AMD YES!背后不为人知的故事
EETOP专注芯片、微电子,点击上方蓝字关注我们

AMD YES是近年来比较火的一句话,每当EETOP发布关于AMD的相关文章,也总会收到网友的AMD YES!的留言。从字面翻译过来就是AMD真好,AMD真香的意思。AMD YES实际上表示了AMD近几年来逐渐走向成功,也得到了大家的认可。
那么为什么AMD 能达到今天的高度?最主要的功臣应当归功于AMD Zen架构的成功。今天我们就为大家扒一扒AMD Zen 成功背后不为人知的故事。
以下内容来自中国台湾科技新报的专栏作者:痴汉水球的文章。
正文:
自从2017 年AMD 准时推出「技术规格看起来稍微正常点」的Zen 微架构CPU 后,总算脱身逃离了2011 年以来推土机(Bulldozer)家族4 年工地秀的泥沼,回到跟英特尔正面对决互殴的擂台,而2019 年7 纳米制程的Zen 2,在英特尔2015 年后就挤牙膏挤到青黄不接的当下,更让AMD「稍微」重现了十多年前K8 时代的辉煌。这些各位读者都很熟悉的故事,就无需浪费篇幅锦上添花──即使背后充满看不见的波涛。

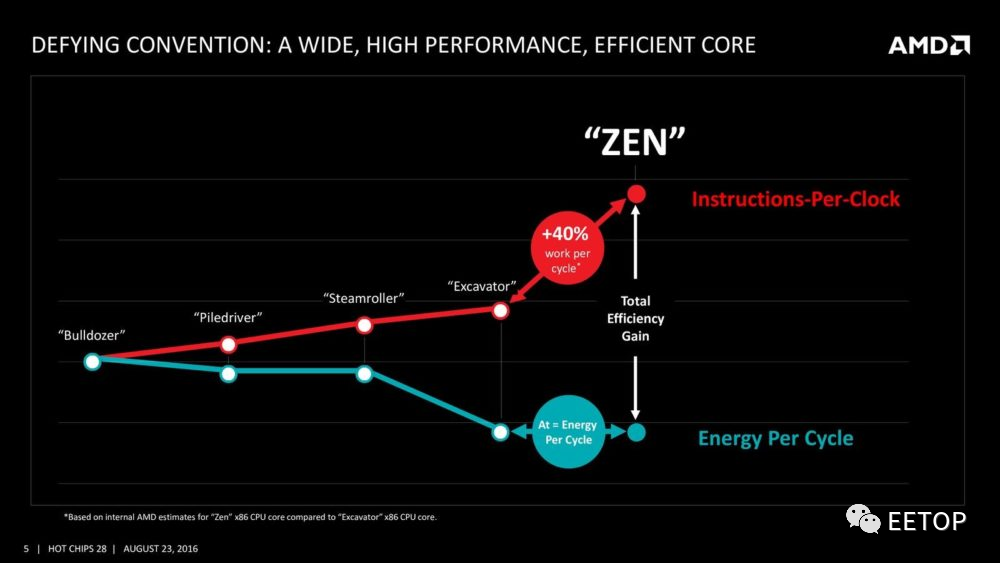
俗语说得好,失败为成功之母,任何成功都建立在一路累积的基础上,AMD 亦不能免俗,让 Zen 成功的一切条件,无不是奠基于过往的遗产与教训。我们就由远到近,一步步抽丝剥茧,重新踏上这条 AMD 走了25 年的漫漫长路。
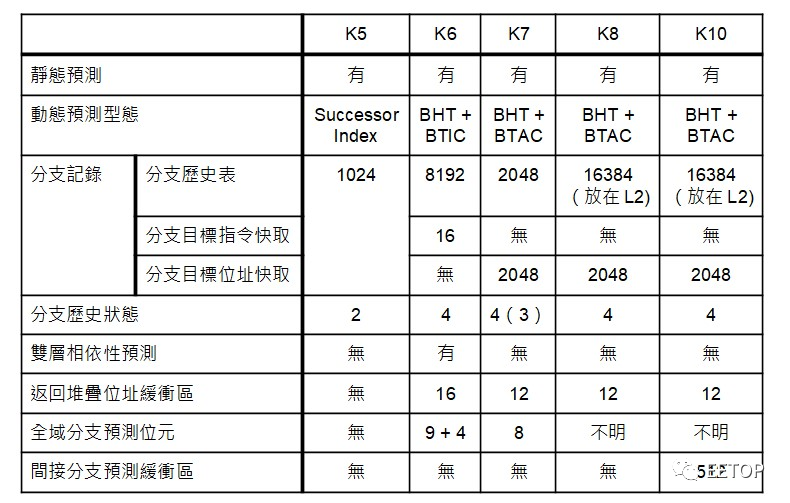
Zen 才是真正的 K10
AMD CPU 代号的 K 源自「(IntelPentium)Killer」,众人皆知的 AMD 高效能 x86 CPU 演进如下(不包含小核心 Bobcat 体系):
K5(1996):由超标量(Superscalar)架构大师Mike Johnson亲自操刀的「Pentium Killer」,但英特尔并未开诚布公的公开Pentium新增指令细节,为了确保与100%跟Pentium相容,逆向工程搞了很久,上市日期一再推后,让痴痴等待的Compaq等的“花儿也谢了”。 K6(1997):直接购并NexGen,修改现成的Nx686,取消类似Pentium Pro的L2 Cache专用总线,到内建L2 Cache的K6-2+和K6-III才算大功告成,但已时不我与。 K7(1998):出身DEC Alpha团队的Dirk Meyer变成的「x86世界的Alpha 21264」,AMD首次能与英特尔全面性较量效能。 K8(2003):Fred Weber主导的K7强化版+x86-64+服务器等级的RAS(Reliability, Availability and Serviceability)+HyperTransport+整合型存储器控制器,让AMD悲愿成就,一举攻入高获利的企业服务器市场。 K9:英文发音近似「狗」(Caine),太过负面,因此没这个代号。 K10(2007):4~6核K8强化版+整合式L3 Cache存储器,AMD开始「包水饺」两颗打一颗,也逐渐无力抵抗英特尔小步快跑的钟摆(Tick Tock)攻势。 K11(2011):由IBM Power4的总工程师Chuck Moore操刀,接连四代被英特尔钟摆痛扁的「推土机」(Bulldozer)家族,丛集式多执行绪(CMT)和模组化浮点运算器暗藏了AMD对Fusion大战略的熊熊野心与对未来GPGPU局势的离谱误判。 K12(预定2017):从头到尾搞笑的「全新高效能64位元ARM处理器」,还没开始就结束了,只活在简报里,无愧当时「简报王」名号。 Zen(2017):深度流水线、追求高时钟频率、同时多执行绪(SMT),根本是Andy Glew原先的K10原案投胎转世。
总之,严格说来,Zen 才是「真正的 K10」。这句话你可以仔细再看一次,我会等你。
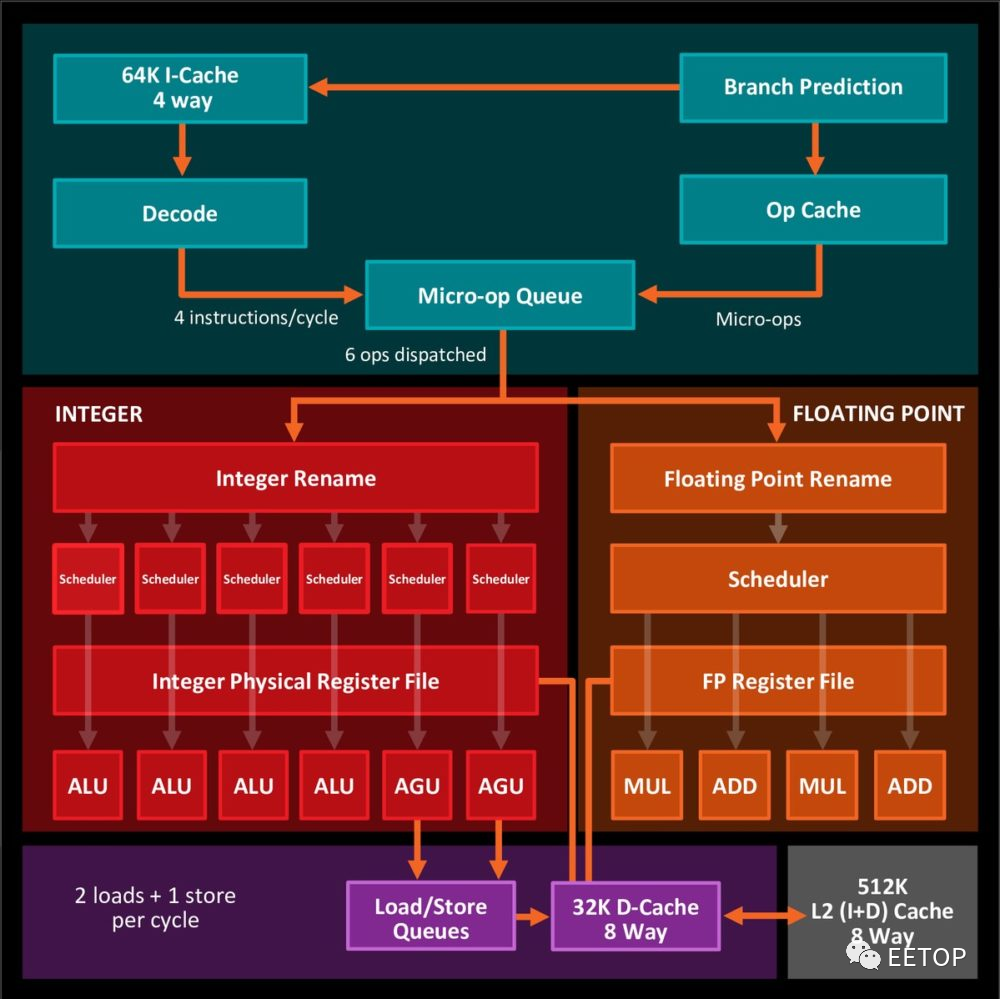
1990 年代初期创造英特尔革命性P6 微架构5 位总工程师之一的Andy Glew,对英特尔内部提议代号「Yamhill」的64 位元x86 指令集被拒绝,2002 年跳槽到AMD 参与x86-64指令集的制定工作,并短暂担任K10 总工程师。为何说「短暂」?他老兄原本提案的K10 是类似英特尔NetBurst 的设计:深度流水线、追求高时钟频率、未牺牲执行单元宽度、同时多执行绪(SMT),然后就又被打枪了,只是这次动手的换成AMD 高层。
他老兄一不爽,又在2004 年跳回前东家英特尔,但恐怕运气一直不太好,加入因太过「史诗级灾难」(单核心晶粒面积213mm² 几乎是Prescott 两倍,TDP 又超过150W上看166W)而惨遭腰斩的Tejas 开发案。2009 年再度离开英特尔,历经 MIPS 和 nVidia。瞧瞧LinkedIn 的个人介绍,现在正待在搞 RISC-V 的SiFive。

为何真正的 K10 会沉寂这么久才浮上台面?这跟 AMD 研发能量明显远不及英特尔、难以承担精密复杂的微架构有很大关系,一颗当两颗用的SMT 并不是便于开发验证的东西。据 AMD 在 1998 年申请的几份专利文件,原始K8 有两版,共同点只有一个:两个简单的「外宽内窄」小核心,明眼人脑中应该马上浮现推土机的雏型了。
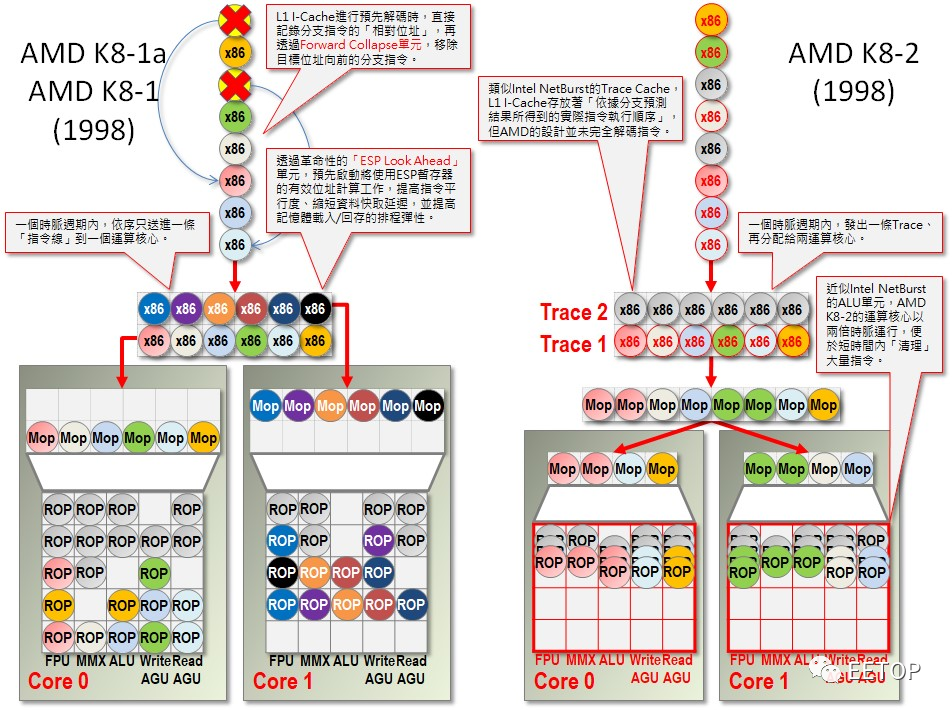
但AMD 大概是靠K7 和K8 日子过太爽了,遑论K8 让AMD 大举入侵高利润、市场动量又很持久(意思是产品暂时输人,也不会很快被赶出来)的服务器市场, 「先讲求不伤身体,再讲求效果」的维稳心态作祟,或在2006 年7 月耗费54 亿美元购并ATI 这件事,烧了太多钱,不得不节约研发经费,迟迟不见全新后继接班人。
此外,AMD 融合 CPU 和 GPU 的「Fusion 大战略」(The Future Is Fusion)也影响了 CPU 发展策略。AMD 过度乐观预期GPU 的泛用化进程,认定假以时日GPU 将可取代CPU 的浮点或部分SIMD整数运算,让推土机变成依附Fusion 的附庸,摆明当「天时、地利、人和」三者兼备时,直接用GPU 换掉两个简单整数运算核心共用的浮点运算器。
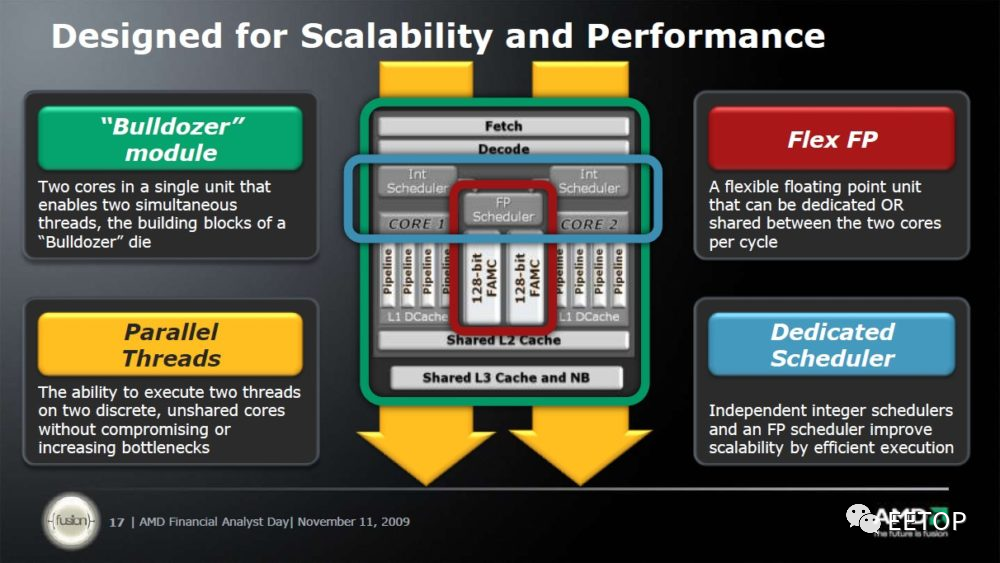
不过推土机在商业竞争失败,并不代表对之后Zen 的成功毫无贡献,除了让AMD 得到足够「不能乱搞流水线前端」的教训,让分支预测与指令流水线拖钩的解耦式分支预测器( Decoupled Branch Predicator)是支撑Zen 效能竞争力的一大功臣,甚至是Zen 2 可实做「机器学习分支预测器」的地基。各位别急,后面会提到。
反过来利用晶圆代工商业模式来提高晶体管密度与生产良率
AMD 创办人 Jerry Sanders 有一句名言「有晶圆厂才是真男人」(Real men have fabs),在今日真是莫大的讽刺。
虽然像英特尔和昔日AMD 的高度垂直整合IDM(Integrated Design and Manufacture)商业模式,可确保设计和制程彼此最佳化,但在追求Time To Market 的世界,专业的无晶圆厂IC 设计公司(Fabless IC Design House)、IP 授权提供者、电子辅助设计工具(EDA Tool)与晶圆代工业者(Foundry)的高度分工,却更能藉由成熟的「研发供应链」互通有无,沿用早被诸多客户千锤百炼的晶圆厂制程参数、现有IP 功能模组和函式库,迅速完成产品的开发与验证,并缩短时程降低成本。
SPARC 两位要角之一的Fujitsu,会在新世代HPC 产品A64FX 转向ARM 并交由台积电7 纳米制程代工,其因在此,光曾被苹果和众多客户「严刑拷打」的宝贵经验,对尽快搞定产品绝对是重中之重的无价之宝。
这件事也发生在放弃自有晶圆厂的 AMD。K11 时代,AMD 反过来利用晶圆代工生产GPU 的高密度函式库和自动化设计工具,砍掉多达30% 的CPU 芯片面积与耗电量,特别是过往「动用大量人力手工布线才能电路最佳化」的功能单元,如复杂的浮点运算器。「GPU 的电路设计最佳化程度优于 CPU」这档事,在21 世纪初期的 AMD 连想都不敢想。

这些经验和努力,对 Zen 的成功绝对举足轻重。就商业角度来看,这也让AMD 未来保有开发新型商业模式的弹性,中国中科海光(Hygon)的Dhyana 就是采用授权的Zen 核心,当然美国政府愿意「乐观其成」那又是另一回事了。
「RISC86」与4 道 x86 指令解码的先行者
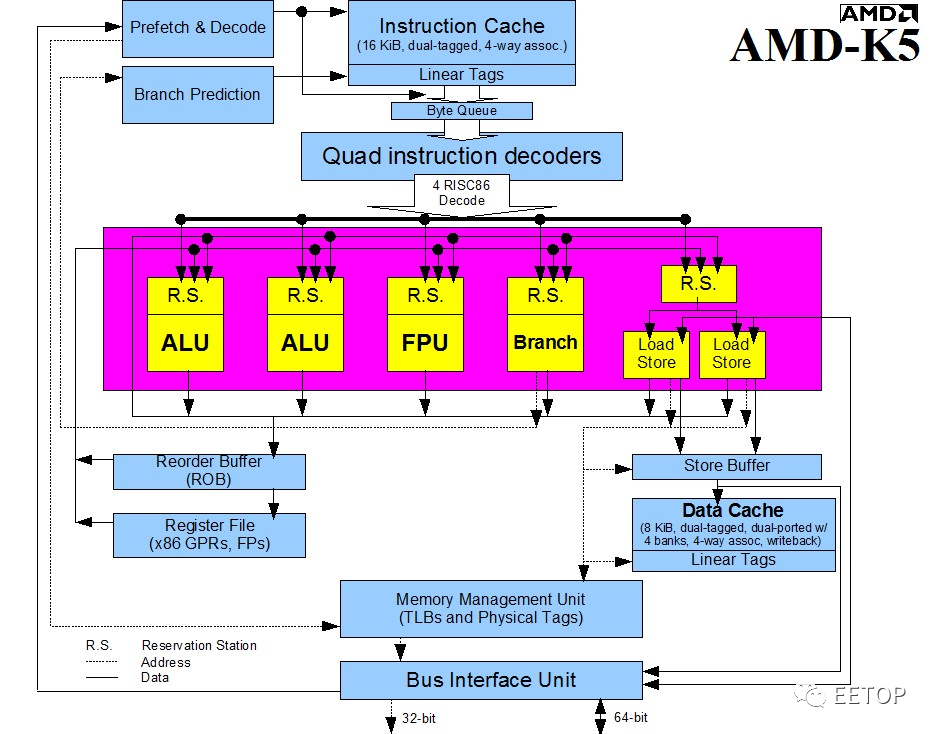
将指令格式与定址模式复杂到让人头痛的x86 指令,在指令解码阶段「转译」成一至数个固定长度、格式简洁的「类RISC」微指令(Microinstruciton),以简化处理器执行单元与数据路径的设计,利于提升时钟频率,并「将晶体管预算砸在最值得被加速的简单指令,不常用到的复杂指令,就用微码(Microcode)ROM 产生ROP 微程式慢慢跑」,已是20 年来x86 CPU 的共同特色,超标量架构大师Mike Johnson 领衔的K5 则是先驱(如果不限超标量,NexGen Nx586 则稍早),将非固定长度的x86 指令解码成平均59 Bits 长的ROP(RISC86Operation,发音是「ar-op」)。
AMD K5 还有个值得纪念之处:x86 史上首款单一核心最多可同时解码4 个x86 指令的CPU,下一款是相隔近十年的英特尔Merom 了,不提尴尬的K11,AMDZen 更晚了自家「前辈」超过20 年。
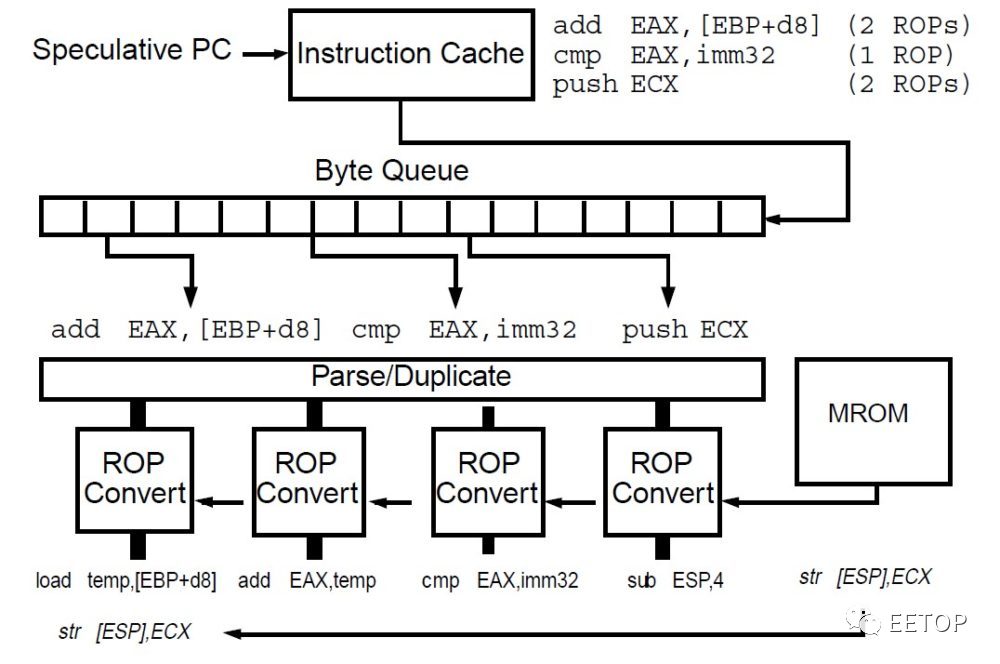

强化非循序指令执行效率的两段式微指令转译与「类VLIW」的微指令派发
x86 CPU 的指令解码器将x86 指令转成微指令,看起来好像很美好,但随着CPU 可同时非循序执行的指令数量越来越多,「微指令洪灾」就变成大麻烦,需要复杂的功能单元与相对应的电路成本,监控管理一海票微指令的生老病死与相依性,这也不利减少CPU 功耗。
在这就非得岔题谈一谈「首款双核心服务器CPU」的IBM Power4 了,为缩减指令控制逻辑的复杂度,Power4 一次将5 个解码后的指令「打包」成一个「一个萝卜一个坑、每个指令垂直对应一个执行单元」的超长指令(VLIW)包(一时脑筋转不过来,可想一下AMD GPU 以前的VLIW5),里面5 个指令全部执行完毕才能退返(Retire),控制逻辑单元只需管控相当于100 个指令的20 个指令包,这让Power4 这部分电路规模只有前代Power3 的一半,且更便于拉抬CPU 时钟频率。

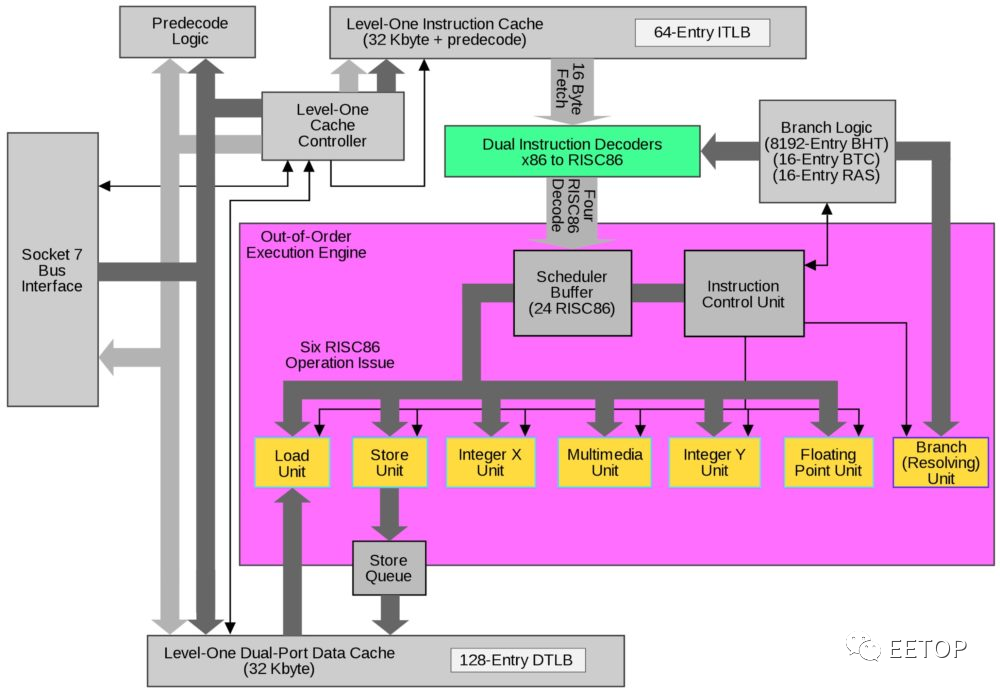
AMD 则是从K7 开始两段式微指令转译,指令解码器先将x86 指令解码一至两个MOP(Macro-Operation),到了内部要在指令保留站(Reservation Station)「派发」(Dispatch)到执行单元前,再拆成更小的uOP(发音「ur-op」),接着才「真枪实弹上阵」,避免一开始就把微指令拆光光,淹没指令管理单元,也变相将指令解码器的复杂度分散到「大后方」。
关于无法直接用「Fast Path」指令解码器处理成 MOP 的复杂指令,由「Vector Path」的微码 ROM 产生一系列MOP 微程式。前面就提过,所谓「RISC86」真正的精神就如同 RISC:把经常用到的情况尽可能加速(Make The Common Case Fast.),将最佳化资源集中在最常碰到的刀口。
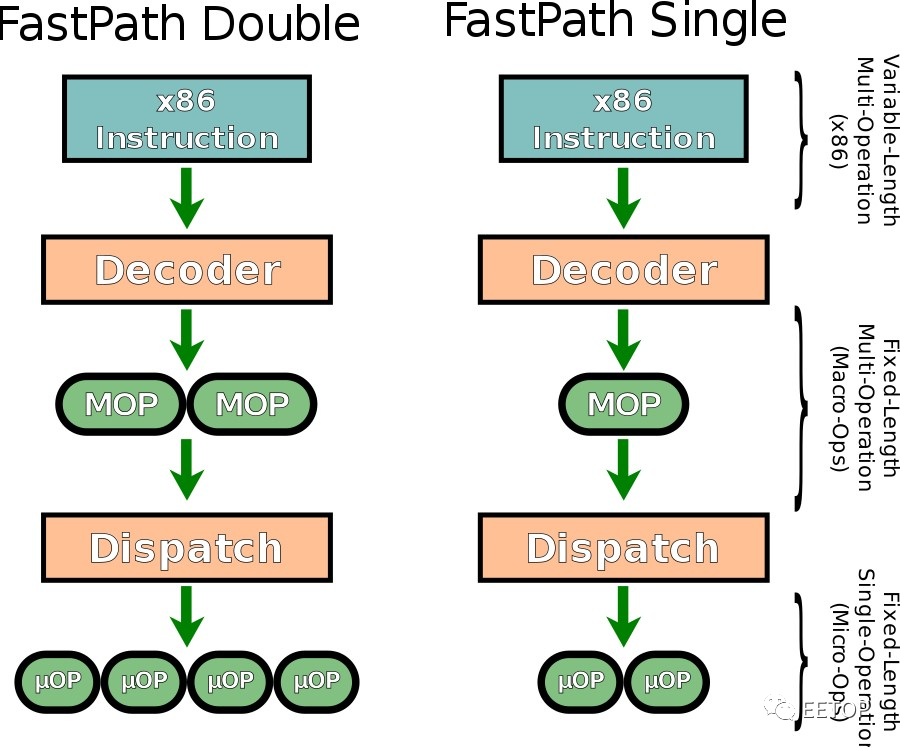
同期英特尔的手段就让人莞尔,起源于Pentium M 的「Macro-Fusion」,英特尔直接藉由增加指令保留站的运算元数量,削减CPU 内部微指令的总量,例如用一个三运算元(a =b+c)微指令代替两个(a=a+b),说穿了也称不上什么「融合」,或还不如说「本来就应该这样做」更贴切。
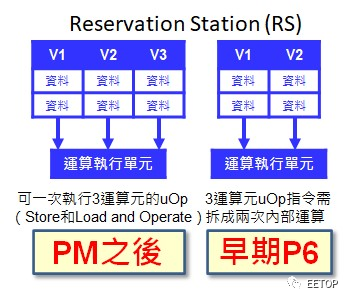
相对英特尔从Merom 开始,指令保留站某些Port 挤满了一堆不同性质执行单元的「爆浆撒尿牛丸」样貌,AMD 那「整数浮点一边一国的简洁风」在「简单就是美」的推土机展露无疑,非常「VLIW」,就算没有像IBM Power4 那样「指令打包送快递」,但看在总工程师都是同一位如假包换的Chuck Moore 份上,企图简化复杂度以追求更高运作时钟频率与更高投资效益的意图是一致的。
尽管推土机家族的下场不是太好看,但类似理念也同样被Zen继承,反正各位只需了解一个残酷的现实:毕竟AMD 的研发能量远不如英特尔,不见得有雄厚本钱采取过于精密复杂的架构风格,此类「穷人思维」在AMD CPU 发展史上无所不在。

众里寻他千百度才秾纤合度的分支预测
「电脑」(Computer)和「计算器」(Calculator)的不同点在于:电脑具备「条件判断」的能力,依据不同条件,执行不同指令流。各位可将电脑程式的运作流程,想像成一个「棋盘」,以一个角落为起点,对角线的角落当终点,在棋盘上反覆移动,不限制前进或后退。如发生条件判断的分支(Branch,必须先等待条件判断的执行结果,才能判定该分支「发生」),或无条件判断的跳跃(Jump),就会变更指令流,并中断指令流水线运作,尤其前者伤害指令流水线化的CPU 效能,才需要「以古鉴今」的分支预测(Branch Prediction)技术。
「过犹不及」的「分支预测」一向公认是AMD 落后英特尔的技术弱点,到了 Zen 才改观。贾谊〈过秦论〉那句意谓秦始皇继承六代功业的「奋六世之余烈」,套用到Zen看似突破性的分支预测技术,实在再适合不过了,在Zen 之前,刚刚好也是6 世代:K5、K6、K7、K8、K10、K11,有够巧。
因 K11 的分支预测技术和前代相比简直彻头彻尾大相径庭,故不列于下表。
一般我们谈到的是「动态」分支预测,透过小型化 Cache存储器,记录分支行为的历史,并随时搜集各类参考资讯,动态的修正预测的结果。近年来拜「CPU 安全漏洞」所赐,「预测执行」(Speculative Execution)、「非循序执行」(Out-Of-Order Execution)和「分支预测」等技术名词,变得非常热门也经常混淆。
各位只要记得,对近代高效能CPU,「预测执行=分支预测+非循序执行」,CPU 根据分支预测的结果,先斩后奏「赌博」性执行指令流,再藉由非循序执行引擎维护指令执行顺序的一致性,以及当预测错误时,回复该分支前的处理器状态。
分支预测究竟有多重要?假如有一颗CPU 没有任何分支预测机制(或说有,但总是预测错误),当执行分支指令时,直到目标指令被撷取,所需要的时钟频率周期数「分支伤害」(Branch Penalty)是3 个时钟频率周期,分支占了程式码五分之一,那会损失多少效能?
我们就可简单推算出,平均执行每个指令都会多出 0.6 个时钟频率周期,等于增加60% 执行时间,执行效能仅剩下 62.5%。
很不幸的,这个简单的案例还真的有倒楣的苦主:AMD K5的初版「SSA/5」(PR75 到PR100),因不明原因,分支预测功能被关闭,还「附赠」奇怪的CPU 闲置状态,「完全体」5K86(PR120 到PR200)的同时钟频率效能就硬是多了整整30%。让人极度好奇,假若 Compaq 知道他们死撑着不用 Pentium,只为了等待这样的产品,会做何感想。
K5 的分支预测超级阳春,准确率仅75%。当连续执行分支指令时,等于每道指令平均多 0.75 个时钟频率周期,沿用上面「分支占五分之一」的算法是 0.15,效能仅剩 87%,怎么看分数都不及格。但这时各位也应心知肚明,后期 K5 多出来的 30% 效能大致上是怎么来的,分支预测的确发挥了关键性作用。
购并NexGen 而来的K6 却是AMD 史上罕见的「过度投资」,和K5 同为六阶流水线、但最多只能解码两个x86 指令的K6,在分支预测暴力到整个过头,足以傲视AMD 历代CPU架构,但这是天大的浪费,况且分支预测越复杂,发生错误的回复时间也就越长,K6 的错误代价就硬比K5 多出一到两个时钟频率周期(3 vs. 4 或5 )。
K6 的分支预测准确率号称高达95%,我们可推算出执行每个分支指令只会多出0.2 到0.25 个时钟频率周期,「分支占五分之一」就0.04 到0.05,效能维持在95%到96%,远胜过K5。
不知道是不是针对K6「过度投资」的反动,或是觉得过于复杂的分支预测只会带来反效果,AMD 在1998 年MicroprocessorForum 揭露K7 的神秘面纱时,最让人意外的不是和DECAlpha 21264 如出一辙的「体格」,而是「Long Pipeline, But SimpleBranch Predictor」。
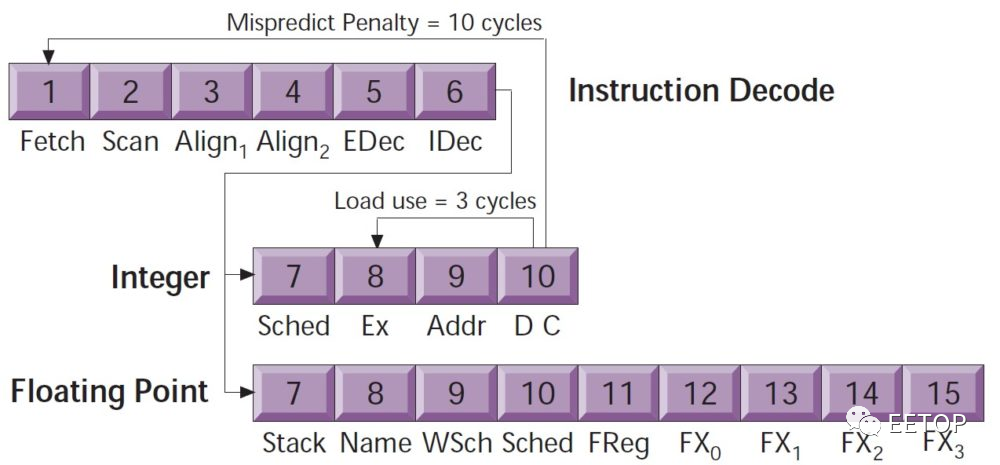
面对外界种种质疑,AMD 坚持「更精确的分支预测器只会带来更复杂的设计、更多的预测时钟频率周期与回复效能损失」,还更大胆的将标准的2 位元Smith 演算法4 种状态,砍成只剩下3 种(将Strongly not taken 和Weakly not take 合为一种not taken)。对照K7 压倒性的庞大执行单元,在这种小地方偷工减料,真的是莫大讽刺,但更扯的还在后头。
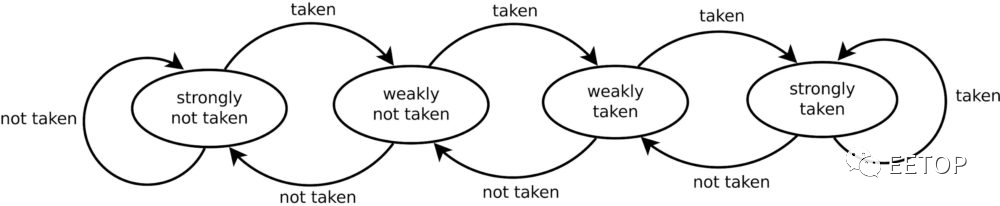
演进自K7 的K8 与「压榨K8 剩余价值」的K10,指令流水线更深,没有摆烂装死的借口,乍看之下「知耻近乎勇」亡羊补牢,但却很精明的利用「L1 / L2 互斥性 Cache(ExclusiveCache)」的特性,趁着数据从L1 指令 Cache「被驱逐」(Evicted)写入L2 Cache时,将分支选择器「偷放」在L2 Cache存储器包含指令的 Cache区块之ECC 栏位,「节俭」至此,堪称一绝。
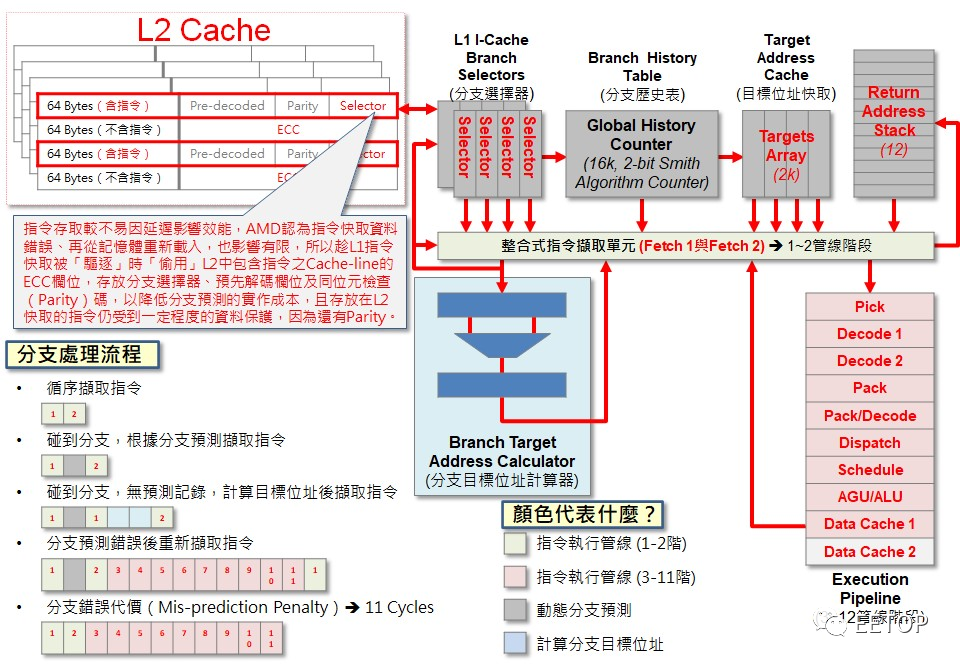
受制于不佳的分支预测精准度与「连如此简单的整数核心都喂不饱」的L1 指令 Cache存储器,甚少人注意到指令流水线深达20 阶的K11,解耦式分支预测器(DecoupledBranch Predicator)早已默默为Zen 2 的「机器学习分支预测器」TAGE(TAgged GEometric)分支预测器预先埋好了路基。

相近于今日少为人知的Rise mP6,K11 不等发生指令 Cache误失才去抓取目标指令,推土机的分支预测机制与指令撷取「脱钩」,主动标定分支预测目标的相对位址,如不存在于指令 Cache内,就「主动出击」预先撷取,可掩盖发生 Cache误失时的延迟,并替更耗时的机器学习分支预测器「争取训练的时间」。
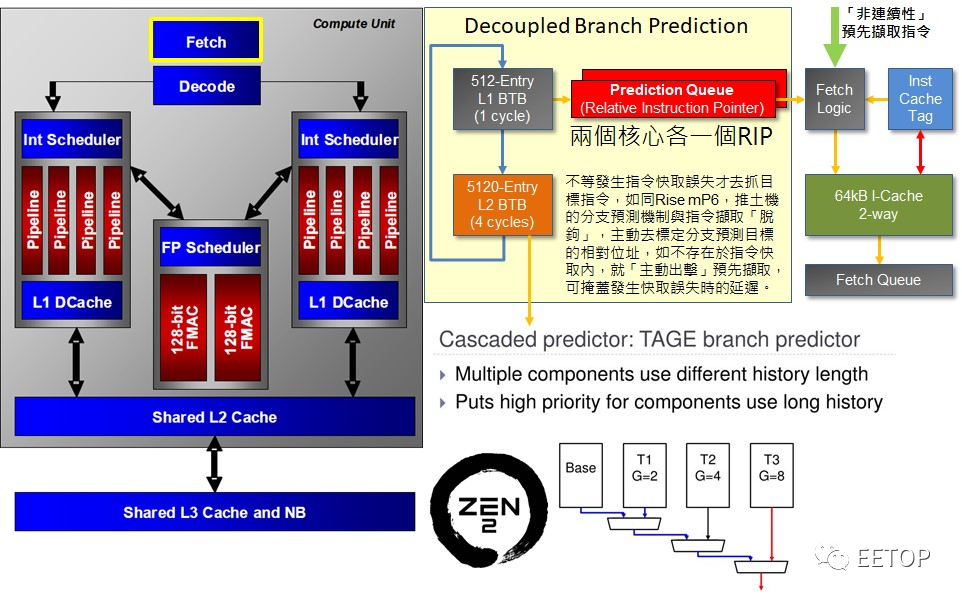
依照 AMD 的说法,Zen 2 的分支错误率比 Zen 减少了 30%,意味着 Zen 从 97% 的精确度提升到 Zen 2 的 98%。但不论解耦式分支预测器还是机器学习分支预测器 TAGE,都是英特尔研究多年并发表过学术论文的产物,很可能早就导入产品了,但没刻意拿出来说嘴。不过花了这么长的时间,AMD 总算在分支预测赶上英特尔的水准,仍值得可喜可贺。
激增有效实质容量的互斥性 Cache架构
各位有没有想过:Ryzen Threadripper3990X 的「288MB」 Cache容量究竟是怎么算出来的?
答案是「64 核心× 512kB 第二阶 Cache」加上「8个CCD × 2 个CCX × 16MB 第三阶 Cache」,因两边的内容是「互斥」(Exclusive)的,而第二阶 Cache完全包含(Inclusive)了第一阶 Cache的内容,所以有效容量是32MB+256MB=288MB,这也是AMD CPU 从K7 后期至今,一个持之以恒的共同特征,而英特尔则从Nehalem 开始,走上另一条彻底相反的路线。
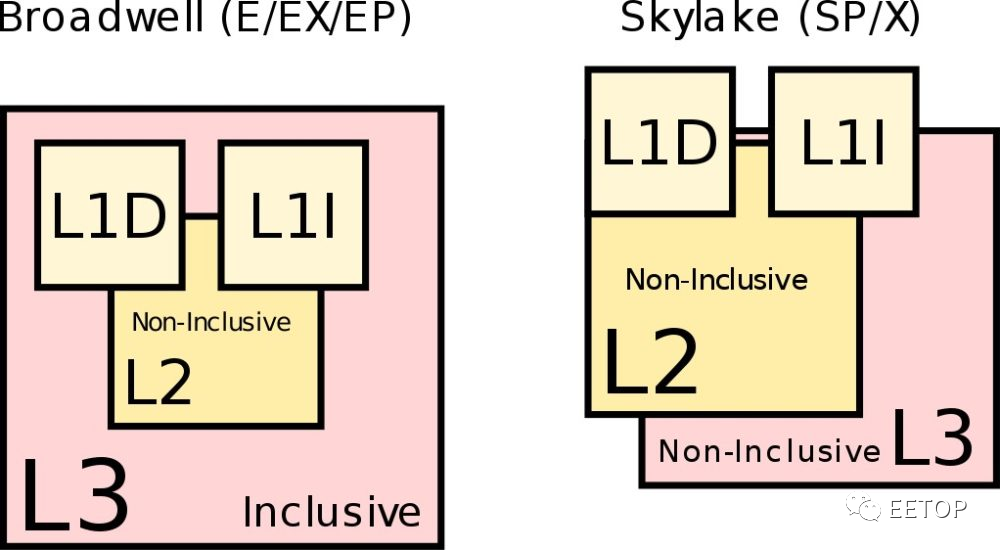
互斥性 Cache架构的发生背景是K7 从Thunderbird 开始,CPU直接整合256kB 或64kB 第二阶 Cache存储器,但K7 的第一阶Cache总容量多达128kB,不让两者「油水分离」,将会浪费大量的有效容量,如Duron 的L1 竟然还是L2 两倍的蠢事(128kB vs. 64kB)。从 K7 到 K10 是 L1 / L2 互换,K11到 Zen 则调整成 L2 / L3 轮转。
K8 / K10 利用这点,趁L1 指令Cache的数据搬到L2 时,将分支选择器随着预先解码(Pre-decoded)和奇偶校验(Parity)栏位,一并写入确定存放指令的L2 Cache区块之ECC 栏位,但互斥性 Cache架构也是AMD CPU 最末阶 Cache延迟过长的元凶。
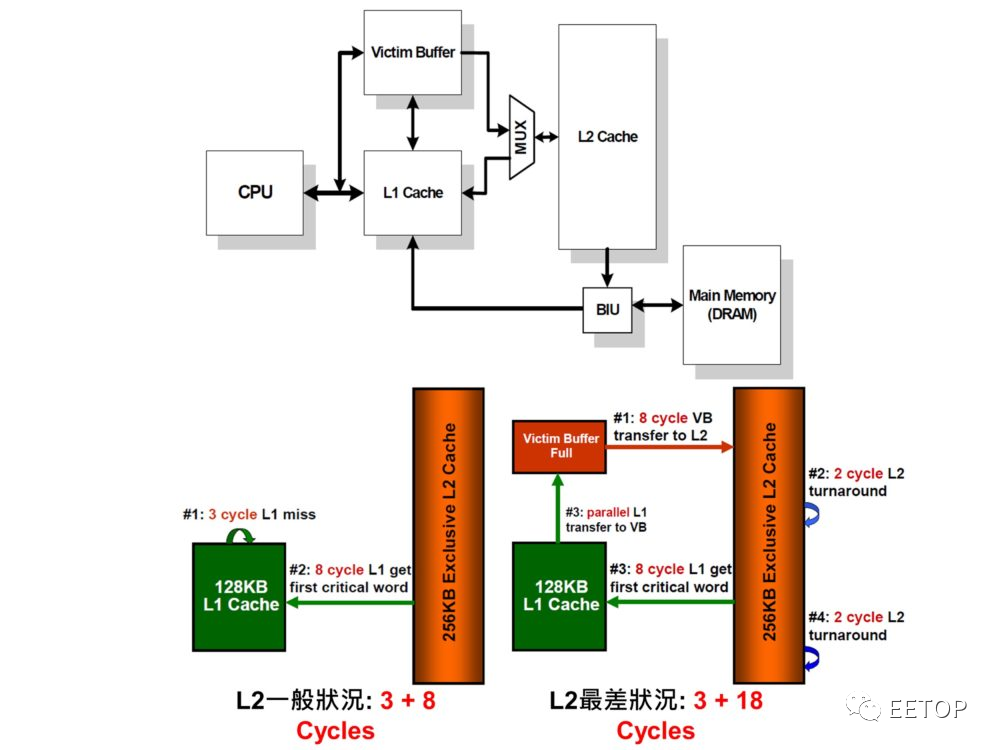
服务器等级的存储器自动侦测容错机制
服务器要的是RAS:可靠性(Reliability)、可用性(Availability)、可服务性(Serviceability),而最大的潜在威胁,莫过于构成地球低强度背景辐射的带电粒子,所引起位元翻转的存储器软错误(Soft Error),动辄偶发的多位元错误更是一大挑战。K8 之所以能替AMD 敲开服务器天堂的大门,被侦错容错机制高度保护的 Cache存储器与主存储器,以及检测硬体错误并回报软体进行复原处理的硬体检查架构(Machine Check Architecture,MCA),统统功不可没。
从K8 到Zen,ECC(Error-CorrectingCode)越来越强悍,L1 数据 Cache存储器可「修复单位元错误,侦测双位元错误」,L2 / L3 Cache存储器更「修复双位元错误,侦测三位元错误」,但「数据损坏了顶多重抓」的L1 指令 Cache「不太需要完善保护,只须奇偶校验」的原则毫无改变的迹象,事实上也没必要,起码节约成本。
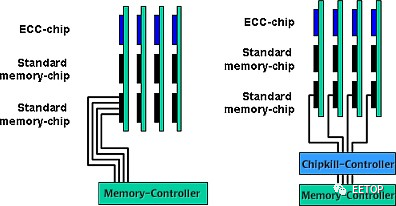
K8 整合式存储器控制器支援防止存储器多位元错误的 Chipkill 技术,如何做到?下面这张图阐述得非常清晰。
既然存储器模组使用的 ECC 演算法无法纠正超过单位元的错误,那么我们就「分而治之」,让超过单位元的错误,不会出现在单一存储器模组。假设有4 条存储器模组,而存储器模组颗粒数据总线的宽度为4 位元,我们各自分开存放ECC 侦错码的额外颗粒的4 条数据线,和另外3 条模组的数据线组成4 位元宽度,即可预防单一存储器模组发生超过1 位元的错误。
论服务器可靠性RAS,英特尔、AMD 是半斤八两,像在Nehalem-EX(Xeon 7500 系列)时期,英特尔硬把Itanium 一整套搬到x86 平台变成「MCA Recovery」,可在存储器区块标示硬体无法修复的错误,通知作业系统或虚拟机器管理员不再使用这些单元,关闭标示错误的数据并重新启动程式,AMD 也从来没有缺席(软体支援性就见仁见智了),但AMD 在21 世纪初期曾短暂从英特尔手上夺过服务器的技术优势,依然值得大书特书。

经过千锤百炼的 Cache数据一致性协定
Cache数据一致性协定(Cache CoherenceProtocol)对多核心与多处理器平台的效能的重大影响,无论怎么说都是毋庸置疑的,不只服务器RAS,x86 CPU 在AMD K7 问世的MOESI协定,相较于行之有年的MESI,Owner 状态允许尚未更新主存储器的内容前,不同CPU 之间可提前共享、并交换修改后的 Cache区块,可大幅减轻系统总线的压力,这因K8 整合存储器控制器,而在多处理器环境,让主存储器分散在四处的NUMA(Non-Uniform Memory Access)架构,更是决定效能的关键。
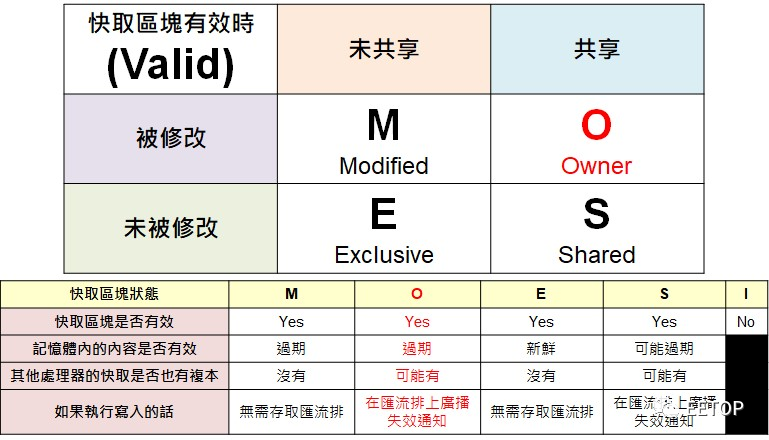
AMD 或多或少有英特尔的 MESIF 协定殷鉴在前,Zen 进一步扩充成 MDOEFSI。

L3 Cache「海纳」L2 Cache标签(Tag)的巧思,使其摇身一变,成为可过滤 Cache一致性协定广播的Probe Filter(或称之为Snoop Filter,AMD 的行销名称是HT Assist) ,不必像K10 切割部分L3 Cache容量,或在系统芯片组塞一大块SRAM 当成记录所有 Cache区块状态的目录,仅付出低成本实现高效率的 Cache一致性。
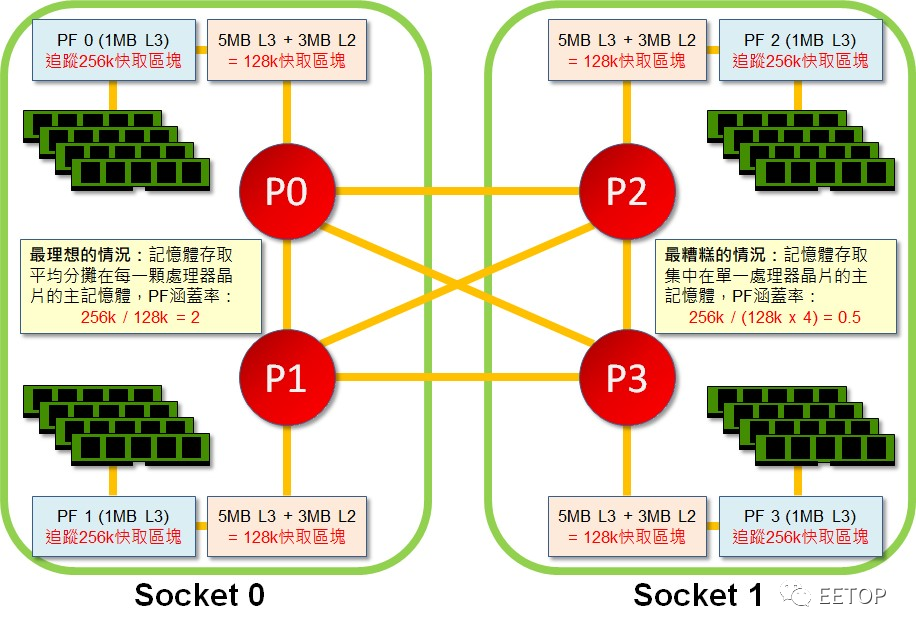
将MDOEFSI 协定的细节束之高阁,目前看来在实体CPU 芯片(CPU Complex)数量极多的EPYC 和Threadripper 运行还不错,长期大型单一晶粒共用L3 Cache的英特尔却没有这样的特殊考虑,也许当英特尔哪天基于成本因素,被迫和AMD 一起「包水饺」,那时才是考验英特尔 Cache一致性协定的最佳时机。
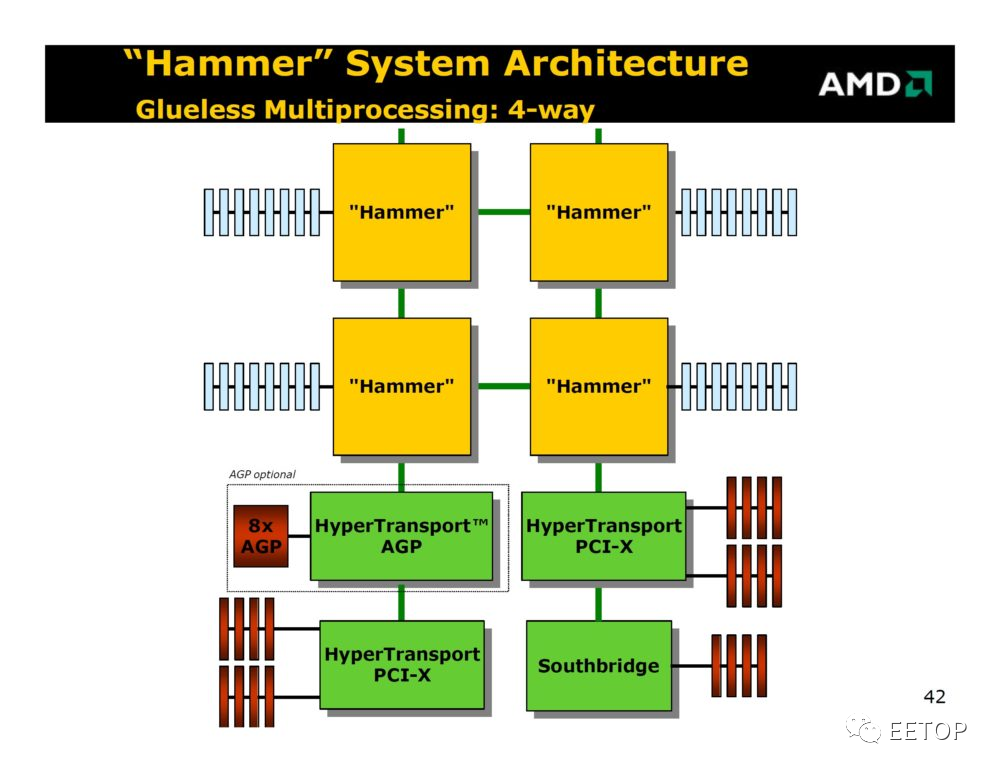
支持大量处理器延展性的系统连结架构
最近 AMD 在财务分析师大会发表名为「Infinity Architecture」的 Infinity Fabric 3.0,不仅可连接多颗 CPU 和多颗 GPU,更可当成CPU和 GPU 之间的桥梁。
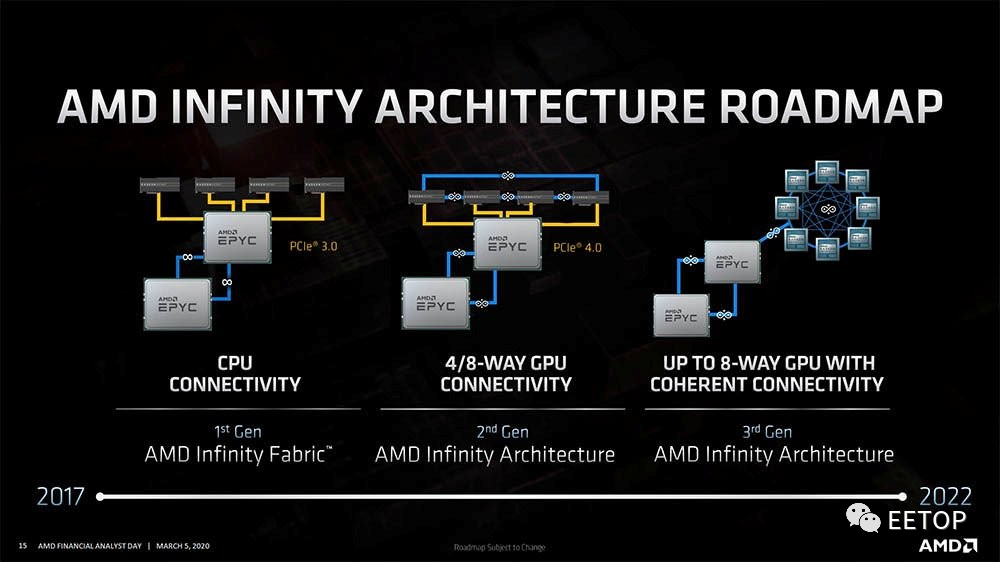
但这对AMD 来说并非新颖的概念,AMD 早在十几年前K8 的HyperTransport就打算这样干了,而Infinity Fabric 就是从HyperTranspor延展出来的「超集合」,拥有更完整的功能,从定义AMD内部SoCIP 区块的通用控制方式,到解决异构数据一致性的互连方案,都是持续进化中的Infinity Fabric 可大展身手的领域。
AMD 未来面对的挑战依旧严峻
本文标题并不表示 AMD 这间公司就此功德圆满。回顾25 年的AMD K 系列CPU 迢迢来时路,想必各位可渐渐感受到身为硕果仅存英特尔唯一x86 竞争者(好吧,勉强还有台湾VIA 的Centaur 和俄罗斯的Elbrus),面对资源数倍于己的超级强敌,身处毫无犯错余裕、如履薄冰、步步为营的艰困处境,研制产品时的取舍与挣扎,更是AMD 困境的缩影。
至于时下的AMD 是否「已经」成功,也是个巨大的问号,服务器市场市占率、营收与获利仍远远不及K8 核心Opteron 全盛期水准,另一边的GPU 战场,还是被nVidia 压着打,实际上只能算勉强站稳脚步,离「成功」两字仍有一段相当长的距离。AMD 另一个比较大的潜在危机在于「未来性」,这和公司能真正「发大财」互为表里。
如果对比「苏妈」和「皮衣教主」的演讲内容,相信大多数人仍会觉得前者「相当传统保守」,后者「象征光明未来」。从量子计算、人工智能到自驾车等新兴应用,AMD 统统沾不上边,连在高效能运算市场要反攻Top500 席次都还颇有难度,唯有巩固并扩张数据中心的获利与营收,才有足够银弹投资未来。偏偏这里又是英特尔重兵集结、拼死防御、明枪暗箭明招暗招毫无保留的「现金母牛」(Cash Cow),绝不会平白拱手让人。
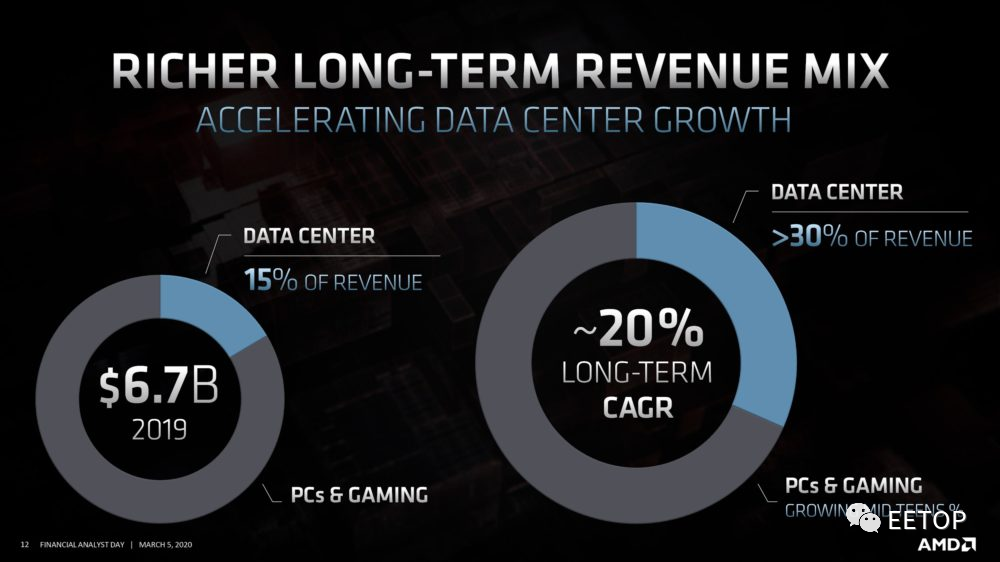
AMD 能否守住得来不易的战果,唯有寄望晶圆代工商业模式有机会让英特尔的制程霸权从此一去不复返,或英特尔再度犯下重大战略失策,但笔者对此的态度并不乐观,2020 年第三季的Zen 3 与第三代EPYC「Milan」对AMD 将是极为重要的命运转折点。从光鲜亮丽简报溢出来的满满忧虑,其实都早写在 AMD高层和无数员工的脸上,只是你没看出来。
好戏即将上演,就让我们拭目以待。

资料推荐
