图网络在VLN中对于语言-场景-物体-方向之间的关联性学习

作者:澳大利亚国立大学在读博士 洪一聪

NeurIPS 2020 文章专题
第·10·期
 「NeurIPS 2020群星闪耀云际会·机构专场」圆满结束,公众号后台回复“NeurIPS”,获取完整版回顾视频及pdf资源!
「NeurIPS 2020群星闪耀云际会·机构专场」圆满结束,公众号后台回复“NeurIPS”,获取完整版回顾视频及pdf资源!


论文链接:
https://proceedings.neurips.cc/paper/2020/hash/56dc0997d871e9177069bb472574eb29-Abstract.html
代码链接:
https://github.com/YicongHong/Entity-Graph-VLN
一、背景:视觉与语言导航问题
视觉与语言导航 (Vision-and-Language-Navigation [1],或VLN) 定义了这样一个问题:将机器人 (Agent) 放入一个逼真 (photo-realistic) 的未知的场景中,它需要依照预先提供的自然语言指令,借助视觉信息导航至一个指定的地点。
( https://bringmeaspoon.org/ )
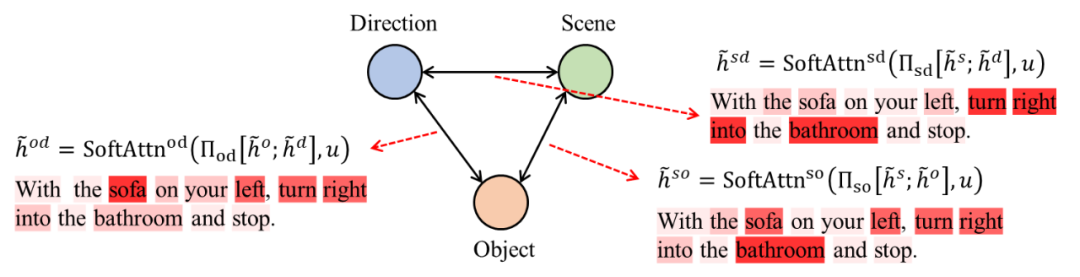
在过去有关VLN的工作中,研究者们普遍使用简单的语言-视觉跨模态注意力机制 (cross-modal attention) 来学习和利用二者间的对应关系,即:在每一个时间点,关注与当下的全景图 (panorama) 最相关的指令,并选择与该指令最相关的单视图 (single-view) 方向作为下一步导航的方向。然而,该文作者认为上述方法并不能高效地学习语言或视觉信息,同时忽略了场景中能够辅助定位的物体。举一个简单的例子,在以下的指令中:
“With the sofa on your left, turn right into the bathroom and stop.”
它包含了三种关键的语境信息:场景Scene,物体Object和方向Direction。这三种信息并非独立,而是相辅相成地明确了导航的任务:Agent首先需要到达沙发Sofa (物体) 的右侧,然后右转turn right (方向) 至浴室bathroom (场景) 里,最后才停止导航stop (方向) 。
同时,语言中的这三种信息与三种视觉信息是有对应关系的,即场景特征 (scene features) ,区域特征 (regional features) ,和方向信息/机器人动作 (directional/action encoding,我们将方向/动作归纳为一种视觉信息) 。我们可以想到,学习这些复杂的信息很难,并且学习的关键是了解语言和视觉二者内部 (intra-) 和之间 (inter-) 的关系。
二、方法:视觉与语言对象关系图
图网络在各个领域和问题上均有广泛的应用,它常被作为模拟不同对象间关系的方法。在本文中,作者提出利用图网络来进行语言和视觉的学习,命名为视觉与语言对象关系图 (Language and Visual Entity Relationship Graph) 。该关系图包含两个子图,分别为语言子图和视觉子图,两个子图分别学习指令中不同部分文本间的关系和不同视觉信息之间的关系,同时二者进行交互,以学习并利用跨模态信息的关联来指导导航。见下图。
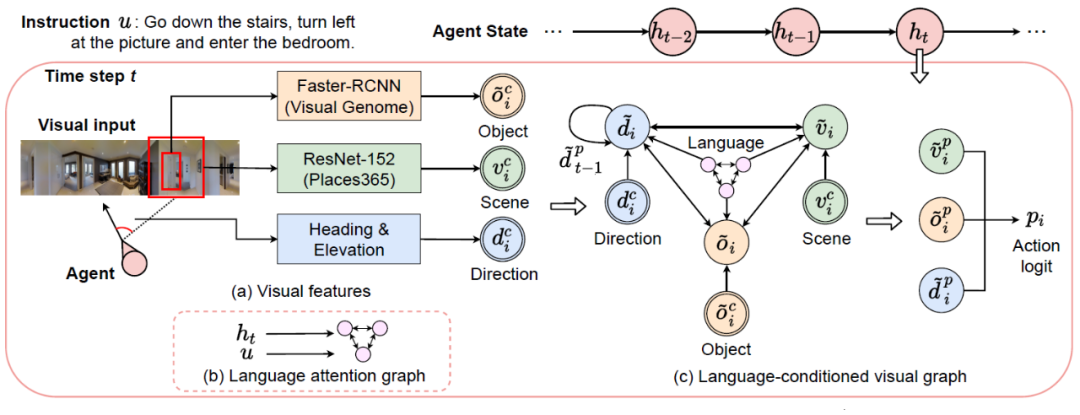
在每一个决策时刻,此方法对于每一个可探索的方向 (navigable direction) 都会构造一个独立的对象关系图以推测该方向的动作逻辑/评分 (action logit) ,评分最高的方向将会被选择作为导航方向。接下来,我们将详述两个子图。
1. 语言注意力图 (Language Attention Graph)
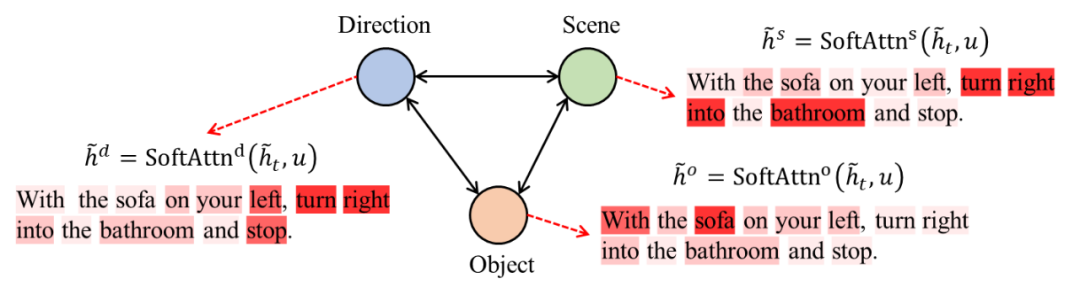
语言子图,即语言注意力图,由双层注意力机制构成。首先,如图2所示,图网络中的每一个节点先利用agent的状态 (state) 进行对语言的关注。我们称关注结果为特定语义 (specialized contexts) ,即每一个节点分别提取有关场景、物体、方向的文本信息。其次,如图3所示,图网络中的每一条边借助任意一对特定语义进行关于语言的第二层关注,由此模拟两种不同特定语义之间的关联,例如场景-方向间的文本关联。我们称此关注结果为关联语义 (relational contexts) 。语言注意力图所产生的特定语义和关联语义将对理解视觉和方位信息给予关键的指导。
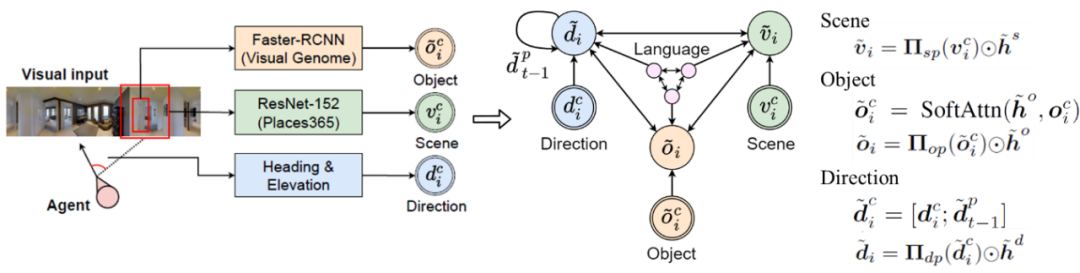
2. 语言调控的视觉图 (Language-Conditioned Visual Graph)
视觉子图,即语言调控的视觉图,其对视觉信息的处理同样包含两个步骤。首先,三种视觉信息,场景特征 (scene features) ,区域特征 (regional features) ,和方向信息 (directional encoding) 会分别从观察中提取,并初始化为视觉图中的三个节点。在初始化过程中,每一个节点的信息都经由先前得到的特定语义调控,从而使得初始化的各种视觉特征与指令里的关键文本相对应。借此,两个子图之间建立了第一个链接,即关于特定语言和特定视觉信息的链接。
为了模拟和学习不同视觉信息之间的关系,视觉图在每一条边上进行关于任意两种视觉特征的信息传递 (message passing) 。如图五所示,场景节点 (scene node) 接收了来自方向节点和物体节点的信息,并同时将自身的初始信息传输给方向节点和物体节点。每一条信息的传递均由先前得到的关联语义调控,从而使信息中不同视觉特征的交互结果与指令里描述关系的文本相对应。借此,两个子图之间建立了第二个链接,即关于关联性语言和视觉信息的链接。在一轮信息传递完成后,每一个节点将会更新自己的信息,即将自身的初始信息与其所接收的信息相加。
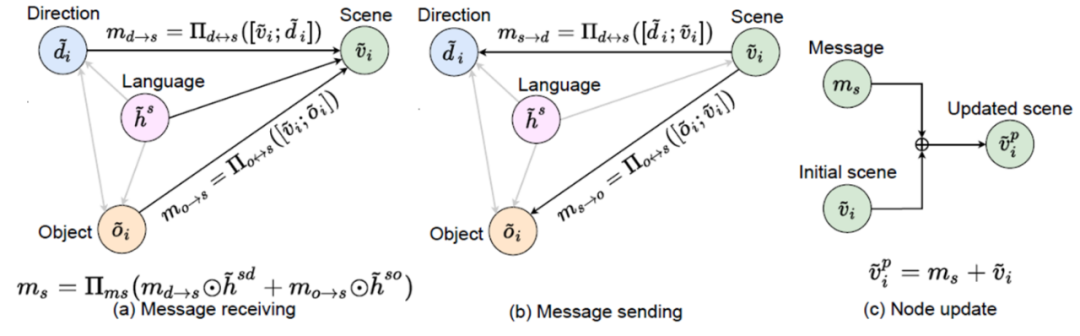
读者可以注意到,两个子图之间的两个链接促使语言和视觉的理解和学习相辅相成:视觉特征的提取需要符合语言的指导,而语义信息的理解和提取需要对学习视觉特征提供有效的帮助。
3. 决策与训练 (Decision Making and Training)
对于每一个可探索的方向,三个更新后的视觉节点将被级联,然后投影成一个决策分数。在所有可探索方向中,决策分数最高的方向将被选取为在该时刻的导航方向。
关于训练,该文采用了模仿学习 (Imitation Learning) 和强化学习 (Reinforcement Learning) 的混合策略[2],以在高效学习的同时,确保模型在非训练数据上的泛化能力。

三、实验与结果
1. 数据集和指标 (Datasets and Metrices)
该方法在两个标准的VLN数据集上进行了测试,分别为Room-to-Room (R2R) [1]和Room-for-Room (R4R) [3]。多个标准指标被采用:路径长度 (TL) ,导航误差 (NE) ,成功率 (SR) ,最近点成功率 (OSR) 和路径长度加权成功 (SPL) [4]。以及多个保真度指标:路径长度加权覆盖范围 (CLS) [3],归一动态时间规整 (nDTW) [5]和成功加权归一动态时间规整 (SDTW) [5]。
2. 对比结果 (Comparison to SoTA)
如表1所示,与众多先前的最佳方法相比,该文所提出的视觉与语言对象关系图在R2R测试集上获得了最优的结果。甚至超越了先前使用预训练 (pre-training) 的方法,并且在NE指标上获得了较大的进步。
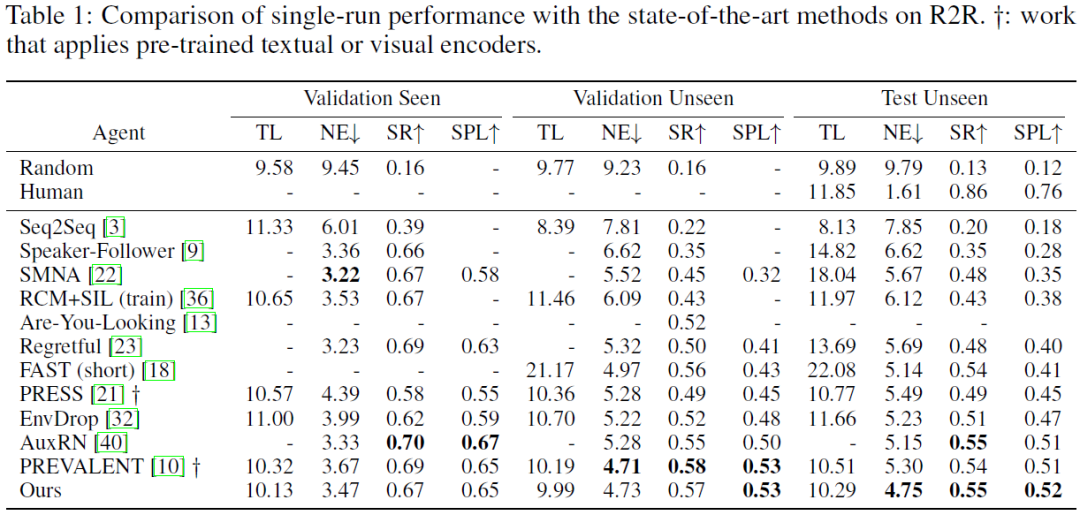
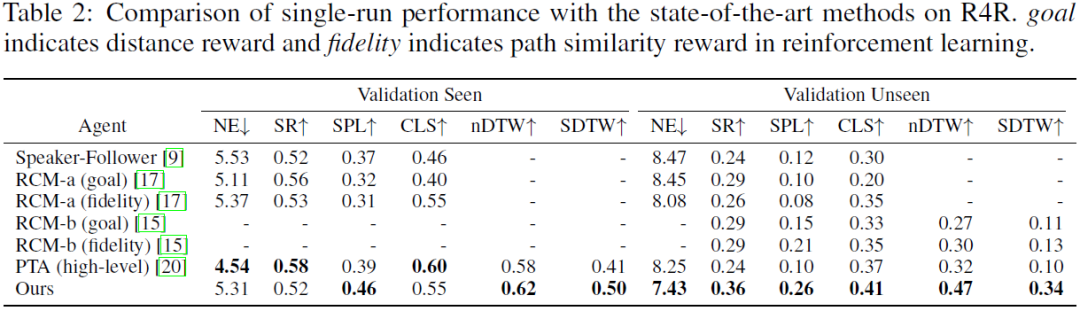
表2展现了该方法在R4R数据集上的表现,其在验证集上获得了大幅的提升。同时,保真度指标上的优越表现验证了此方法能帮助agent更好的执行预先提供的语言指令。
3. 消融实验 (Ablation Study)
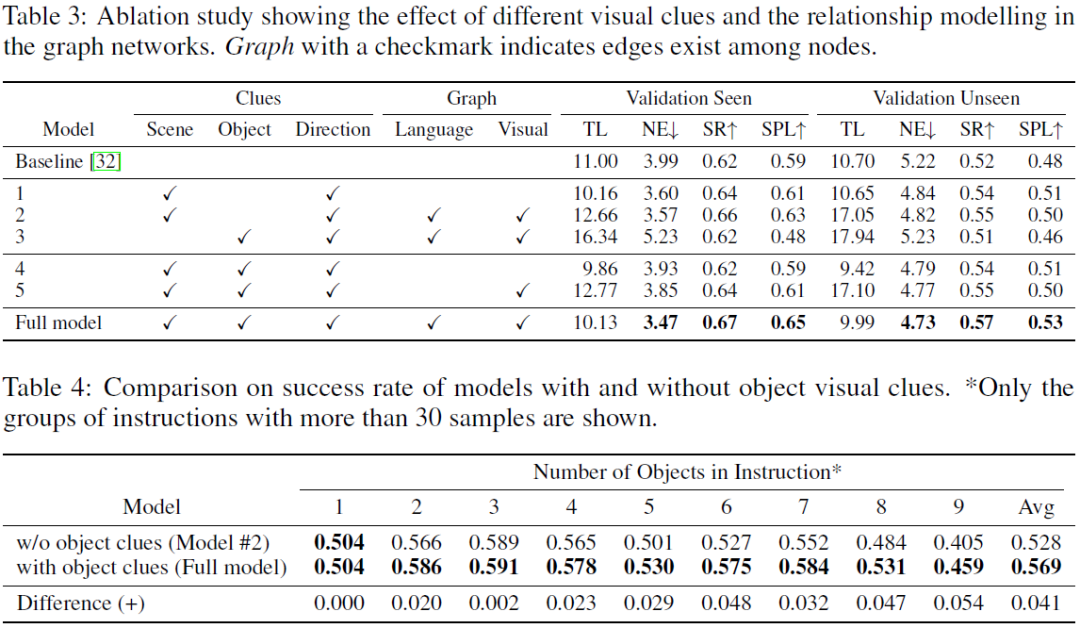
如表3和表4所示,通过消融实验,我们可以了解到:引入物体信息,并且利用两个图网络来学习信息的关联性可以使导航结果获得最大的提升。同时,随着语言指令中物体数量的增加,引入了物体的视觉信息的图网络能更有效地解决导航问题。
四、结论和未来方向
该论文提出了视觉与语言对象关系图以学习语言-场景-物体-方向间的内在关联,从而增进对导航任务中多模态信息的理解,以提升决策的效率与准确性。此方法在R2R和R4R的VLN任务中均表现出了优越的性能,并且更好地解决了指令中含有较多物体的导航任务。
关于未来方向,作者提出:虽然该文仅将物体信息作为图网络中的一个节点,但在VLN中,物体可以提供有助于进程监控 (progress monitoring) ,对象追踪 (instance tracking) 和奖励设计 (reward shaping) 的关键信息。在未来,结合图网络,进行上述方向的探索或许能使关于VLN问题的研究取得更大的进展。
最后,对于感兴趣的读者,欢迎阅读原文和补充材料以获取更多、更详细的算法论述,实现细节,实验结果,以及注意力和路径的可视化图。
滑动查看参考资料!

听说12月19日有个Party…

AI人的年底聚会,就差你了!
好吃!好玩!免费!
扫描下方二维码或点击文末“阅读原文”报名

点击标题阅读往期精彩👇
NeurlPS 2020 论文解读 ●●
// 1
// 2
// 3
// 4
// 5
// 6
// 7
// 8
// 9

扫码观看!
本周上新!

关于我“门”
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给“门”:
bp@thejiangmen.com


扫二维码|关注我们
让创新获得认可!
微信号:thejiangmen
点击“❀在看”,让更多朋友们看到吧~