苹果造车先造芯:苹果芯片足以超越英伟达Orin,碾压特斯拉FSD
近期车用芯片供货紧张导致大众部分停产,再次突显了芯片对汽车的重要性,也显示出握有上游资源的重要性,对传统车厂来说这是一次警告,对苹果来说,则是一则喜讯。苹果在芯片领域耕耘多年,拥有丰富的资源。苹果可以用手机巨大的出货量摊薄汽车芯片高昂的研发成本,以高性价比超越英伟达和Mobileye,当然也可以轻松碾压特斯拉。同时亦可借助芯片提升造车的成功机率。
汽车进入智能化时代后,几颗关键的主芯片,包括汽车座舱、智能驾驶和V2X芯片,都与手机SoC芯片高度重合,手机领域芯片稍作修改就可用于车载领域。这也使得高通、华为、联发科、三星手机芯片巨头纷纷进入车载领域。

苹果自动驾驶原型车上搭配的大量传感器
2020年11月11日,苹果自研芯片M1正式亮相,这颗M1芯片是苹果从手机领域向手机以外领域扩展的标志,这颗芯片稍作修改就可以用于汽车座舱和无人驾驶。苹果收购了英特尔的基带团队,将来也能推出5G V2X芯片。
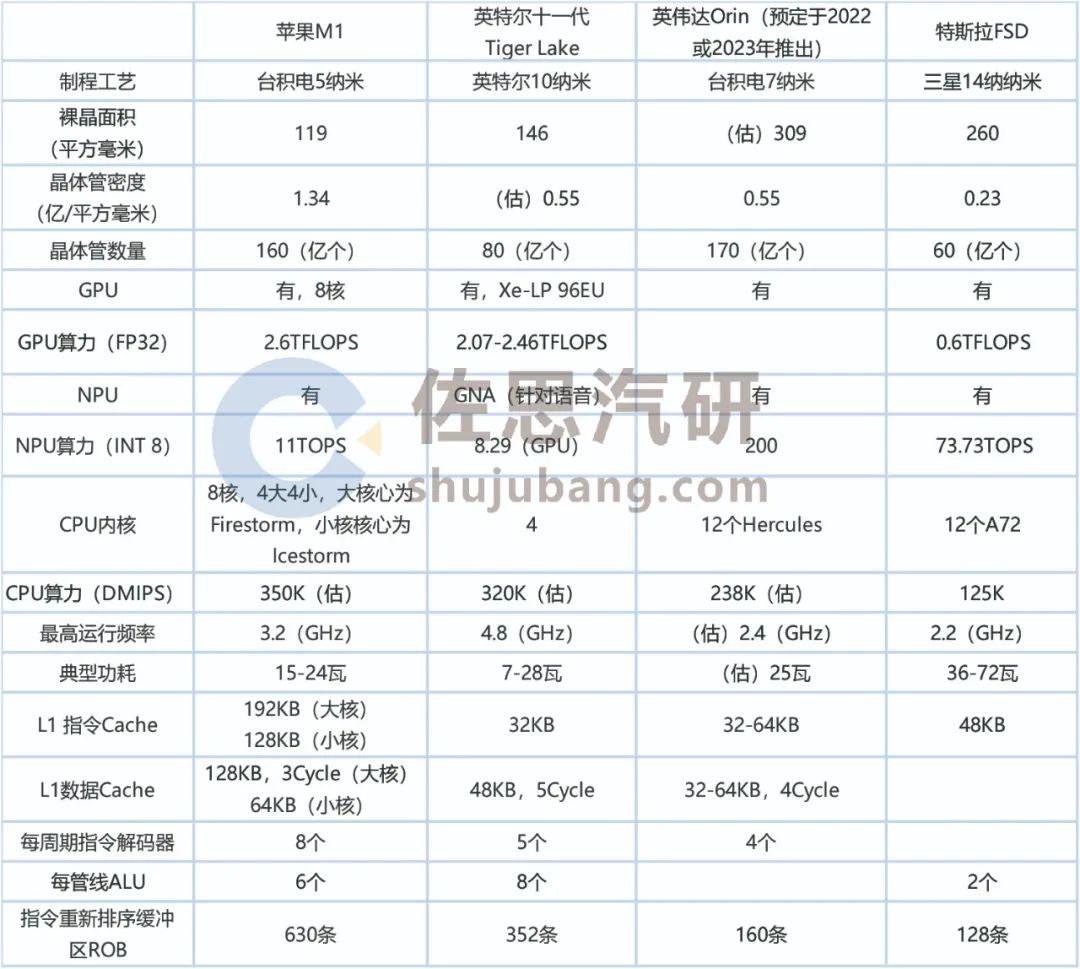
苹果这么做,复用了A14的设计,摊薄了成本,后续苹果会推出一系列优化过后的芯片,性能将更强。GPU算力上,M1已经是英伟达Xavier的两倍,英伟达的Xavier的GPU算力是1.3FLTOPS(FP32),深度学习上,Xavier比较高,有30TOPS(INT8)。但M1要想做到Orin的200TOPS(INT8)也易如反掌。
英伟达最新的A100 GPU是采用台积电7纳米工艺制造的,总共有542亿晶体管,裸晶面积有826平方毫米,晶体管密度仅为0.656亿/平方毫米。跟苹果M1的密度差异巨大,要知道A100是纯GPU,电路比较单一,互连较少,很容易做高密度,如果是Orin这种SoC,密度会下降很多,估计只有0.55亿/平方毫米。不过这也算不错。
英伟达的GA104采用三星的8纳米工艺,晶体管数量只有174亿个,裸晶面积高达392平方毫米,晶体管密度只有0.444亿/平方毫米,台积电的7纳米工艺轻松秒杀三星的8纳米工艺。如果Orin用三星的8纳米工艺,裸晶面积会高达500平方毫米,面积大一倍,硬件成本也几乎增加50%以上。因为GPU的众核架构,内部连线多,晶体管密度很难提高,但GPU擅长并行计算,NPU只能做MAC运算,NPU替代不了GPU ,GPU还得留着。
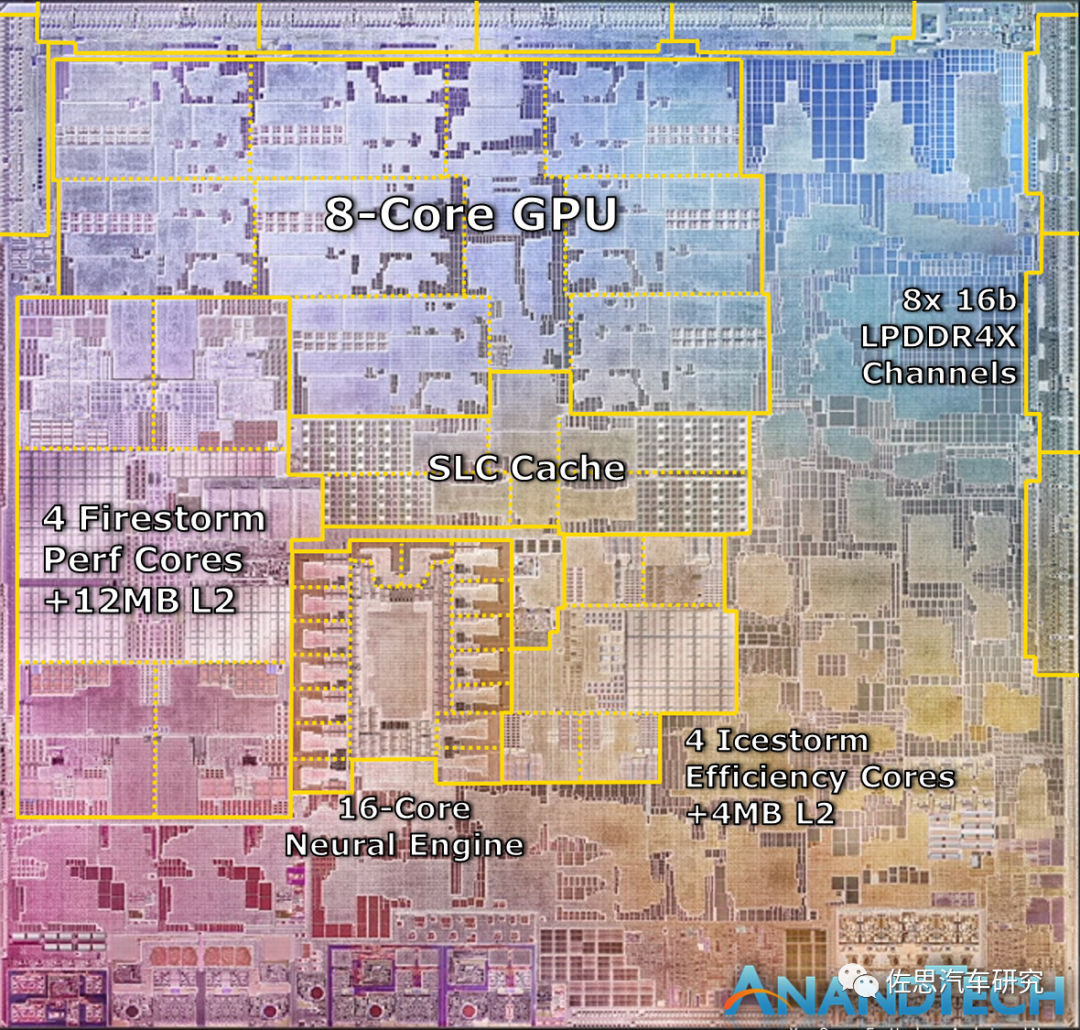
苹果M1的裸晶图
再来看CPU部分,做自动驾驶SoC,CPU的算力需求一样很高,传统智能驾驶的定位、传感器融合、规划、决策、通讯性能都取决于CPU,人工智能的NPU算力只负责感知中的深度学习卷积运算,面非常窄,80%的性能还是由CPU决定,按照ARM的观点,L4级自动驾驶芯片的CPU算力要大于250K DMIPS,同时功耗要低于30瓦。

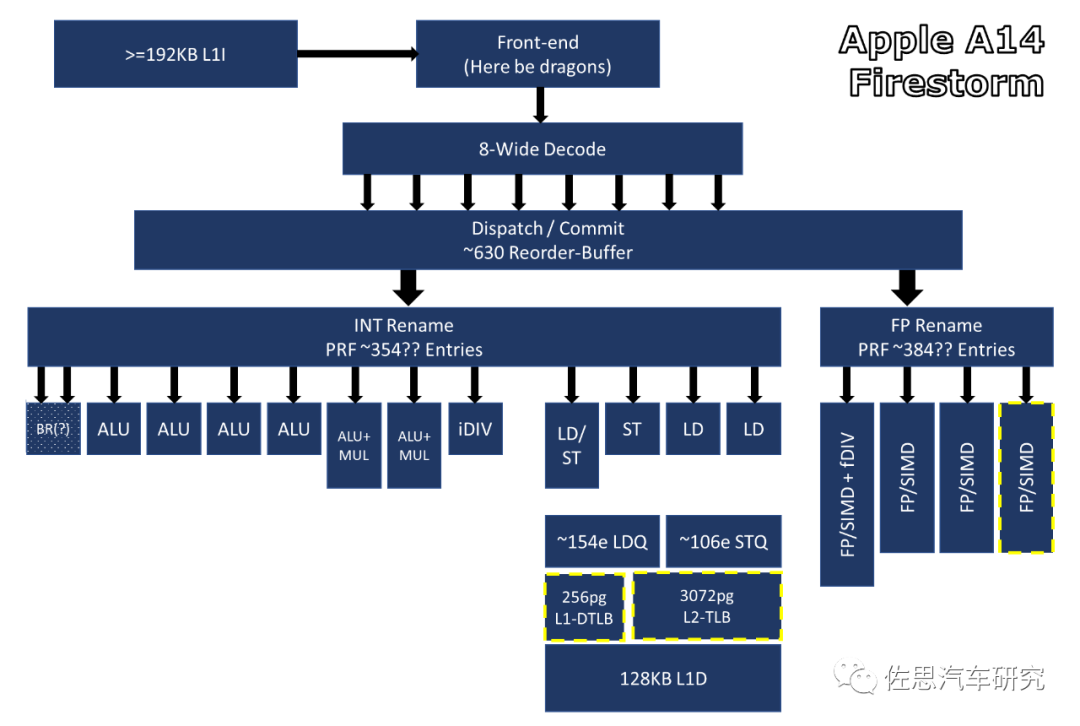
CISC指令的长度不固定,即1-15比特。RISC则是固定的。因此长度固定,可以分割为8个并行指令进入8个解码器,但CISC就不能,它不知道指令的长度,因此需要预测指令的长度,也就是分支预测Branch predictor,在分支指令执行结束之前猜测哪一路分支将会被运行,以提高处理器的指令流水线的性能。分支预测器猜测条件表达式两路分支中哪一路最可能发生,然后推测执行这一路的指令,来避免流水线停顿造成的时间浪费。如果后来发现分支预测错误,那么流水线中推测执行的那些中间结果全部放弃,重新获取正确的分支路线上的指令开始执行,这招致了程序执行的延迟。这就好像火车过岔路口,不知道哪一个正确,走过去一看,错了,只能倒回来走另外一条。
现代微处理器趋向采用非常长的流水线,因此分支预测失败可能会损失10-20个时钟周期。越长的流水线就需要越好的分支预测。分支预测器异常复杂,这就使得解码器很难增加,英特尔通过CPU内部的微操作,经历长时间研发,增加到5个(1个复杂解码器+4个简单解码器)。不过遇到有些长指令,CISC可以一次完成,RISC因为长度固定,就像公交车站,一定要在某个站停留一下,肯定不如CISC快。也就是说,RISC一定要跟指令集,操作系统做优化,RISC是以软件为核心,针对某些特定软件做的硬件,而CISC相反,他以硬件为核心,针对所有类型的软件开发的。
英伟达照搬Cortex-A78,其解码器只有4个,很难增加,那样等于重新自研架构了,可英伟达已经放弃自研架构了,M1的指令重新排序缓冲区ROB也具备压倒性优势,这就是自研架构的优越之处。
再说特斯拉芯片设计能力远逊于英伟达,英伟达都选用ARM公版架构,特斯拉自然不可能自研架构,特斯拉下一代采用台积电工艺的二代FSD芯片,其CPU估计会选用ARM Cortex-A76,因为第一代FSD是2019年4月推出的,采用的是ARM在2015年推出的A72架构,第二代FSD预计2021年或2022年推出,最有可能选用的CPU架构是ARM在2018年推出的A76架构。
现代手机芯片一般都是大小核设计来控制功耗,苹果、高通都是功耗控制顶尖高手。特斯拉显然没有这个能力,直接堆叠了12个A72,第一代FSD功耗高达36瓦,峰值可能达72瓦,这个肯定无法通过ASIL车规的。Orin的8核,应该也是大小核设计。第二代FSD估计只会增加比较容易做的NPU,为降低功耗,CPU方面不会增加多少性能,估计仍然是125-150K左右。
苹果认为多核是无意义的,CPU通用计算能力在某些特定场合是要下降很多的,因此苹果提倡多个专核或者叫硬核。M1的专核包括图像处理、视频编解码、音频处理、加密解密、神经网络加速。用在座舱或自动驾驶领域,可以把音频处理、加密解密、视频编解码换成双目视差、光流、ISP。
M1几乎和A14一样,研发成本可以忽略。而A14的成本大约为75-80美元,M1可以再低一点点,大约70美元,即使M1将FPU提高到200TOPS(单纯增加FPU几乎不增加研发成本,堆叠更多MAC而已),其价格也会远低于英伟达Orin的价格,大约只是英伟达的1/2-1/3。不过苹果不会正面与英伟达竞争,苹果不会卖芯片,苹果还是会打造自己的生态体系。这一次是电动车生态体系。
除了苹果,高通Ride的性能也足以抗衡英伟达Orin,高通有着每年至少6亿片的出货量,也可以分摊很多成本,包括研发成本和硬件成本。
要看到A14几十亿美元的研发经费,还有上亿片的订单数量,世界上没有第二家企业能做到单一芯片上如此大的出货量和如此大的研发投入(高通能达到这个出货量,但单一芯片的研发投入肯定无法和一年只做一个芯片的苹果比)。如果只有几十万片的订单,最终摊在芯片上的成本可能要上万美元,再有就是目前高性能计算芯片晶圆代工被台积电垄断(三星的8纳米LP那可怜的晶体管密度连台积电的12纳米都不如,英伟达迟早也得转移到台积电代工,否则等着被英特尔或AMD碾压),产能非常紧张,一些几百万片的订单被台积电推后超过1年。而苹果是台积电第一大客户,自然不会担心供应链的问题。中国急需发展的是晶圆代工而不是短平快且缺乏技术含量的的AI芯片设计,即使设计出来,也没没有对应的代工产能,只能是纸上芯片。
汽车进入电动化和智能化时代后,出现两大变化,一是造车门槛大大降低,二是芯片重要性大大提升。燃油车和非智能化时代,苹果无法在汽车领域复制其手机领域的成功,但电动化和智能化时代,苹果可以复制其在手机领域的成功。
你是否愿意保留一线城市的薪资,到二线城市工作?
「佐思研究年报及季报」
「佐思研究月报」
车联网月报 | ADAS/智能汽车月报 | 汽车座舱电子月报 | 汽车视觉和汽车雷达月报 | 电池、电机、电控月报 | V2X与车路协同月报
报告订购联系人: 佐思客服 18600021096(同微信) 廖棪 13718845418(同微信)