(项目解析+代码实战)大佬手把手带你kaggle比赛进阶



入门深度学习后,如何提升自己的实战能力?
最好的选择当然是做项目打比赛。kaggle竞赛平台凭借其影响力大,奖金丰厚,实战项目赛事种类和层级丰富,提升实战能力明显等优势,无论是提升自我深度学习的实战能力,还是为求职增添一抹光彩,都是最好的选择之一。


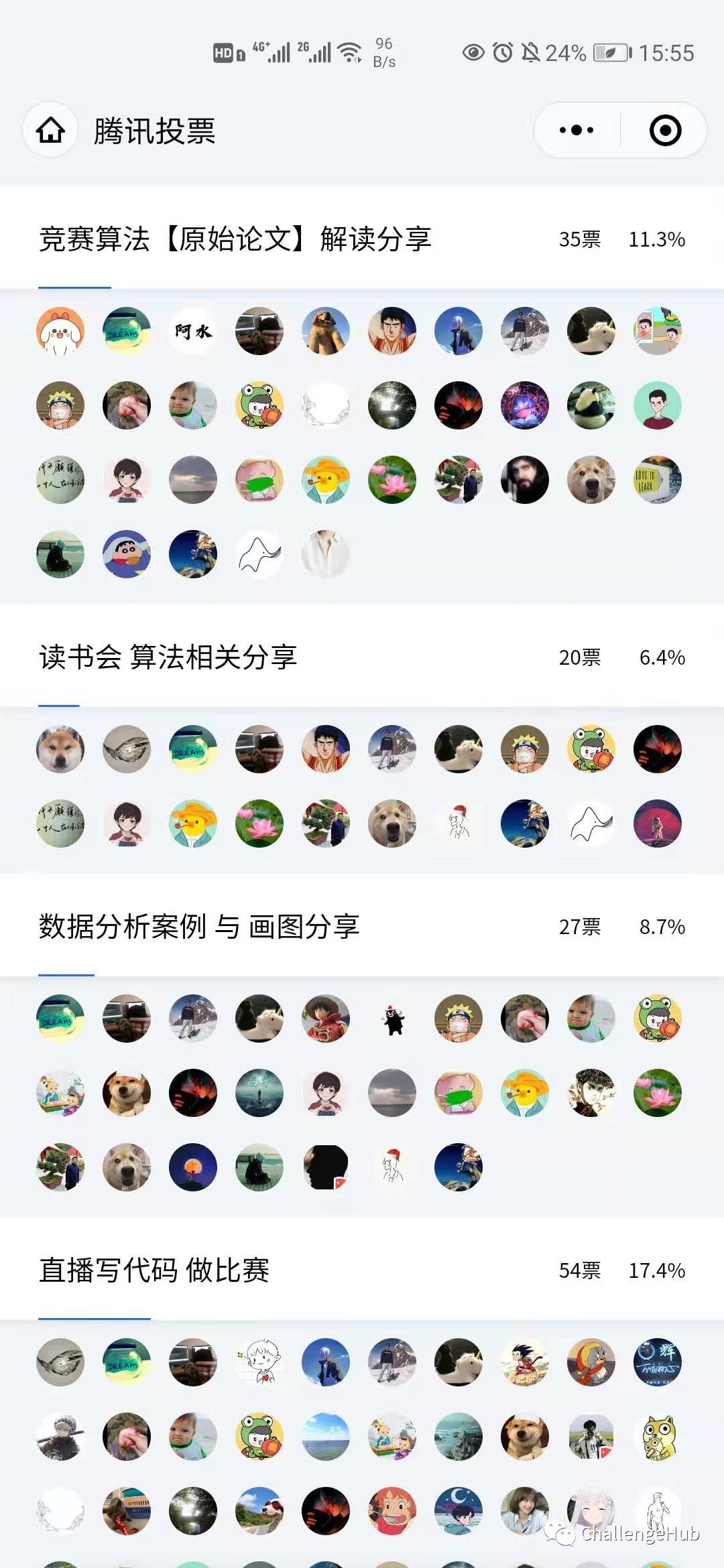
AI研习社竞赛频道累积输出50+场比赛,涵盖了入门到进阶的各种类型赛题 250+baseline。截止目前,竞赛频道共有3000+积极参赛的同学,AI研习社在和大家的比赛前后交流过程中,发现大家对提升自己的实战水平有着迫切的需求,但是却苦于没有一个行之有效的路径。
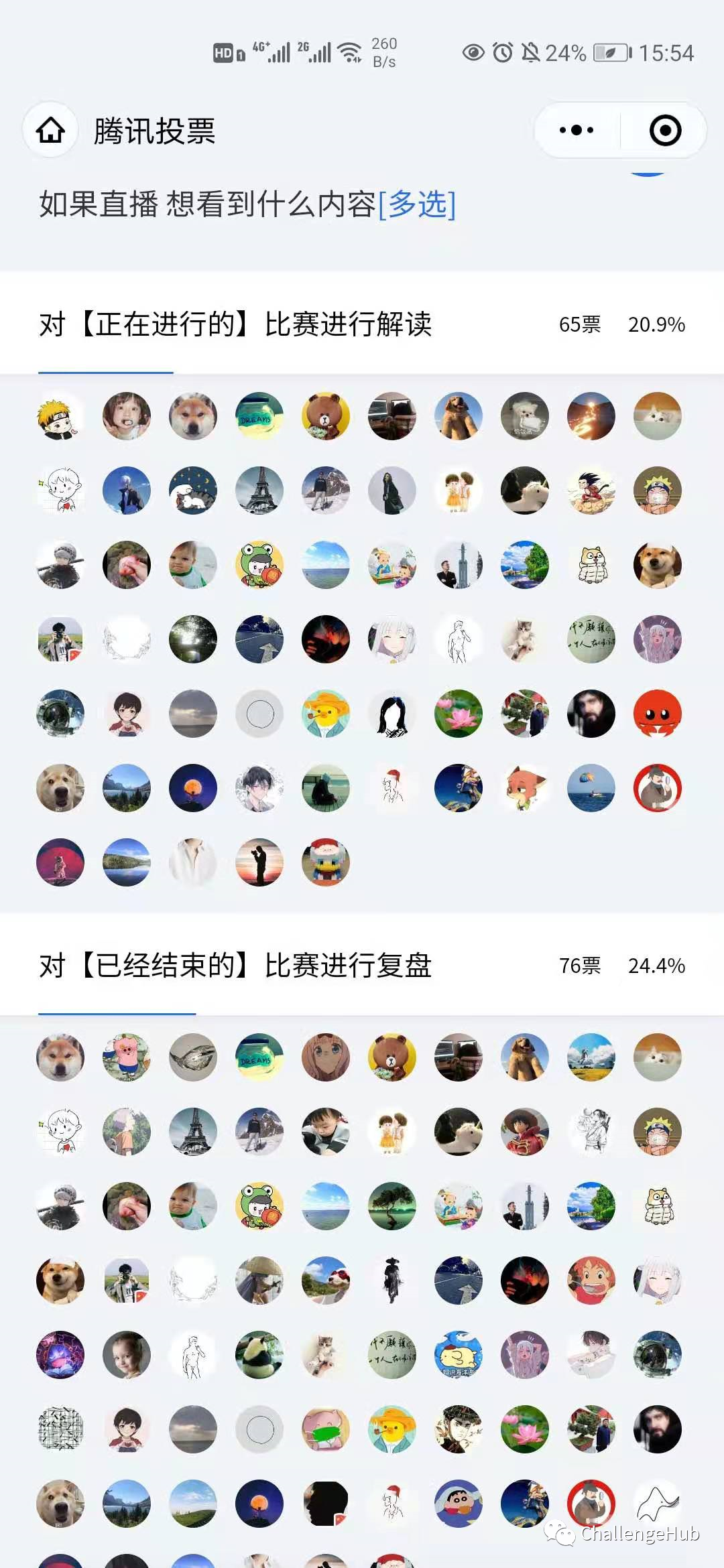
怎么选择适合自己的比赛?怎么解决比赛中的调参等问题?怎么上分提高比赛成绩?怎么站到大佬及时反馈和交流比赛经验?
针对以上相关问题,在做过300+竞赛选手?的调研,经过4次迭代后,我们重磅推出了这门【kaggle竞赛指南——从入门到拿牌】课程。






以上次阿水老师讲的《45分钟LightGBM必知必会》为例和大家展示下授课情况:
阿水老师结合LightGBM的优点、原理,还有如何具体调用、调参、优化、部署等问题做了深入浅出地作了介绍。

LightGBM原理可以分解为
单边梯度抽样算法
直方图算法
互斥捆绑算法
深度限制的leaf-wise算法
类别特征最优分割
特征并行与数据并行
由于篇幅原因下面简单介绍一下单边梯度抽样算法和直方图算法。
1、单边梯度抽样算法。
对样本进行取样,选择部分梯度小的样本 让模型关注梯度高的样本,减少计算量
单边梯度抽样算法解决梯度权重的问题,先把样本按梯度排序,在梯度较小的样本中随机选择部分样本加入训练,然后让模型关注梯度高的样本,减少计算量。



2、直方图算法
对连续特征离散化,然后用直方图来统计连续特征的取值,然后用直方图进行计算。假如我们这个地方把我们的一个连续特征把它映射取值为空间为k的直方图里面,然后我们从 k里面去算具体的分裂的节点的。这种方法要比原生的方法要快,而且直方图可以进步一步内存压缩。
LightGbm有两种接口,一个是原生的接口,一种是sklearn。
其中原生接口通过LightGBM.Dataset定义,
lgb_train = lgb.Dataset(X_train, y_train,
weight=W_train, free_raw_data=False)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train,
封装成Dataset以后,LightGBM的训练就变成了lgb.train,其中params为超参数设置,binary为二分类,logloss是评价指标。categorical_feature=[21],通过特征次序指定特征,第22个为类别特征。
# specify your configurations as a dict
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'binary_logloss',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0
}
# generate feature names
feature_name = ['feature_' + str(col) for col in range(num_feature)]
print('Starting training...')
# feature_name and categorical_feature
gbm = lgb.train(params,
lgb_train,
num_boost_round=10,
valid_sets=lgb_train, # eval training data
feature_name=feature_name,
categorical_feature=[21])
print('Finished first 10 rounds...')
# check feature name
print('7th feature name is:', lgb_train.feature_name[6])
print('Saving model...')
# save model to file
gbm.save_model('model.txt')
print('Dumping model to JSON...')
# dump model to JSON (and save to file)
model_json = gbm.dump_model()
with open('model.json', 'w+') as f:
json.dump(model_json, f, indent=4)
特征重要性
lightGBM提供特征重要性计算,大家都知道树模型使用基尼指数信息增益衡量特征重要性。我们直接条用gbm.feature_importance()就会得出特征重要性。
# feature names
print('Feature names:', gbm.feature_name())
# feature importances
print('Feature importances:', list(gbm.feature_importance()))
加载模型
LightGBM可以保存为pickle,json , txt格式。加载直接通过Booster读取。
print('Loading model to predict...')
# load model to predict
bst = lgb.Booster(model_file='model.txt')
# can only predict with the best iteration (or the saving iteration)
y_pred = bst.predict(X_test)
# eval with loaded model
print("The rmse of loaded model's prediction is:", mean_squared_error(y_test, y_pred) ** 0.5)
print('Dumping and loading model with pickle...')
# dump model with pickle
with open('model.pkl', 'wb') as fout:
pickle.dump(gbm, fout)
# load model with pickle to predict
with open('model.pkl', 'rb') as fin:
pkl_bst = pickle.load(fin)
# can predict with any iteration when loaded in pickle way
y_pred = pkl_bst.predict(X_test, num_iteration=7)
# eval with loaded model
print("The rmse of pickled model's prediction is:", mean_squared_error(y_test, y_pred) ** 0.5)
继续训练
LigGBM支持继续训练,我们直接在init_model='model.txt'这里指定模型。
gbm = lgb.train(params,
lgb_train,
num_boost_round=10,
init_model='model.txt',
valid_sets=lgb_eval)
print('Finished 10 - 20 rounds with model file...')
模型调参
LigGBM人工调参比机器调参要更加好,已有的调参例如网格、随机调参、贝叶斯优化等方法是不知道我们模型的状态,人工是知道模型状态,所以人工调参能得到更加好的结果。
怎么调精度更优呢?
人工调参还是需要交叉验证的。可以自己写函数,也可以直接用lgb自带的cv。
data = lgb.cv(params, d_train, num_boost_round=350, nfold=5, metrics='auc')
cv输出的是dataframe,里面的数据是验证集的auc和验证集具体方差。调参是追求方差较小的一组超参数。
GridSearchCV
不想人工调参就可以用网格。n_jobs是线程个数(skLearn线程设置),cv = 5是fold个数。在数据集比较小的情况下,GridSearchCV效果还是不错的。但是GridSearchCV训练周期比较长,下面的Param有4个参数,每个参数3个值,也就是有3的4次方81个超参数组合,每个组合训练5次,共计要训练405次。
lg = lgb.LGBMClassifier(silent=False)
param_dist = {"max_depth": [4,5, 7],
"learning_rate" : [0.01,0.05,0.1],
"num_leaves": [300,900,1200],
"n_estimators": [50, 100, 150]
}
grid_search = GridSearchCV(lg, n_jobs=-1, param_grid=param_dist, cv = 5, scoring="roc_auc", verbose=5)
grid_search.fit(train,y_train)
grid_search.best_estimator_, grid_search.best_score_
贝叶斯优化
贝叶斯优化非常简单,我们只需要写一个函数lgb_eval,这个函数的作用就是在传入这些超参数数据,返回模型精度。然后把这个函数传入到BayesianOptimization,max_depth、learning_rate等为贝叶斯搜索范围。maximize最大化验证集的AUC,init_points=5是5次初始化,n_iter=50表示在5次初始化以后再搜索50次超参数组合。
贝叶斯优化的搜索方法就是对超参数和标签建模的过程,就是我们把模型当作黑盒,优化这些超参数的取值和标签的关系,相当于我们把超参数和标签再构建一个模型,用已知先验知识取值,例如在5次初始化的情况下,我们在已知这5次超参数取值的情况下标签的精度,我们去预估下一次超参数的取值范围,判断下一次超参数的取值范围可能取得更优的精度。
import warnings
import time
warnings.filterwarnings("ignore")
from bayes_opt import BayesianOptimization
def lgb_eval(max_depth, learning_rate, num_leaves, n_estimators):
params = {
"metric" : 'auc'
}
params['max_depth'] = int(max(max_depth, 1))
params['learning_rate'] = np.clip(0, 1, learning_rate)
params['num_leaves'] = int(max(num_leaves, 1))
params['n_estimators'] = int(max(n_estimators, 1))
cv_result = lgb.cv(params, d_train, nfold=5, seed=0, verbose_eval =200,stratified=False)
return 1.0 * np.array(cv_result['auc-mean']).max()
lgbBO = BayesianOptimization(lgb_eval, {'max_depth': (4, 8),
'learning_rate': (0.05, 0.2),
'num_leaves' : (20,1500),
'n_estimators': (5, 200)}, random_state=0)
lgbBO.maximize(init_points=5, n_iter=50,acq='ei')
print(lgbBO.max)
更多精彩内容(原理解析、模型部署等)长按识别参见课程:

打比赛就像打游戏一样需要升级打怪,途中八十一难都需要小伙伴配合和大佬们的帮助,我们的课程也专门为大家所遇到的各种困难做好充分答疑准备。


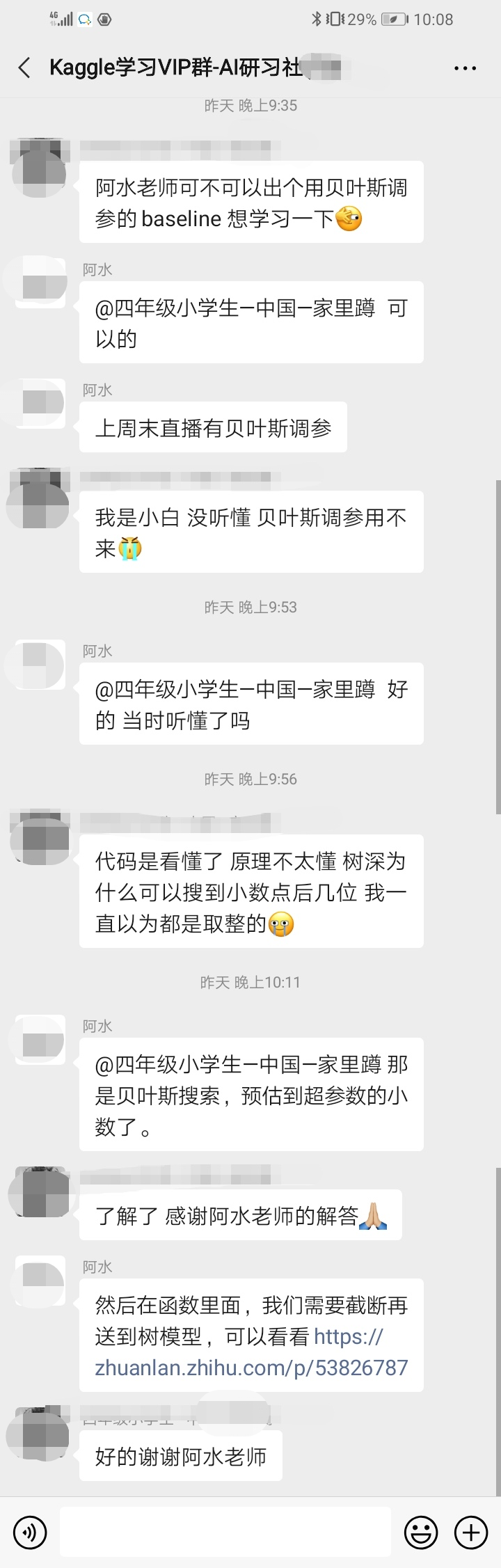


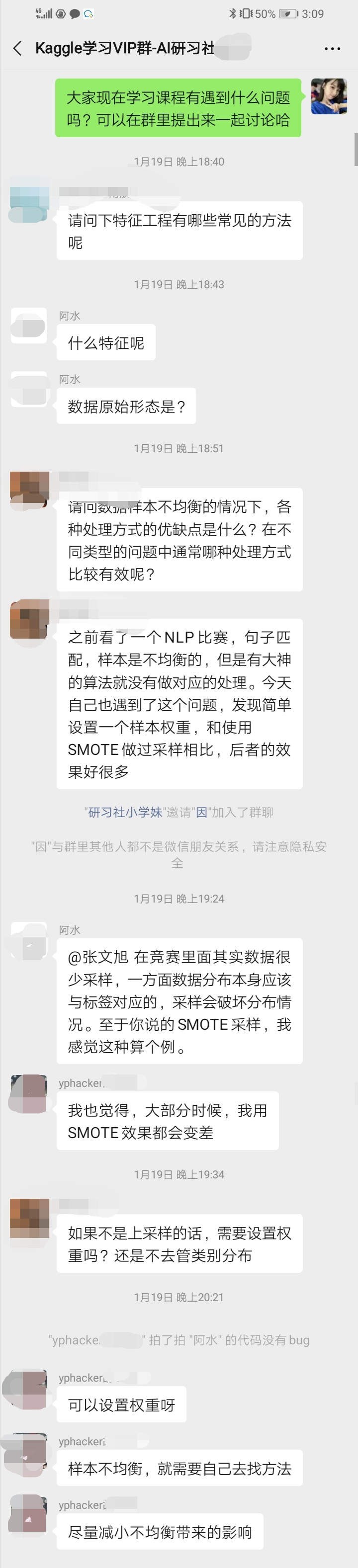
购买后可以和老师一对一请教,也可以和其他同学针对比赛相关问题进行畅通无阻的交流。
https://mooc.yanxishe.com/course/895
我们承诺学完本课程您可以得到:
kaggle比赛常见思路和常用库的方法和案例 竞赛算法原始论文的相关思路借鉴 竞赛常见的模型调参,模型融合思路进阶 12+场实战项目相关代码逐步讲解 优秀同学老师将带同学在kaggle平台上拿银牌一次机会,并且退还全部学费
我们不承诺
没有Python基础也能学 学完后能够立刻进入大厂
考虑到深度学习入门后对学习资料的需求,我们现特给予以下优惠:
1.课程购买后AI研习社现有课程免费挑选,大厂专家陪你一起学习人工智能




2.凡是被评为优秀学员,老师将带着参与kaggle比赛并最高获取银牌一次,为你的履历再填光彩
有更多疑问可添加慕慕微信咨询

长按识别二维码(↓)观看更多精彩课程
