的HBM2内存“仅”从GV100的16GB或32GB增加到GA100的40GB,但是增加的L1和L2缓存有助于更好地优化内存性能。NVLink性能也几乎翻了一番,从GV100中的每个信号对25.78 Gbps到GA100中的50 Gbps。A100中的单个NVLink在每个方向上提供25 GBps的速率,类似于GV100,但每个链路具有一半的信号对。链接总数也增加了一倍,达到12条,从而使NVLink总带宽在A100下为600 GBps,而在V100下为300 GBps。此外还提供了PCIe Gen4支持,几乎使x16连接的带宽增加了一倍(从15.76 GBps到31.5 GBps)。最后,A100添加了新的异步副本,异步屏障和任务图加速。异步副本可提高内存带宽效率并减少寄存器文件带宽,并且可以在SM执行其他工作时在后台完成。硬件加速障碍为CUDA开发人员提供了更大的灵活性和性能,并且任务图加速有助于优化向GPU提交的工作。还有其他体系结构增强,例如NVJPG解码可加速JPG解码,以用于基于图像的算法的深度学习训练。A100包含5核硬件JPEG解码引擎,该引擎可胜过基于CPU的JPEG解码并减轻PCIe拥塞。同样,A100添加了五个NVDEC(Nvidia解码)单元,以加速常见视频流格式的解码,这有助于与视频一起使用的深度学习和推理应用的端到端吞吐量。介绍完了GA100和Nvidia A100架构之后,以下将介绍消费类GeForce RTX卡的Ampere架构变化。
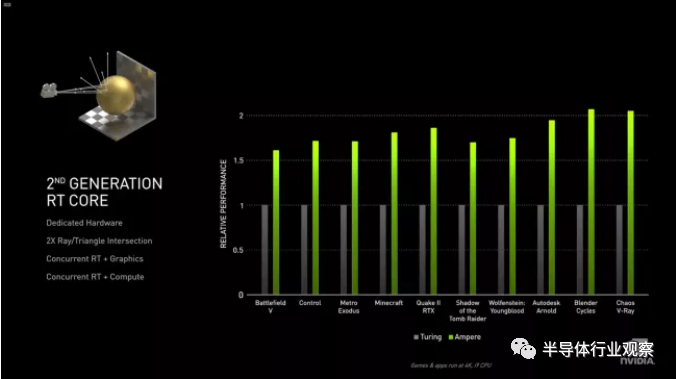
Nvidia GA102 / GA103 Ampere架构与GV100相比,GA100进行了大量更改,而在消费类方面,更新同样显著。以上对Tensor核心的许多更改都直接带入了消费类模型(自然很可能会减去FP64)。除了支持Micron的新GDDR6X存储器(而不是HBM2)之外,其他主要更改还包括光线跟踪和CUDA内核。Nvidia在2018年使用Turing架构和GeForce RTX 20系列GPU在光线追踪方面引起了很多争议。两年过去了……好吧,说实话:游戏中的光线追踪并没有真正发挥其潜力。《战地风云5》具有更好的反射效果,《古墓丽影》和《使命召唤》的阴影得到了改善,《地铁出埃及记》使用了RT全局照明,并且在每种情况下,性能的下降都使视觉效果有了相对较小的提高。迄今为止,关于光线追踪可以做什么,最好的例子可以说是“控制游戏”,该游戏使用RT效果进行反射,阴影和漫射照明。它看起来相当不错,尽管您可能抱有期望,但其对性能的影响仍然很大。究竟有多大呢?对于RTX 2080 Ti和Core i9-9900K,在1440p和最高质量下运行Control且没有光线追踪的情况下,其性能为80 fps(这是我们在本文中刚刚完成的测试)。打开所有光线跟踪功能之后,七性能降低到43 fps,慢47%,或基本上降低一半。尽管您可以通过启用DLSS 2.0来缓解问题,但该功能在质量模式下可渲染为1707x960,并可以放大到1440p。但这会带来一个痛苦的代价:性能降回72 fps。还有“全路径跟踪”的演示,其中硬件进一步推向了更高的位置。以Quake II或Minecraft之类的相对古老且低保真的游戏为例,再添加照明,阴影,反射,折射等全光线追踪效果。而且,结果可能是60 fps,而不是每秒数百帧。这还是在以至少1080p的RTX 2070 Super启用DLSS的情况(这已经到达质量水平)。或许有人认为光线跟踪效果对性能造成的损失太大, Nvidia应该反其道而行之。但是说这类话的人对Nvida不是很了解。据Nvidia称,GeForce 256是第一个GPU,它还将硬件转换和照明计算引入了消费类硬件。大多数游戏要几年后才能正确使用这些功能。第一批带有着色器的GPU早在数年之前就已经普遍使用该硬件,但是今天几乎所有发行的游戏都广泛使用了着色器技术。Nvidia认为光线追踪会有一个类似的演变过程。好消息是,采用Ampere架构的光线追踪性能正在迅速崛起。Nvidia表示,与RTX 2080 Ti的34 TFLOPS相比,RTX 3080可以进行58 TFLOPS的光线跟踪计算。换句话说,光线追踪的速度快了1.7倍。2080 Ti的光线三角相交计算速度达到每秒11千兆字节,因此RTX 3080可以达到每秒19千兆字节,而与以往的最佳纪录相比,RTX 3090将翻倍甚至更躲。这对光线追踪游戏意味着什么?我们会很快找到答案,但是根据我们从Nvidia那里听到的消息,我们将看到更多的游戏开发人员增加了光线跟踪效果。赛博朋克2077将具有光线追踪的反射,阴影,环境光遮挡等功能。像Control这样的游戏可能在启用所有光线跟踪效果的情况下运行,并且一旦启用DLSS,相对于传统渲染而言,其性能不会显著下降,甚至有可能会表现出性能提升。Nvidia还从其使用完整路径跟踪的Marbles技术演示中提供了上述指标。一个未命名的Turing GPU(RTX 2080 Ti?)那能够以720p和25 fps的速度运行Marbles,没有景深,只有一个圆顶灯和一个间接光。同时,Ampere(RTX 3090?)可以以1440p和30 fps的速度运行演示,并启用了景深和130个区域照明灯。结果是无论使用什么实际的GPU,都有可能将光线追踪提升到一个全新的水平。当然,这不仅与光线追踪有关。英伟达还在DLSS上加倍努力,而且由于拥有更强大的Tensor内核,所以质量和性能应该比以前更好。我们即将实现质量模式下的DLSS 2.0看起来比使用TAA或SMAA的本机渲染效果更好。不难想象,许多游戏玩家选择启用DLSS来获得健康的性能提升。由于Ampere对8K显示器具有本机支持,因此得益于HDMI 2.1,DLSS变得更加重要。什么样的硬件能够以绝佳的性能水平为8K提供动力?这很容易:打开DLSS并使用RTX 3090或RTX 3080以4K渲染。这是8K渲染吗?当然不是。但这是个无关紧要的问题。当然,8K显示器的价格仍然高得惊人,如果您坐在沙发上,几乎不可能看到4K和8K之间的差异。另外,如果您像我一样视力老化,那这种可能性为零。但是在家庭影院领域,营销力量很强大,因此我们可以肯定将来8K电视会以更大的推动力向前发展(这正是消费电子公司试图说服所有4K HDR电视所有者做出升级的方式)。
Nvidia Ampere架构:第二轮光线追踪
毫无疑问,现在使用Nvidia的RTX 20系列GPU的人会有一种受到欺骗的感觉。如果几个月前您没有收到我们所提出的关于等待购买新GPU直到Ampere发布的建议,那么看到RTX 30系列规格和Ampere架构可能会给您带来更大的损失。问题在于,我们始终知道这一天会到来。就像Turing取代Pascal,Pascal取代Maxwell,Maxwell又取代Kepler一样,GPU世界的迭代更新之路也在稳定发展。另一方面,如果您在过去几年中一直对游戏中的光线追踪持怀疑态度,Ampere可能最终会成功说服您尝试一下。然后您又拖一个月左右,想看看AMD的Big Navi表现。现实情况是,我们将看到更多支持某种形式的光线追踪的游戏,尤其是计划于今年秋天推出的下一代PlayStation 5和Xbox Series X控制台。我们有望在足够的硬件实力的支持下,游戏的光线追踪效果具有现实意义。可以肯定的一件事是:光线追踪不会消失。它几乎已经成为每部电影的重要组成部分,虽然目前还不是游戏与2020年好莱坞的电影竞争的时候,但他们也许可以追赶2000年代的好莱坞。目前,实时游戏通常希望每个像素仅使用几条光线,以更好地贴近现实光线的表现方式。相比之下,好莱坞每个像素可能使用数千条光线(或路径)。具有光线追踪硬件的GPU仍处于早期阶段,但是如果Nvidia(以及AMD和Intel)可以继续升级我们的GPU,那么游戏和电影之间的差距将只会缩小。Nvidia尚未透露所有关于Ampere架构更改的消息,因此我们后续将在了解更多信息后做出更新。看完有什么感想?
请留言参与讨论!

如侵权请联系:litho_world@163.com