行业视角 | 构建更好的AI芯片
随着7nm及更小线宽技术越来越复杂和昂贵,格芯正在采取不同的方法来提高性能,以更低的工作电压和新的IP模块增强12nm节点性能。这些改进对AI(神经网络)加速器特别有效。基于新的12LP+技术的晶圆厂的客户在AI加速方面已取得的成果。
简介
摩尔定律虽未消失,但其影响力正在快速减弱。经过50年的持续进步,实现下一个节点变得越来越困难。过去十年中,光刻成本不断上涨,尤其是最近推出的EUV。从16nm节点开始,向3D (FinFET)晶体管的迁移进一步提高了成本。因此,历史性的晶体管成本快速下降已经趋于平缓,在最近几个节点都只是小幅下降,如图1所示。新芯片设计的初始流片成本也从28nm的100万美元飙升到7nm的约1000万美元。
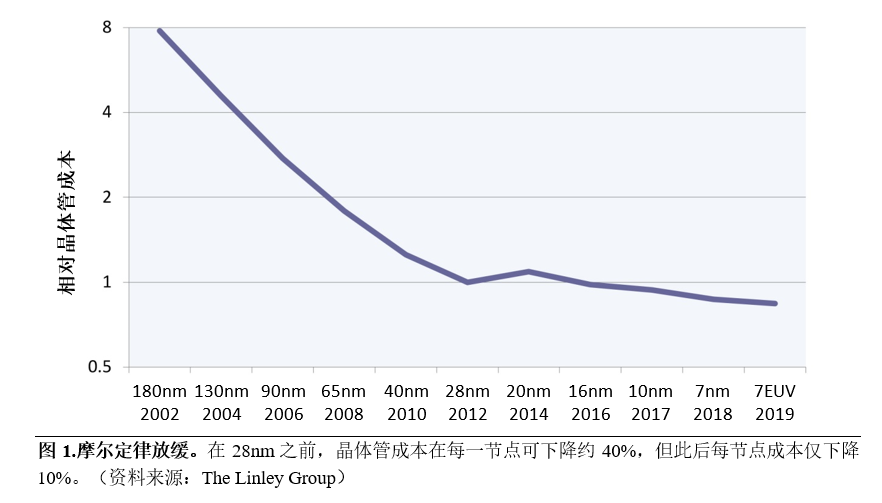
为了实现更好的性能和电源效率设计,一些芯片公司愿意支付这些更高的成本,但其收益也在放缓。英特尔处理器从2002年的1.0GHz快速提升至2005年的3.8GHz,但过去十年中,最高时钟速度每年仅提升了3%。其他处理器设计人员也遇到过类似的困难:自2014年以来,ArmCPU速度每年增长约6%。问题的部分原因在于,大多数设计的工作电压已经远低于1.0V,几乎没有进一步降低电压和功耗的空间。考虑到这些权衡取舍,许多公司并未将其芯片设计推向7nm节点或更小线宽。
为了协助这些公司,格芯(GF)增强了其12nm技术,通过改善性能和功效,创建出新的12LP+工艺。这些改善对于AI(神经网络)加速器特别有效。例如,神经网络经常采用乘法累加(MAC)运算,因此格芯重新设计了其12nmMAC单元,使功效提高了65%。新型SRAM单元针对神经网络中常用的顺序数据存取进行了优化,使功效翻倍。此外,新的双功函数金属栅极降低了电源电压,从而可以进一步降低50%的功耗。
12LP+技术基于格芯客户在AI加速方面已取得的成果。一家初创公司利用12LP技术构建了一款芯片,其AI性能达到了业界领先的820万亿次/秒(TOPS)。另一家12LP客户利用备受欢迎的ResNet-50推理基准,在数据中心芯片中取得了业界领先的能效。另一方面,采用格芯22nm技术的一款芯片实现了出色的AI性能,其功耗仅为50mW。这些客户和其他客户将独特和创新的逻辑设计与格芯制造技术相结合,实现了上述领先的性能指标。
晶体管更小,问题更多
在新近的节点中,光刻技术是关键的成本驱动因素。深紫外(DUV)光刻技术在28nm节点达到了极限。为了取得更大的进步,业界转而采用昂贵的22nm双重曝光和成本更高的10nm四重曝光。晶圆厂开始在7nm工艺上采用极紫外(EUV)技术,但该技术需要新的掩模、新型抗蚀剂(较昂贵),以及重达180吨且成本超过1亿美元的新型步进光刻机。FinFET需要额外的工艺步骤来构建3D晶体管。7nm节点引入了一种用于通孔的新材料(钴)。每个节点还向堆栈中增加了另一金属层(目前在台积电的5nm技术中已达14层),从而增加了更多的工艺步骤。
每个新工艺步骤都会增加晶圆成本,并且昂贵的光刻工具成本会分摊到所有晶圆上。因此,自28nm节点开始,晶圆成本一直在迅速上涨,从而抵消了大部分晶体管成本的潜在下降。顾名思义,双重曝光需要的工艺步骤加倍,而四重曝光则需要更多的步骤。EUV步进光刻机消除了多次曝光,但其昂贵的设备成本和更低的吞吐量意味着EUV层的成本是DUV层的三倍。EUV掩膜必须使用特殊材料构建,才能阻挡近X射线,并且需要非常精细的线宽细节。因此,流片成本(包括构建一套完整的掩膜)随着EUV的采用迅速增加。
这些努力使每个节点的晶体管面积继续减少约50%,符合摩尔定律的要求。由于晶体管的缩小,切换状态需要的电子更少,因此功耗更低,开关速度更快。虽然晶体管缩小了,但大多数设计人员喜欢将更多功能集成到芯片中,因此芯片面积并未缩小。这样,晶体管之间的金属连接长度仍然相同。更糟糕的是,采用每个节点技术的这些连接变得越来越细,从而增加了它们的电阻。对于复杂的高端处理器,通过该互连推动信号所需的功率现在远远超过了晶体管的开关功率,抵消了晶体管缩小带来的好处。许多设计人员发现采用7nm工艺时的时钟速度几乎没有提高,或者功效仅比以前的节点提高了10%。
在未来的节点中,这种情况不太可能改善。尽管5nm采用的是单次曝光EUV,但这种方法不足以用于下一节点。一种选择是双重曝光EUV,这又使各层的成本加倍。为了避免这个问题,设备制造商正在研究一项称为高NA EUV的新技术,可以在单程光刻中创建更小的特征。但是,该设备将比当前的EUV步进光刻机更昂贵,并且此技术需要仍在开发中的新抗蚀剂材料。下一节点还将采用新的晶体管技术(GAAFET),这需要额外的工艺步骤,从而进一步提高成本和设计复杂性。解决所有这些问题的过程可能会导致3nm及后续节点推迟上市。
设计更智能,而不是更小
格芯没有沿着这条越来越窄的道路前进,而是决定增强高成本效益的12nm工艺,以提供更出色的性能和功效。具体而言,格芯专注于热门的AI增强型芯片的市场,从服务器专用AI加速器到集成微型AI引擎的微控制器。尽管最终应用各不相同,但这些芯片都有相同的要求:最大化通用AI运算的能效。
当今最流行的AI应用采用卷积神经网络(CNN)。顾名思义,CNN主要执行卷积函数,将固定权重与输入的激活值反复相乘,并将乘积加到累加器中。为了简化该运算,格芯着重于两项工作:从SRAM中获取激活值和有效地计算MAC运算。
通用处理器通常将SRAM用于缓存或必须对任何存取模式做出快速响应的其他片上存储器。因此,晶圆厂力求针对随机存取优化SRAM设计。这些SRAM阵列可一次获取多个值(例如,缓存行),然后使用多路复用器(mux)选择所需的值,而丢弃其他值。但是,卷积在非常大的数组上运行,因此通常按顺序处理数据。
格芯设计了一个新的SRAM,它可以一次读取并锁存四个值,然后使用多路复用器选择所需的值。锁存器减慢了第一次存取的速度,但是如果第二次存取是顺序存取,则它可以立即从锁存器中读取下一个值,无需再次访问该数组。因此,一系列的顺序读取可以消除四次存取中的三次,大大降低了SRAM阵列所需的功耗。对于典型的CNN,此方法可使SRAM的功耗降低约50%。
低电压工作面临的两大挑战是器件不匹配和SRAM操作所需的电压裕量。格芯已针对12LP+分别实现了逻辑器件和SRAM单元的栅极堆叠。这两个堆叠具有不同的功函数,经过调整后,可以减少不匹配并最大限度地降低电压裕量。该技术可以将SRAM电源电压从0.7V降至0.55V,从而使功耗降低两倍。
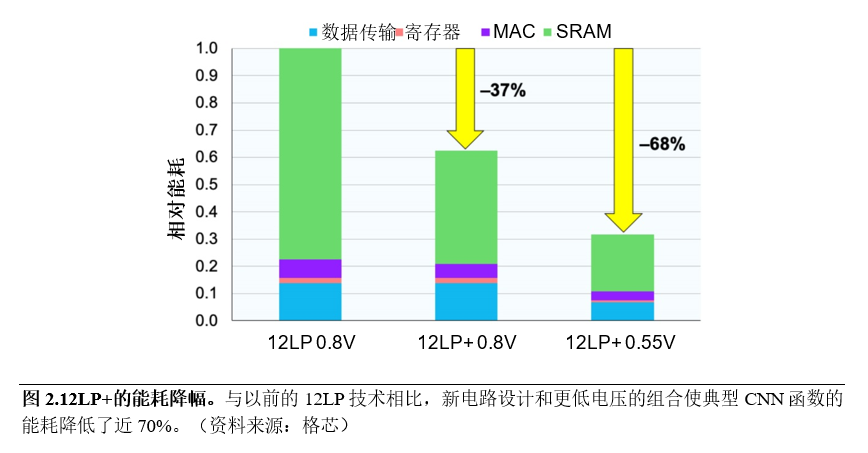
在典型的CNN函数中,功耗的最大贡献者是存储器,而另一个主要的贡献者是MAC单元(如图2所示)。在与客户交流时,格芯发现,与针对单线程性能和几个GHz时钟速度进行优化的通用CPU不同,AI加速器需要处理高度并行的工作负载,并且运行速度为1GHz左右,以最大程度地提高能效。因此,格芯设计了一款新型乘法器和加法器,针对较低的时钟速度进行了优化,从而使功耗降低了25%。
总体而言,这些优化措施在相同电源电压下可将功耗降低37%,而在利用双功函数栅极降低电源电压的情况下,功耗可降低68%。换句话说,相比在12LP旧工艺上使用标准逻辑模块,卷积函数核心(在CNN中可能消耗90%或更多的计算周期)的运行功效是其三倍。
助力AI领导者
这项新技术建立在格芯成功的赋能了多种行业领先的AI产品的12LP工艺基础上。例如,硅谷初创公司Groq开发了一种新的架构方法来加速集数百个功能单元于单个核心中的神经网络。庞大的设计包括220MB的SRAM和200,000以上的MAC单元。Groq采用12LP使如此大型设计的功耗保持在300W的预算之内。该芯片以1.0GHz的初始速度,对INT8数据实现了每秒820万亿次运算(TOPS)的峰值吞吐量,超过了所有其他已发布的加速器。
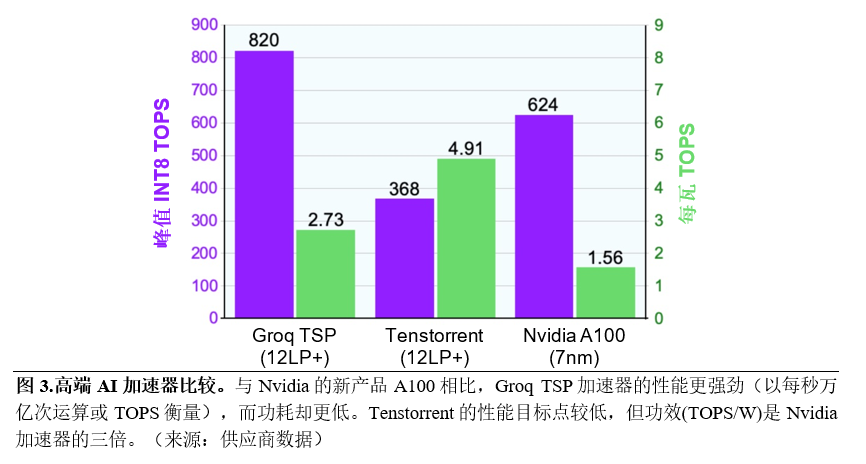
加拿大初创公司Tenstorrent也加速了AI推理,但它选择了一个不同的设计目标:总线供电的PCIe卡的功耗限值为75W。其第一款芯片具有120个独立的核心,每个核心包含1MB的SRAM和大约500个MAC单元。这种方法仍然需要大量的SRAM和MAC单元。该芯片以1.3GHz的初始速度可提供368 TOPS。12LP技术帮助Tenstorrent实现了每瓦4.9TOPS的性能,这一效率在数据中心产品中遥遥领先,如图3所示。
在这个市场上占有最大份额的Nvidia最近发布了基于新型Ampere架构的A100加速器。Ampere引入了许多创新特性,峰值性能提高到624 TOPS,超过了除Groq之外的所有已发布芯片。然而,尽管采用7nm工艺,但A100仍需要400W TDP,比之前的12nm产品还高33%。为了适应功耗预算的增加,Nvidia不得不降低时钟速度(相对于12nm产品),并禁用芯片上15%的核心。这是一种不寻常的策略,可能意味着芯片功耗大大高于仿真功耗。因此,虽然A100的晶体管较小,但其每瓦性能严重落后于Groq和Tenstorrent芯片。
格芯还支持客户开发用于嵌入式系统的低功耗芯片,其中许多芯片还增加了AI功能。这些产品比数据中心加速器更注重成本,因此它们通常使用较旧的节点。GreenWaves和Perceive等创新型初创公司选择了格芯的22FDX工艺,该工艺采用绝缘体上硅(FD-SOI)技术,可以在不需采用更高成本的FinFET节点的情况下节省功耗。FD-SOI支持自适应反向偏置,这使设计人员可以根据芯片状态来改变基体偏压。例如,在睡眠模式下,施加反向偏置可使漏电流降低10倍,从而大大延长电池续航时间。但当器件处于工作状态时,施加正向偏置可最大限度地提升性能。
GreenWaves GAP9是一款RISC-V微控制器,包括一个小型神经网络加速器,该加速器的工作功耗仅为50mW,其AI工作负载功效是标准微控制器的34倍。Perceive已创建了全新的AI算法,可以70mW的功耗在Ergo芯片上运行。借助FD-SOI技术,Ergo的额定性能达到业界领先的55TOPS/W。为了进一步提高效率,22FDX还支持模拟内存内计算。格芯已与Imec的研究人员合作,使用此技术开发了一款测试芯片,可实现高达2,900 TOPS/W的性能。
优于7nm
摩尔定律越来越难以为继。尽管业界一直在寻找制造更小晶体管的新方法,但是制造此类晶体管的技术越来越昂贵,从而抵消了大部分成本优势。电源电压已接近基本极限,功耗难以进一步降低。推送信号的金属线越来越细,淹没了晶体管缩小带来的开关速度提升和能耗降幅。因此,先进的晶圆厂将面临的挑战越来越大,仅通过缩小晶体管难以在成本、速度或功耗方面取得有意义的进展。
处理器设计人员已经开始通过创建更专用的设计来适应这种新环境。一种新兴趋势是构建AI专用加速器以减轻标准CPU和GPU的负载。晶圆厂可以效仿,创建用于特定应用的技术版本。这些版本不是简单地缩小晶体管和金属堆叠的体积,而是采用经过优化的功能模块和电路设计,更好地满足特定产品类型的需求。
格芯已经将此路线用于12nm节点,针对AI加速器创建12LP+技术。优化包括可大幅降低电压的双功函数栅极,以及优化突发模式性能的SRAM和低功耗MAC设计。总体而言,这些优化将典型卷积运算的功效提高了3倍。相比仅仅将现有的12nm的设计移植到另一家晶圆厂的7nm,新方法可实现更大的改进,并且设计和流片成本也低于7nm。
客户已经使用格芯技术取得了出色的结果。Groq和Tenstorrent使用12LP工艺取得的AI性能和能效领先于所有数据中心加速器。Perceive和GreenWaves使用格芯的22FDX技术,实现了客户设备的功耗降低和效率提高,有助于将AI处理推向边缘。格芯还提供了硅光技术,将数据中心连接至边缘,实现了端到端AI运算。这些示例表明,格芯可以帮助客户实现行业领先的性能,而无需投入高昂的7nm制造成本。新的12LP+增强工艺将带来更大的收益。
★ 本文转自【The Linley Group】,作者Linley Gwennap。 点击【阅读原文】查看原文章。
【相关阅读】
针对AI加速器优化的格芯12LP+ FinFET解决方案已准备投产
在格芯12LP+专业解决方案上利用Arm Ethos-N78和Artisan物理IP解决方案加快边缘计算
媒体视角 | 从晶圆代工厂到生产服务型企业!格芯的转型之路还要走多久
格芯宣布推出全新22FDX+平台,通过物联网和5G移动专业解决方案巩固在FDX领域的领先地位

扫描二维码关注GLOBALFOUNDRIES更多动态
更多详情,登陆格芯中文官网
https://www.globalfoundries.com/cn