
所谓AI芯片实际是深度学习加速器芯片,门槛有多低?非常低,比大部分人想象的都要低。
人工智能(深度学习)现在无处不在,衡量人工智能运算量通常有三个名词。FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。MACCs:是multiply-accumulate operations),也叫MAdds,意指乘-加操作(点积运算),理解为计算量,也叫MAdds, 大约是 FLOPs 的一半。人工智能中最消耗运算量的地方是卷积,就是乘和累加运算Multiply Accumulate,MAC。y = w[0]*x[0] + w[1]*x[1] + w[2]*x[2] + ... + w[n-1]*x[n-1]w 和 x 都是向量,y 是标量。上式是全连接层或卷积层的典型运算。一次乘-加运算即一次乘法+一次加法运算,所以上式的 MACCs 是n。而换到 FLOPS 的情况,点积做了 2n-1 FLOPS,即 n-1 次加法和 n 次乘法。可以看到,MACCs 大约是 FLOPS 的一半。实际就是MAC只需一个指令,一个运算周期内就可完成乘和累加。卷积运算、点积运算、矩阵运算、数字滤波器运算、乃至多项式的求值运算都可以分解为数个 MAC 指令,人工智能运算也可以写成MAC运算。MAC指令的输入及输出的数据类型可以是整数、定点数或是浮点数。若处理浮点数时,会有两次的数值修约(Rounding),这在很多典型的DSP上很常见。若一条MAC指令在处理浮点数时只有一次的数值修约,则这种指令称为“融合乘加运算”/“积和熔加运算”(fused multiply-add, FMA)或“熔合乘法累积运算”(fused multiply–accumulate,FMAC)。假设3×3卷积,128 个 filer,输入的 feature map 是 112×112×64,stride=1,padding=same,MACCs 有:3×3×64×112×112×128=924,844,032次,即1.85TOPS算量。人工智能分训练和推理两大领域,推理领域对模型的精度要求越来越低,主流的是整数8位精度。算力理论值取决于运算精度、MAC的数量和运行频率。大概可以简化为这样子,INT8精度下的MAC数量在FP16精度下等于减少了一半。FP32再减少一半,依次类推。其计算相当简单,假设有512个MAC运算单元,运行频率为1GHz,INT8的数据结构和精度(自动驾驶推理领域常见精度),算力为512 x 2 x 1 Gigahertz = 1000 Billion Operations/Second = 1 TOPS (Tera-Operations/second)。如果是FP16精度那么就是0.5TOPS。例如英伟达的Tesla V100有640个Tensor核,每核有64个MAC运算单元,运行频率大约1.480GHz,那么INT8下算力为640*64*2*1.480Gigahertz=121TOPS。具体到芯片设计领域,一个MAC单元通常包括三部分,乘法器、加法器和累加器。
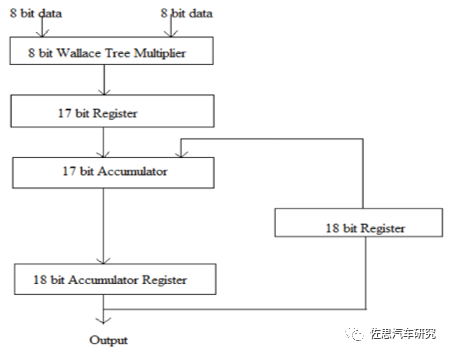
上图为一个典型的MAC单元。计算机体系中的乘法和加法都历经了长时间的研究改进,纯粹的乘法器和加法器肯定是不会有人用。乘法器最常用的Wallace树,这是1963年C.S.Wallace提出的一种高效快速的加法树结构,被后人称为Wallace树。人工智能95%的理论工作都是在1970年前完成的,只是没有高性能计算系统,才没有在那个时代铺展开。加法器多是CSA,即进位保存加法器(Carry Save Adder,CSA)。使用进位保存加法器在执行多个数加法时具有极小的进位传播延迟,它的基本思想即将3个加数的和减少为2个加数的和,将进位c和和s分别计算保存,并且每比特可以独立计算c和s,所以速度极快。这些都已经非常成熟。 AI芯片就是简单暴力地堆砌MAC单元。增加MAC数量,这是提升算力最有效的方法,没有之一,而增加MAC数量意味着芯片裸晶面积即成本的大幅度增加,这也是为什么AI芯片要用到尽可能先进的半导体制造工艺,越先进的半导体制造工艺,就可拥有更高的晶体管密度,即同样面积下更多的MAC单元,衡量半导体制造工艺最主要的指标也就是晶体管密度而不是数字游戏的几纳米。具体来说,台积电初期7纳米工艺,每平方毫米是9630万个晶体管,后期7+纳米可以做到每平方毫米1.158亿个晶体管,三星7纳米是9530万个,落后台积电18%,而英特尔的10纳米工艺是1.0078亿个晶体管,领先三星,落后台积电。这也是台积电垄断AI芯片的原因。而5纳米工艺,台积电是1.713亿个晶体管,而英特尔的7纳米计划是2亿个晶体管,所以英特尔的7纳米芯片一直难产,难度比台积电5纳米还高。顺便说下,台积电平均每片晶圆价格近4000美元,三星是2500美元,中芯国际是1600美元。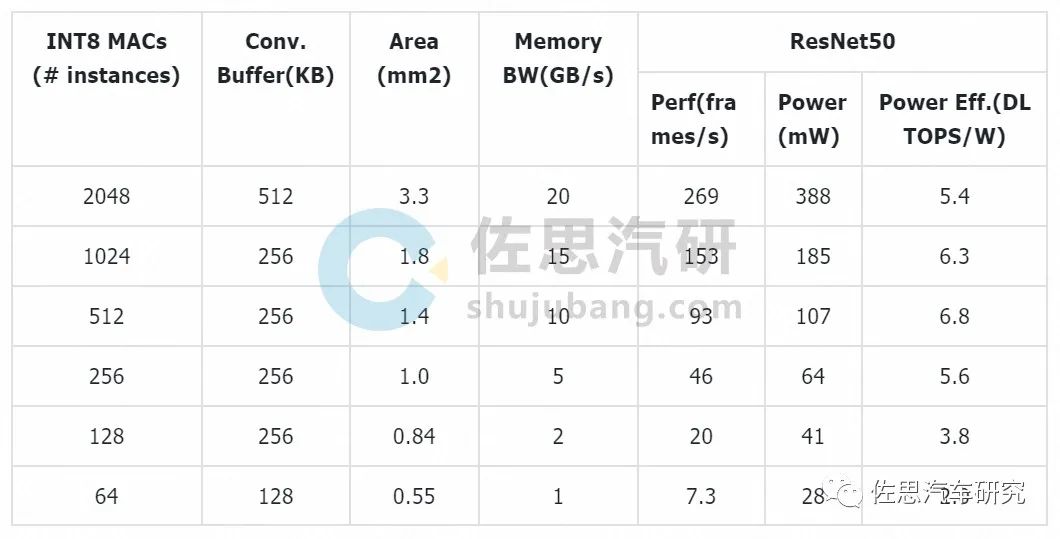
上表为英伟达深度学习加速器架构中的小单元配置,NVDLA (NVIDIA Deep Learning Accelerator),条件是16纳米台积电工艺1GHz运行频率。裸晶面积还包括了卷积缓存的面积。除了增加数量,还有提高MAC运行频率,但这意味着功耗大幅度增加,有可能造成芯片损坏或死机,一般不会有人这么做。除了简单的数量增加,再一条思路是提高MAC的效率。降低推理的量化比特精度是最常见的方法。它既可以大大降低运算单元的精度,又可以减少存储容量需求和存储器的读写。但是,降低比特精度也意味着推断准确度的降低,这在一些应用中是无法接受的。由此,基本运算单元的设计趋势是支持可变比特精度,比如BitMAC 就能支持从 1 比特到 16 比特的权重精度。大部分AI推理芯片只支持INT8位和16位数据。除了降低精度以外,还可以结合一些数据结构转换来减少运算量,比如通过快速傅里叶变换(FFT)变换来减少矩阵运算中的乘法;还可以通过查表的方法来简化 MAC 的实现等。对于使用修正线性单元(ReLU)作为激活函数的神经网络,激活值为零的情况很多 ;而在对神经网络进行的剪枝操作后,权重值也会有很多为零。基于这样的稀疏性特征,一方面可以使用专门的硬件架构,比如 SCNN 加速器,提高 MAC 的使用效率,另一方面可以对权重和激活值数据进行压缩。真实值和理论值差异极大。决定算力真实值最主要因素是内存( SRAM和DRAM)带宽,还有实际运行频率( 即供电电压或温度),还有算法的batch尺寸。例如谷歌第一代TPU,理论值为90TOPS算力,最差真实值只有1/9,也就是10TOPS算力,因为第一代内存带宽仅34GB/s。而第二代TPU下血本使用了HBM内存,带宽提升到600GB/s(单一芯片,TPU V2板内存总带宽2400GB/s)。最新的英伟达的A100使用40GB的2代HBM,带宽提升到1600GB/s,比V100提升大约73%。特斯拉是128 bit LPDDR4-4266 ,那么内存的带宽就是:2133MHz*2DDR*128bit/8/1000=68.256GB/s。比第一代TPU略好( 这些都是理论上的最大峰值带宽)其性能最差真实值估计是2/9。也就是大约8TOPS。16GB版本的Xavier内存峰值带宽是137GB/s。为什么会这样,这就牵涉到MAC计算效率问题,如果你的算法或者说CNN卷积需要的算力是1TOPS,而运算平台的算力是4TOPS,那么利用效率只有25%,运算单元大部分时候都在等待数据传送,特别是batch尺寸较小时候,这时候存储带宽不足会严重限制性能。但如果超出平台的运算能力,延迟会大幅度增加,存储瓶颈一样很要命。效率在90-95%情况下,存储瓶颈影响最小,但这并不意味着不影响了,影响依然存在。然而平台不会只运算一种算法,运算利用效率很难稳定在90-95%。这就是为何大部分人工智能算法公司都想定制或自制计算平台的主要原因,计算平台厂家也需要推出与之配套的算法,软硬一体,实难分开。最为有效的方法还是减小运算单元与存储器之间的物理距离。也是这15年来高性能芯片封装技术发展的主要目标,这不仅可以提高算力,还能降低功耗减少发热。这其中最有效的技术就是HBM和CoWoS。
HBM2的优点是低频频率,高带宽,HBM2可以做到最高12颗TSV堆叠3.6TB/s的带宽,传统DRAM最顶级的GDDR6是768GB/s,但是这样的设计需要采用台积电的先进2.5D封装技术CoWoS。尽管三星几乎垄断了HBM2市场,但却没有能力做CoWoS。HBM2尽管价格高昂,但是几乎垄断高性能计计算领域。未来HBM3优势将更明显。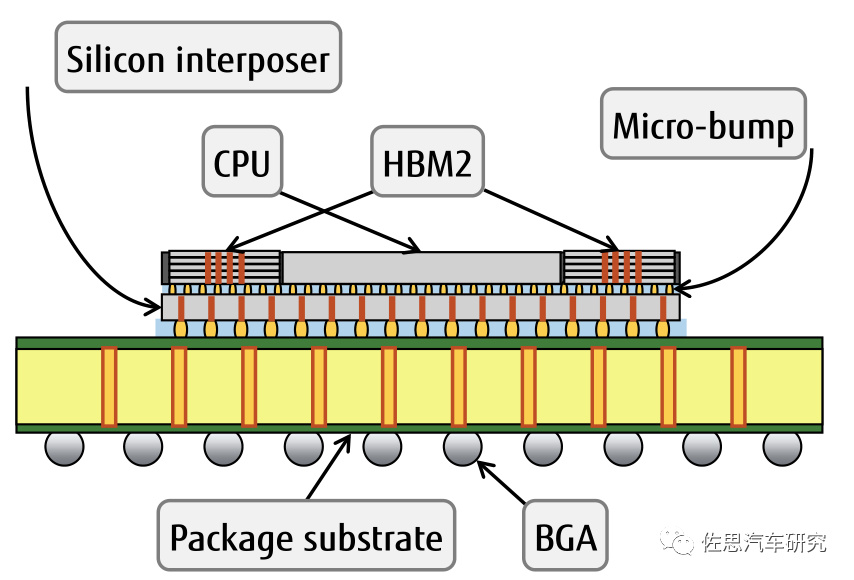
CPU与HBM2之间通过Micro-bump连接,线宽仅为55微米,比传统的板上内存或者说off-chip内存要减少20倍的距离。可以大大缓解内存瓶颈问题。不过HBM和CoWoS价格都很高,假设500万的一次下单量,7纳米工艺的话,纯晶圆本身的硬件成本大约是每片芯片208-240美元,这个价格做训练用AI芯片可以承受,但是推理AI芯片用不起。再有CoWoS是台积电垄断的,台积电也正是靠这种工艺完全垄断高性能计算芯片代工。英特尔的EMIB是唯一能和CoWoS抗衡的工艺,但英特尔不代工。退而求其次的方法是优化指令集,尽量减少数据的访存,CNN算法会引入大量的访存行为,这个访存行为的频繁度会随着参考取样集合的增加而增加(原因很简单,缓存无法装下所有的参考取样,所以,即便这些参考取样会不断地被重复访问,也无法充分挖掘数据本地化所带来的cache收益)。针对这种应用类型,实际上存在成熟的优化范式——Loop tiling。Loop tiling的基本思想是,对于循环逻辑,通过将大块的循环迭代拆解成若干个较小的循环迭代块,减少一个内存元素的复用距离,换句话说,也就是确保当这个内存元素被加载到cache以后,尽可能保留在cache中,直到被再次访问,这样就达到了减少了昂贵的片外访存的开销的目的。使用Loop tiling,片外访存减少了 90%。这就是将访存逻辑定制在硬件层面,通过引入一个称之为IM(Index Module)的硬件模块,完成稀疏访存的处理,从而将稀疏向量/矩阵运算转换成常规向量/矩阵运算。推理用AI芯片除算力外另一个重要的指标是每瓦TOPS。现有的芯片大都是由CMOS(互补金属氧化物)逻辑电路构成,其功耗可以用一个公式粗略表达:P∝CNV²f。公式中,C为负载电容,N为CPU中的晶体管数量,V为电源电压,f为工作频率。负载电容与晶体管栅极线宽成正比,因此要尽量缩小,也就是制造工艺要尽量先进,常说的7纳纳米5纳米就是指栅极线宽。减少数量和降低工作频率就意味着性能下降,高性能芯片都不能动,只能在电源电压上下功夫。电源电压和芯片能耗呈平方关系,也就是说电压每降低到原来的1/2,能量消耗就减少到原来的1/4,这种指数级的关系,为什么少有人提及?CMOS晶体管的功耗由动态功耗和静态功耗组成,动态功耗是晶体管进行开关动作时产生的功耗,占整个功耗的80%,静态功耗是晶体管处于截止状态时,因为漏电产生的功耗,占整个功耗的20%。静态功耗有个特点,一般随电源电压升高而降低,芯片的动态功耗降低了,但静态功耗又像跷跷板一样逐渐升高,当电源电压低于阈值电压时,动态功耗缓慢下降,静态功耗却呈指数级上升。随着电源电压的降低,晶体管的切换速度会越来越慢,当电源电压低于阈值电压时,晶体管的开关状态越来越不稳定,随时会停止工作,就像手机关机,不是电池一点电都没了,是能提供的电压低于正常工作阈值了。通常阈值是0.7V,据说格罗方德有项LP12+工艺能够降低到0.55V,能大幅度降低功耗,但还没有人使用。问题回到原点,最可选择的方案还是先进制程,也就是说找台积电代工。问题是台积电的产能很紧张,台积电已经在积极扩展产能,但最上游的EUV光刻机,ASML的2021年产能大约45台,其中台积电已经预定了30台。剩下15台,有英特尔、三星、东芝、SK Hynix四家分摊,每家最多不超过4台。台积电遥遥领先三星的态势更为明显。这也是三星CEO在欧洲疫情严重情况下毅然亲自出访ASML的主要原因,不过碍于台积电已经先行卡位,就算ASML在2021年EUV设备供给想要加大供给力度给三星也无计可施。三星有意联手ASML开发次世代的EUV设备市场。根据ASML先前释放讯息,高数值孔径的EUV设备预计在2023年提出原型机,距离商用化至少仍有5年左右时间,也就是2028年。台积电在产能紧张时自然优先照顾大客户,台积电十大客户:苹果、AMD、英伟达、高通、联发科、博通、Xilinx、富士通、Marvell。这些大客户下单量是以亿片计算的。台积电在失去第二大客户华为后的2020年10月,依然创出历年同期新高,收入达1193亿台币,显示出华为的空缺被迅速填满。台积电预计2020年按美元计算收入增幅为30%。Mobileye的EyeQ5采用的台积电7纳米工艺,原本预计2018年底量产,结果推到2021年才能量产,会不会是在台积电那里排队排太久了,这个就不得而知了。Mobileye的下单量肯定远比初创企业要高,Mobileye尚且如此,那其他人呢?如果拜登对华为立场软化,允许台积电继续供货华为,那台积电的产能会吃紧到小客户要等4、5年也不是没可能。设计一个AI芯片可以说没有门槛,但要想量产,难比登天。特斯拉找上博通,恐怕主要原因还是能搭博通的顺风车,毕竟这是台积电十大客户之一。佐思 2021年研究报告撰写计划

「佐思研究年报及季报」
「佐思研究月报」
车联网月报 | ADAS/智能汽车月报 | 汽车座舱电子月报 | 汽车视觉和汽车雷达月报 | 电池、电机、电控月报 | V2X与车路协同月报
报告订购联系人: 佐思客服 18600021096(同微信) 廖棪 13718845418(同微信)