宋睿华、万小军、黄民烈谈自然语言生成现状:关于创作、多样性和知识融合

宋睿华:人工智能真的在创作吗?

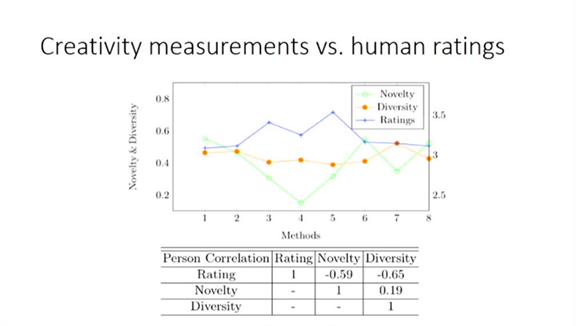
1、如何评价人工智能创作?




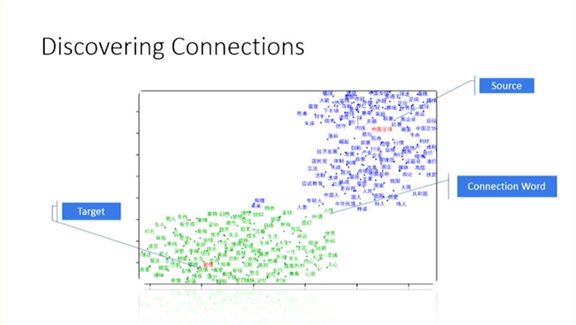
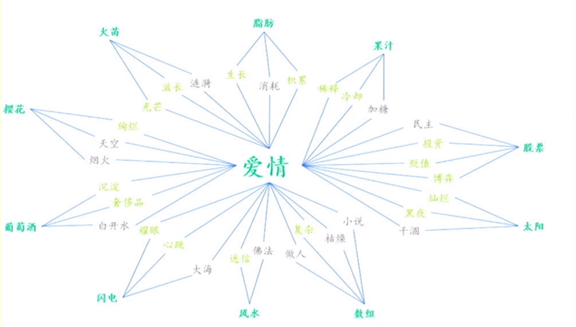
2、人工智能可以创作比喻吗?

3、人工智能可以创作剧本吗?


创意性的度量很重要;
新颖的组合(比如比喻句)会给用户带来耳目一新的感觉;
最后,我们希望人工智能不要拘泥于用生成模型,最重要的是给大家带来新意和乐趣。
万小军:多样化文本生成

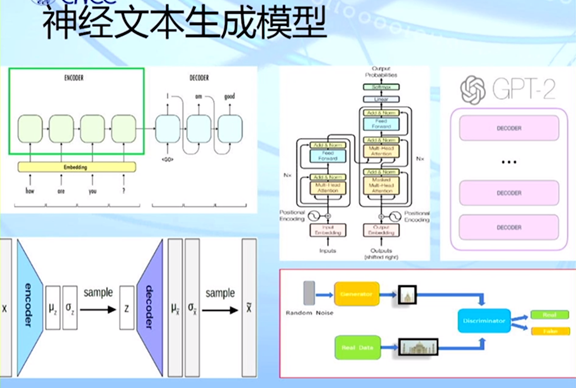
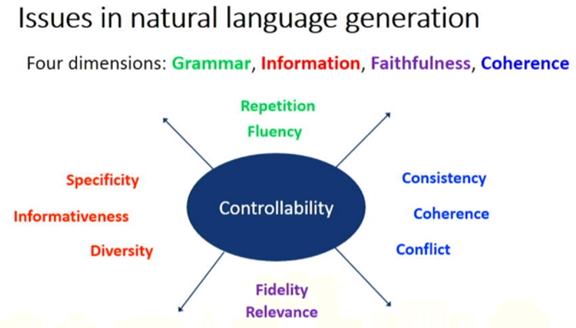
多样性(Diversity)差:最后生成的文本有很多类似的。 连贯性(Coherence)差:生成多句子文本时没有很好的篇章连贯关系。 保真性(Faithfulness)差:最终生成的文本总会出现一些信息错误,与所输入的数据或素材不相符。比如我们输入的数据中写的是“张三的年龄为18岁”,但生成的结果可能是“李四的年龄为18岁”。

定义1:输出与输入不相似
定义2:同一输入的多个输出不相似
定义3:不同输入的输出不相似

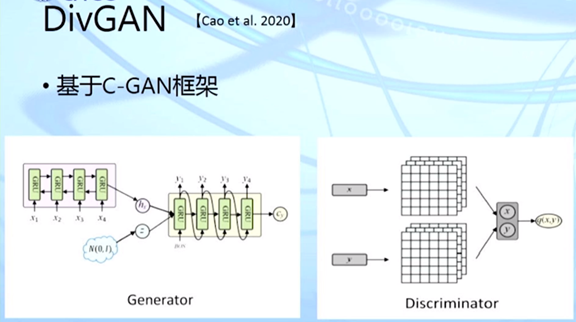
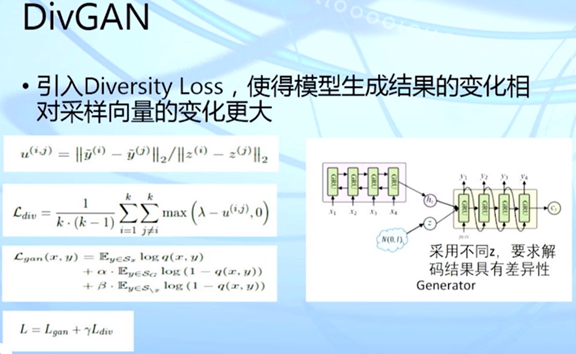
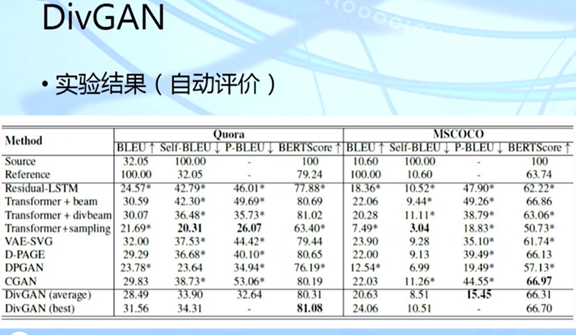
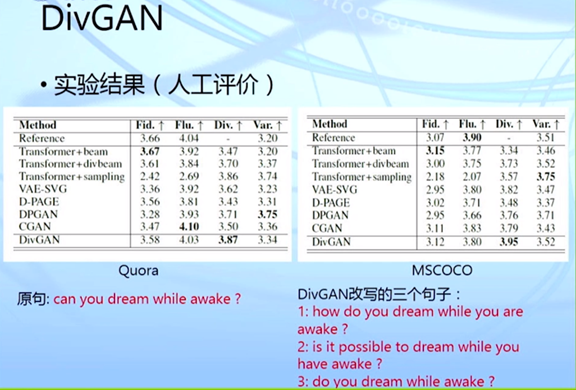
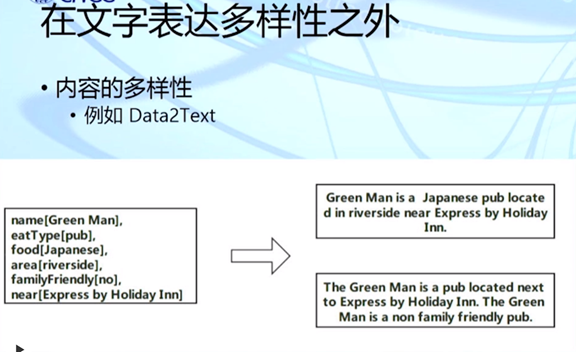
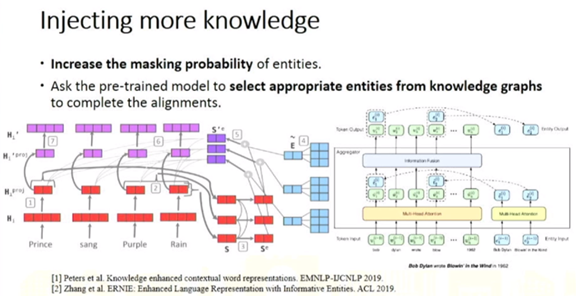
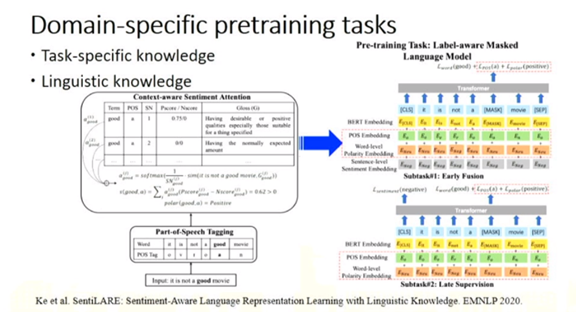
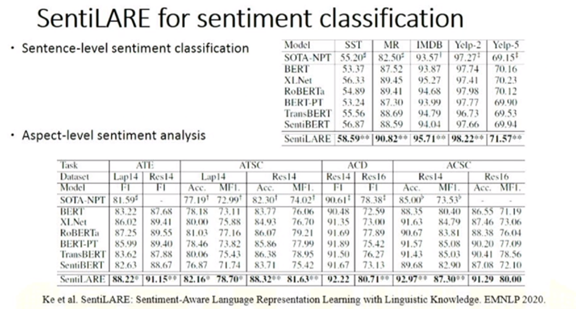
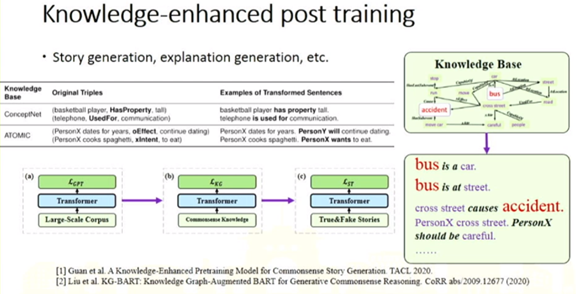
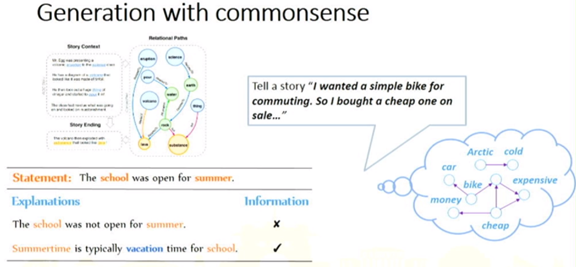
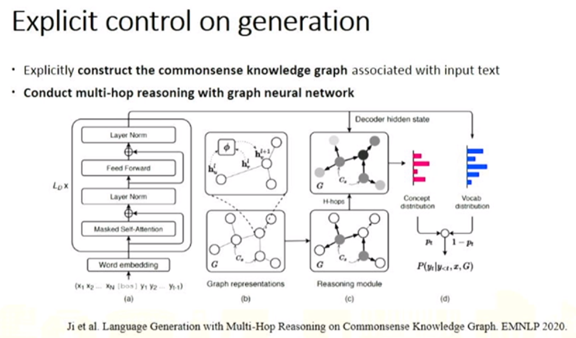
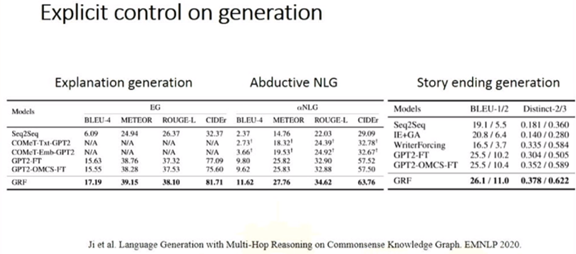
黄民烈: 基于预训练模型的语言生成











点击阅读原文,直达NeurIPS小组!
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。