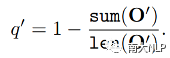研究动机
目前机器翻译在各个领域得到广泛应用,不同的机器翻译系统,对于同样的原文句子可能会给出不同的翻译结果(如表1所示),质量有好有坏。该如何自动评价译文的翻译质量呢? | |
| The water of the Yellow River comes from the sky, rushes to the sea and never returns |
| The Yellow River never comes back to the sea |
| The Yellow River comes from the sky, runs to the sea and never comes back |
| The water of the Yellow River came from the sky and ran to the sea |
| The water of the Yellow River comes from the sky, and the waves rush to the East China Sea and never look back |
目前的评价指标主要有两类。一类需要依赖参考译文,比如BLEU、TER、Meteor等,主要依赖机器翻译译文和参考译文之间的匹配程度,但参考译文在现实应用场景下往往难以获取。第二类评价指标不需要依赖参考译文,如质量评估Quality Estimation (QE),仅通过原文和机器译文对翻译质量进行估计。QE的粒度有很多种,包括词级别、句子级别、短语级别、文档级别等,本文主要关注词级别与句子级别QE任务。词级别QE将译文中的每一个词标记为“Ok”或“Bad“;句子级别QE给每一个句子标注一个[0, 1]之间的打分(0表示很好,1表示很差),这些标记都由人工标记得到,或基于人工编辑结果得到。表2展示了一个英-中语向的QE数据示例。 | this insubordination earned him a now famous reprimand from the King . |
| 这种 不 服从命令 的 态度 使 他 赢得 了 国王 现在 著名 的 训斥 . |
| O B B O O O O B B B B B O B B |
| |
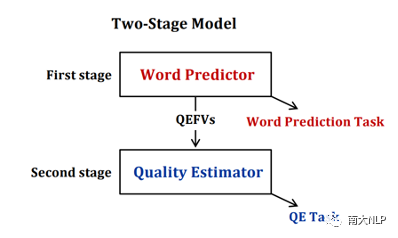
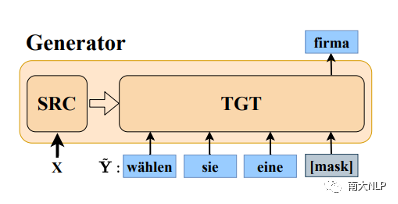
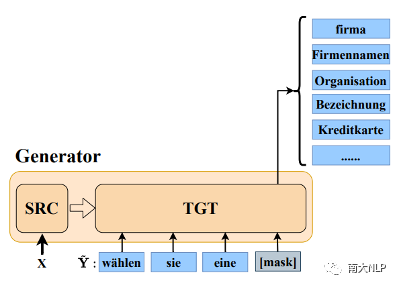
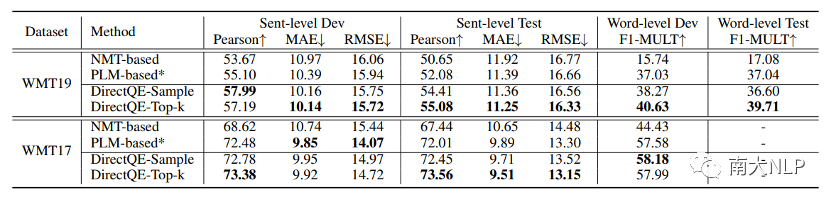
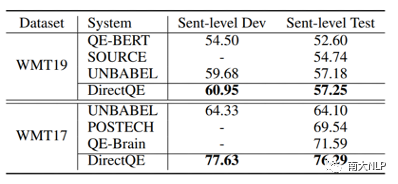
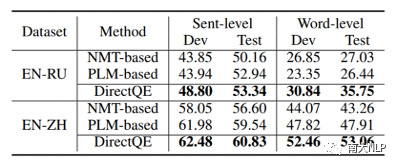
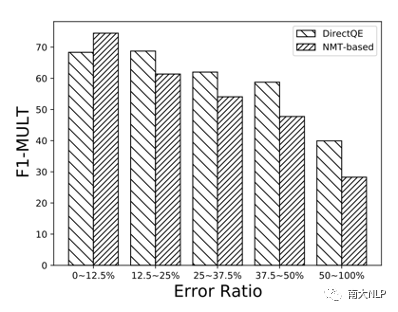
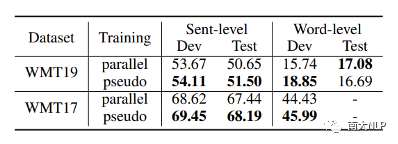
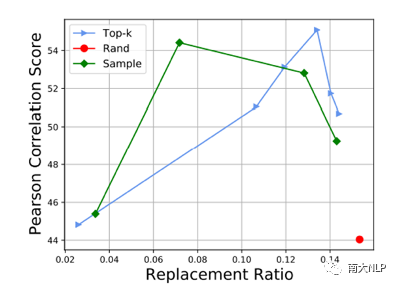
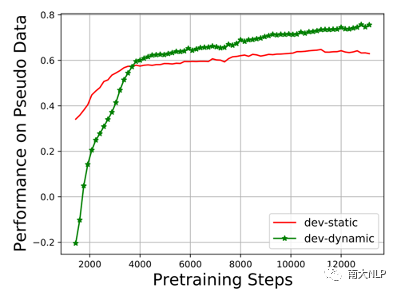
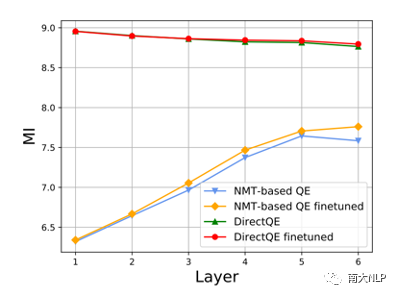
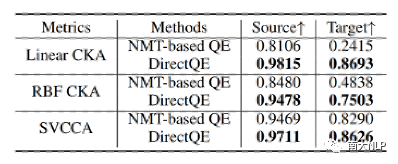
早期QE任务依赖人工设计的特征,例如原文、译文中的单词数量,词频等,但是该方法的适应性较弱,效果较差。随后有研究者使用神经网络对QE数据进行端到端建模,取得了一定的成绩。神经网络需要大规模数据进行训练,但是QE数据由于需要人工进行标记,暂时规模较小(万句级别),这限制了神经网络的训练。目前最流行的QE模型利用知识迁移技术,从无QE标记但具有大规模(百万句级别)的平行语料中迁移QE任务所需要的知识。Predictor-Estimator是一种流行的基于知识迁移的QE框架,它是一种两阶段模型(如图一所示)。第一阶段,预测器(Predictor)将在平行语料上进行预训练,其预训练任务一般为“词预测”类型的任务。第二阶段,使用预测器提取QE句对的特征,通过评估器(Estimator)学习如何在这些特征上拟合QE标记。图表 1:Predictor-Estimator框架图(from Kim et al., 2017)我们可以使用神经机器翻译模型NMT(Kim et al. 2017, Fan et al. 2018, Zhou et al. 2019)或者预训练语言模型PLM(Kepler et al. 2019, Kim et al. 2019)来作为预测器,使用LSTM模型作为评估器。该框架的问题在于,其两阶段之间存在差异,包括数据的差异和训练目标的差异。数据的差异是指,预测器在大规模平行语料上训练,平行语料由原文和正确译文组成;评估器在QE数据上训练,句对由原文和包含错误的机器翻译译文组成。训练目标的差异是指,预测器是在做“词预测”任务;评估器是在预测词和句子的质量。那么预测器的预训练过程与目标QE任务存在差异,会导致学习不到QE任务真正需要的知识,无法充分利用大规模双语平行数据。QE模型的现存问题主要是,1.大规模神经网络训练参数依赖大量数据;2.数据分布及训练目标的差异可能对两阶段训练带来不利影响。为了解决这两个问题,我们采取的改进方向是1.使用相同/相似的数据进行预训练;2.使用相同/相似的预训练目标。QE数据中包含一些翻译噪音,QE的训练目标需要质量标签。那么如何基于平行语料,获得带有一定噪音的数据,并且可以获得噪音数据的质量标签?我们的解决方法是,首先基于平行数据训练生成器(generator)进行词改写任务;接着对平行语料进行词改写,从而引入一定量的可控噪音并利用可控噪音自动生成质量标签。最终可以将这些生成数据提供给判别器(detector)直接为QE任务进行预训练。接下来具体介绍生成器的训练与生成过程。首先,我们以Masked Language Model (MLM)的方式训练生成器。给定平行句对,随机的隐藏(mask)译文中某个位置的词,然后让模型预测被隐藏的词(如图2所示)。生成器训练结束后,我们将使用生成器对平行语料进行转化,具体分为两个步骤。1. 生成伪造机器翻译译文。给定平行语料并隐藏译文中某个位置的词,让生成器进行预测并输出概率分布,根据概率分布采样新的词替换被隐藏词(如图3所示),即完成了对被隐藏词的改写。2. 生成对应标签。根据译文中的词是否被改写来获得词级别标签O^'={〖o^'〗_1,〖o^'〗_2,…,〖o^'〗_n }(见公式1),根据译文中被改写词的比例获得句子级别标签q'(见公式2)。通过生成器,我们能够将大规模平行语料转化为更大规模的伪造QE数据。比起平行译文,伪造的机器翻译译文在数据分布上与QE中的译文更加接近。同时,伪造QE数据针对每一个词有表示“是否由机器生成“的标签,对整个句子有表示”句子改写程度“的标签,形式上与QE数据类似。基于大规模伪造QE数据以及真实QE数据,我们将使用同样的训练目标,对判别器(Detector)分别在伪造数据上进行预训练、在真实数据上微调参数。最终也只需要使用判别器来做QE分数预测。我们主要测试了模型在英-德数据集上的性能,使用的QE数据集来自于WMT17以及WMT19的QE竞赛,平行语料来自于WMT19的QE竞赛。同时,我们也测试了模型在英-中,英-俄语言对上的性能。句子级别评价指标是皮尔森相关系数,词级别评价指标是F1-MULT。我们对比了Predictor-Estimator框架中的两种具体实现。一种是基于NMT的QE模型,具体实现仿照QE Brain模型(Fan et al. 2018);一种是基于PLM的QE模型,具体使用的PLM模型来自于huggingface。在本文的实现中,我们所提出的DirectQE参数量是最小的。实验结果如表3,4,5所示,可以发现我们的模型在绝大多数情况下都是具有优势的。为了找出我们模型性能具体的增长点,我们按照错误词的比例划分了真实QE数据集,并评估了模型在数据每个部分的性能。如图4所示,在翻译质量存在问题时(错误词比例>12.5%),DirectQE的性能更好。为了研究预训练使用的数据分布对QE性能的影响,我们使用基于NMT的QE模型,并且将其中训练预测器用到的平行语料替换为生成器制造的伪造机器翻译译文,其余部分均保持不变。从表6中可以看出,使用伪造译文的模型性能有所上升,说明对于QE任务而言,使用伪造译文预训练比平行译文更好。表格 6:使用伪造译文/平行译文训练基于NMT的QE系统为了研究预训练数据质量对QE性能的影响,我们测试了不同质量的数据下QE性能,这里数据质量具体指是译文质量,可以体现在替换词比例上(在相同替换策略下,替换词比例越大,译文质量越差)。从图5中可以看出,伪造译文质量太好或者太坏都不利于最终QE的性能。伪造译文质量太好(替换比例很低),句子将接近于平行语料本身,数据中几乎没有噪音;而伪造译文质量太差时,会破坏句子结构,与真实QE译文数据分布有较大差异。图5中红点表示使用随机噪音替换被隐藏词,此时的译文质量很差,可以看到QE性能也很低。在固定规模的平行语料上,生成器每一次采样会产生不同的伪造QE数据,最终用于训练判别器的数据规模是超百万级别的,且更多样化。为了研究多样性的价值,我们使用生成器产生了固定数量的伪造QE数据,对比了在固定生成的数据上以及持续生成的数据上预训练的模型性能。结果(图6)显示,伪造QE数据的多样性对提升模型性能来说很重要。词级别QE任务需要判别当前词的质量,那么模型在建模当前词时,包含更多当前词的信息是有必要的。为了体现模型隐层表示含有当前词信息的多与少,我们计算了隐层表示与当前词之间的互信息(模型指判别器/预测器)。在图7中可以看到,DirectQE学到的表示中包含有更多当前词的信息。假设当模型针对下游任务进行微调时,模型的隐层表示改变越小,则原始的表示更适合该下游任务。为了研究是否DirectQE可以学习到更加适合QE任务的表示,我们测试了在真实QE数据上微调前后,DirectQE和基于NMT的QE模型的隐层表示之间的相似度。表7显示,DirectQE隐层表示的相似度较高,说明DirectQE可以学到更加适合QE任务的表示。总结
大规模的QE模型需要大规模数据进行参数训练。现有的两阶段方法,由于数据和训练目标差异,无法最大化利用大规模平行语料知识。我们提出一种直接为QE模型进行预训练的框架(DirectQE)——使用生成器由平行语料得到伪QE数据,而后使用判别器,在伪QE数据上进行预训练,并且使用真实QE数据微调。我们模型的优势是,参数规模更小,模型性能更好,并且易于使用。未来,我们将考虑使用更多样化的方式来构造伪QE数据,进一步缓解数据差异带来的影响,最大程度利用大规模语料,提升QE模型性能。
[1]Kepler et al. 2019. Unbabel’s Participation in the WMT19 Translation Quality Estimation Shared Task.
[2]Zhou et al. 2019. SOURCE: SOURce Conditional Elmo-style Model for Machine Translation Quality Estimation.
[3]Kim et al. 2017. Predictor-Estimator using Multilevel Task Learning with Stack Propagation for Neural Quality Estimation.
[4]Kim et al. 2019. QEBERT: Bilingual BERT Using Multi-task Learning for Neural Quality Estimation.
[5]Fan et al. 2018. ”Bilingual Expert” Can Find Translation Errors.

点击阅读原文,直达AAAI小组!
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。