ImageNet训练再创纪录,EfficientNet异军突起,ResNet:感受到了威胁
AI科技评论
今天
收录于话题
作者 | 青暮
近年来,随着
深度学习
走向应用落地,快速训练ImageNet成为许多机构竞相追逐的目标。
2017年6月,FaceBook使用256块
GPU
以1小时在ImageNet上成功训练了ResNet-50。在这之后,ResNet-50基本成为了快速训练ImageNet的标配架构。
2018年7月,腾讯实现用2048块Tesla P40以6.6分钟在ImageNet上训练ResNet-50。同年8月,Fast.ai实现了18分钟的快速训练,他们使用的硬件是128块Tesla V100。到11月,
索尼
更是将训练时间压缩为224秒,不过其当时使用了2176块Tesla V100。Fast.ai和索尼使用的网络架构也都是ResNet。
那么如今,在快速训练ImageNet的竞逐上,形成了什么局面呢?
1
ResNet霸榜,偶有对手
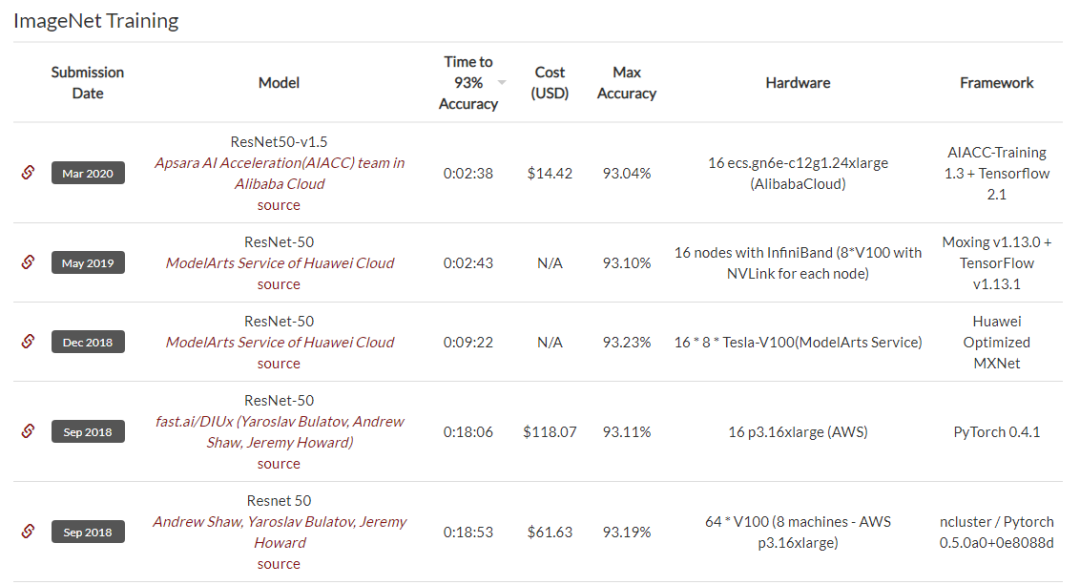
在DAWNBench的ImageNet训练排行榜上,我们可以看到,前五名都是使用了ResNet-50
,并且最快训练时间达到了2分38秒,同时还能实现93.04%的top-5准确率,以及14.42美元的低训练成本。
DAWNBench 是斯坦福发布的一套基准
测试
,主要关注端到端的
深度学习
训练和推断过程,用于量化不同优化策略、模型架构、
软件
框架、云和硬件的训练时间、训练成本、推理延迟和推理成本。
排行榜地址:https://dawn.cs.stanford.edu/benchmark/ImageNet/train.html
但除了ResNet-50,就没有其它适合快速训练ImageNet的架构了吗?
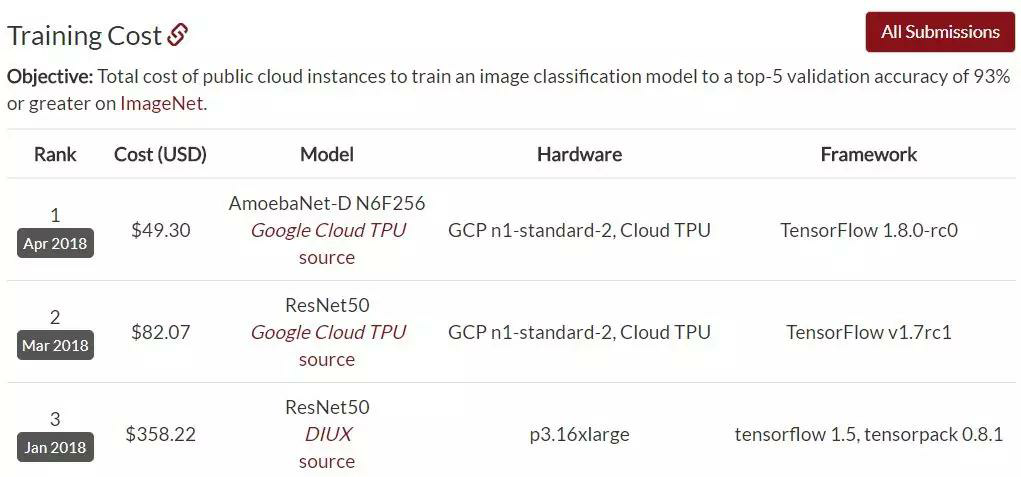
在这个排行榜的第10位,我们看到了一个孤独的名字——AmoebaNet-D N6F256,根据排行榜的数据,它用1/4个TPUv2 Pod和1小时的时间在ImageNet上达到了93.03%的top-5准确率。
实际上,该架构在2018年4月就由
谷歌
提出,
在相同的硬件条件下,AmoebaNet-D N6F256的训练时间比ResNet-50要短很多。
并且,AmoebaNet-D N6F256的训练成本也只有ResNet-50的一半。AmoebaNet-D是基于进化策略进行架构搜索的
NAS
架构,
谷歌
通过提供复杂的构
建模
块和较好的初始条件来参与进化过程,实现了手动
设计
和进化的有机组合。
论文:Regularized Evolution for Image Classifier Architecture Search
除此之外,在DAWNBench的排行榜上,就看不到其它类型的架构了。
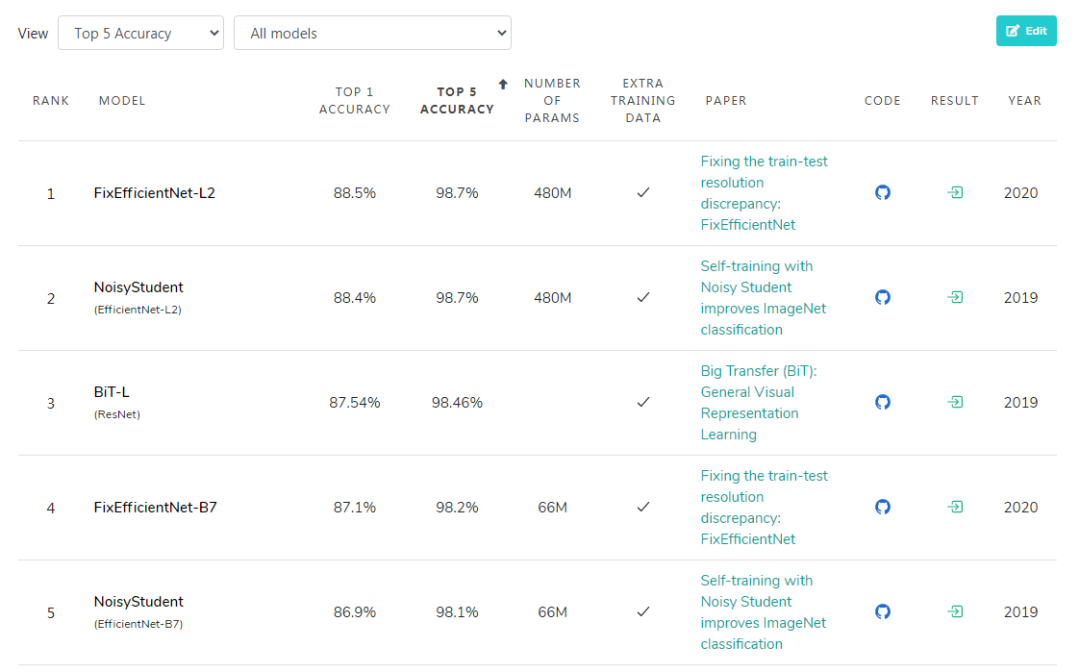
但是在Papers With Code的ImageNet排行榜上,就没有出现ResNet和AmoebaNet-D霸榜的现象。
在top-5准确率前五名中,可以注意到,除了ResNet以外,剩下的架构都和EfficientNet有关。
其中排名第一的架构,其top-5准确率已经达到了98.7%。不过这个排行榜并没有列出训练时间、硬件和成本,所以和DAWNBench不能一概而论。
排行榜地址:https://www.paperswithcode.com/sota/image-classification-on-imagenet
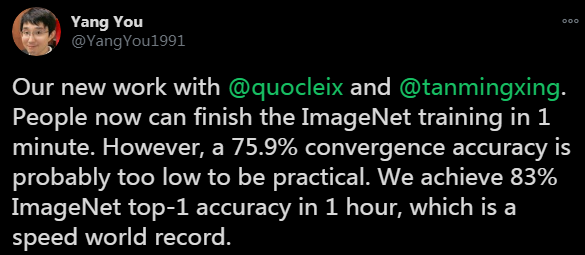
EfficientNet近日在这项竞逐中也出现了新突破,新加坡国立大学的尤洋和
谷歌
研究院的Quoc Le等人发表了一项新研究,表示其用1小时实现了ImageNet的训练,并且top-1准确率达到了83%
(Papers With Code的排行榜前十名的top-1准确率在86.1%到88.5%之间)。
论文地址:https://arxiv.org/pdf/2011.00071.pdf
尤洋在推特上表示,这项研究在准确率足够高的前提下,在速度上创造了一个世界记录。
EfficientNets是基于有效缩放的新型图像分类卷积
神经网络
系列。
目前,EfficientNets的训练可能需要几天的时间;例如,在Cloud
TPU
v2-8节点上训练EfficientNet-B0模型需要23个小时。
在这项研究中,作者探索了在2048个内核的
TPU
-v3 Pod上训练EfficientNets的技术,目的是在以这种规模进行训练时可以实现加速。
作者讨论了将训练扩展到1024个
TPU
-v3内核、批量大小为65536时所需的优化,例如大批量优化器的选择和学习率的规划,以及分布式评估和批量归一化技术的利用。
此外,作者还提供了在ImageNet数据集上训练EfficientNet模型的时序和性能基准,以便大规模分析EfficientNets的行为。
通过优化后,作者能够在1小时4分钟内将ImageNet上的EfficientNet训练到83%的top-1准确率。
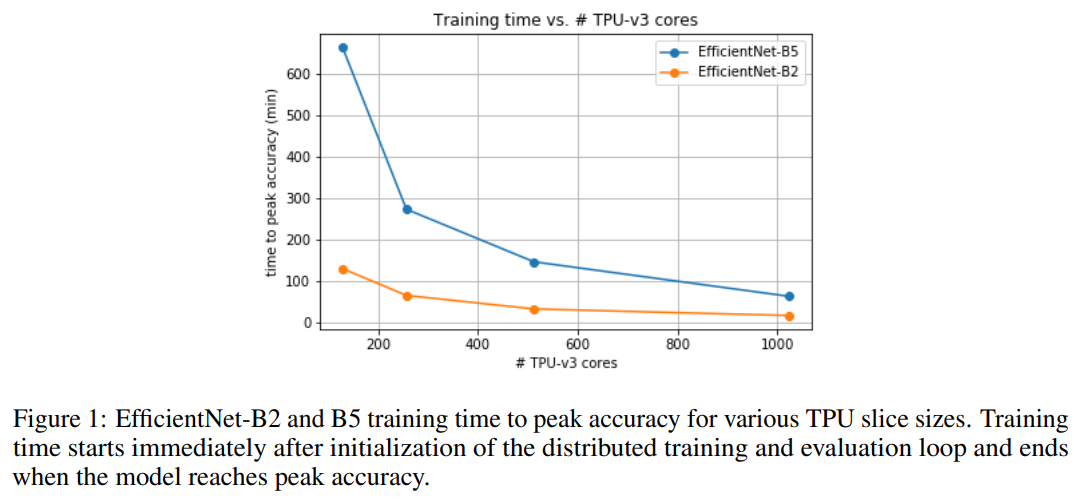
图1展示了对不同
TPU
内核数,EfficientNet-B2和B5训练时间达到的峰值准确率。训练时间在分布式训练和评估循环初始化之后立即开始计算,并在模型达到峰值准确率时结束。
可以观察到EfficientNet-B2在1024个
TPU
-v3内核上的训练时间为18分钟,top-1准确率为79.7%,全局批处理大小为32768,这表明训练速度明显提高。
通过在1024个
TPU
-v3内核上将全局批处理规模扩展到65536,可以在EfficientNet-B5上在1小时4分钟内达到83.0%的准确率。
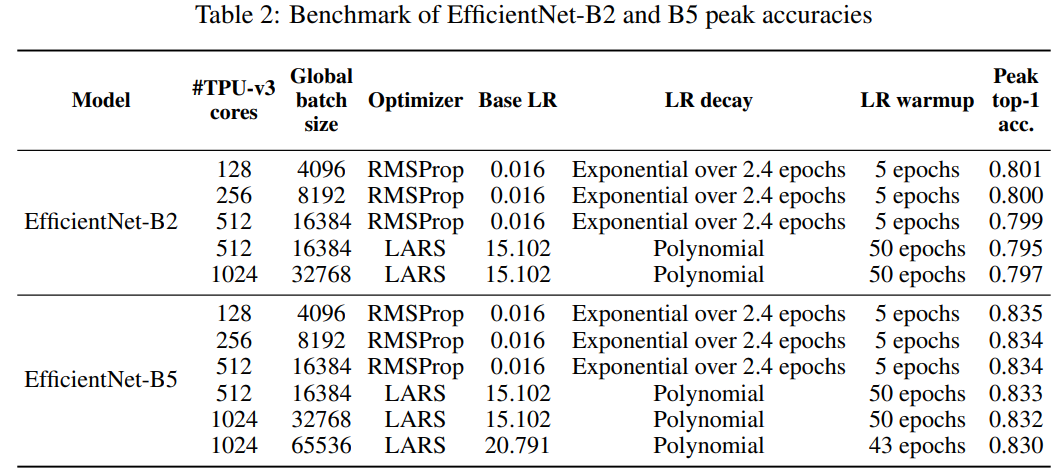
表2展示了EfficientNet-B2和B5峰值准确率的基准,这里可以找到准确率的完整基准以及相应的批次大小,作者表示,即使使用全局批次大小,使用他们的方法,也可以在EfficientNet-B5上保持83%的准确率。
这项研究至少表明了,在EfficientNet上探索大规模图像分类的快速训练也是一个有希望的方向。
2
方法
将EfficientNet培训扩展到1024个
TPU
-v3内核会带来很多挑战,必须通过
算法
或系统优化来解决。
第一个挑战是随着全局批量规模的增加保持模型质量。由于全局批处理规模随用于训练的内核数量而定,因此,必须利用大批量训练技术来保持准确率。
而在大量
TPU
芯片上进行训练时也会面临计算瓶颈,不过可以使用Kumar等人提出的分布式评估和批量归一化技术来解决这些瓶颈。以下是为扩展TPU-v3 Pod上的EfficientNet训练而探索的优化技术:
大批量优化器
最初的EfficientNet论文使用RMSProp优化器,但众所周知,批量较大时,RMSProp会导致模型质量下降。
通过数据并行性将训练规模扩展到1024个
TPU
-v3内核,意味着如果保持每个内核的批量大小不变,则全局批量大小必须与内核的数量成比例增加。例如,如果我们将每核的批处理大小固定为32,则1024个核上的全局批处理大小将为32768。
另一方面,如果在扩展到多个核时全局批处理大小是固定的,则每核的批处理大小会降低,导致效率低下和吞吐量降低。
因此,为了更好地利用每个
TPU
内核的内存并提高吞吐量,必须使用较大的全局批处理大小。使用You等人提出的分层自适应速率缩放(LARS)优化器,能够扩展到65536的批量,同时达到与Tan和Le中报告的EfficientNet基准准确率相似的准确率。
学习率规划
为了在使用大批量时保持模型质量,作者还采用了学习率预热和线性缩放技术。
在保持epoch数固定的同时增加全局批量大小将导致更新权重的迭代数较少。为了解决这个问题,作者将线性缩放规则应用于批次中每256个样本的学习率。
但是,较高的学习率会导致发散。因此,作者还应用了学习率预热,其中训练以较小的初始学习率开始,并在可调整的时期内逐渐提高学习率。此外,作者比较了各种学习速率规划,例如指数衰减和多项式衰减,发现对于LARS优化器,多项式衰减计划可实现最高的准确率。
分布式评估
评估循环的执行是EfficientNet的标准云
TPU
实现的另一个计算瓶颈,因为评估和训练循环是在单独的TPU上执行的。
在传统的TPUEstimator中,评估是在单独的TPU上进行的,训练的执行速度要比评估快,导致端到端时间很大程度上取决于评估时间。
为了克服这个问题,作者利用Kumar等人所述的分布式训练和评估循环。它在所有
TPU
上分配了训练和评估步骤,并允许扩展到更大数量的副本。
分布式批处理归一化
作者使用Ying等人提出的方案,通过将副本的子集分组在一起,在副本之间分布批处理归一化。这种优化可通过权衡
TPU
之间的通信成本来提高最终精度。分组在一起的副本数是可调超参数。
最终的批次归一化批次大小(每个副本子集中的样本总数)也会影响模型质量以及收敛速度。对于大于16的副本子集,作者还探索了将副本分组在一起的二维切片方法。
精度
目前已经观察到,使用bfloat16浮点格式来训练卷积
神经网络
可以达到甚至超过使用传统单精度格式(例如fp32)训练的网络的性能,这可能是较低精度的正则化效果所致。
作者实现了混合精度训练,以利用bfloat16的性能优势,同时仍保持模型质量。在实验中,bfloat16用于卷积运算,而所有其他运算都使用fp32。使用bfloat16格式进行卷积可提高硬件效率,而不会降低模型质量。
点击阅读原文,直达NeurIPS小组~
预览时标签不可点
收录于话题
#
个
上一篇
下一篇
阅读原文
阅读
分享
收藏
赞
在看
已同步到看一看
写下你的想法
前往“发现”-“看一看”浏览“朋友在看”
前往看一看
看一看入口已关闭
在“设置”-“通用”-“发现页管理”打开“看一看”入口
我知道了
已发送
取消
发送到看一看
发送
ImageNet训练再创纪录,EfficientNet异军突起,ResNet:感受到了威胁
最多200字,当前共
字
发送中