【Viewer】突破2nm的壁垒
编者按:自从1990年代末期的220/180nm节点开始,业界就使用铜作为芯片内接连的材料。但是随着芯片制程的逐渐缩小,芯片内通道的尺寸也随之减小。通道的电阻如果变得过大,会造成发热,并消耗大量能量。当芯片制程达到3nm节点时,传统以铜为材料的双重大马士革布线工艺将无法胜任。目前,潜在的解决方案有混合金属化工艺、半大马士革工艺、超通道、石墨烯材料等,但是这些工艺目前都还不够成熟。对布线工艺感兴趣的小伙伴们可以阅读这篇文章,了解更多。
以下为原文:
Breaking The 2nm Barrier
Chipmakers continue to make advancements with transistor technologies at the latest process nodes, but the interconnects within these structures are struggling to keep pace.
The chip industry is working on several technologies to solve the interconnect bottleneck, but many of those solutions are still in R&D and may not appear for some time — possibly not until 2nm, which is expected to roll out sometime in 2023/2024. Moreover, the solutions require new and expensive processes with different materials.
Until then, the industry will continue to deal with several issues in advanced chips, which consists of three parts — the transistor, contacts, and interconnects. The transistor resides on the bottom of the structure and serves as a switch. The interconnects, which reside on the top of the transistor, consist of tiny copper wiring schemes that transfer electrical signals from one transistor to another. Today’s advanced chips consist of 10 to 15 layers, each incorporating a complex copper wiring scheme and connected using tiny copper vias.
In addition, the transistor structure and interconnects are connected by a layer called the middle-of-line (MOL). The MOL layer consists of a series of tiny contact structures.
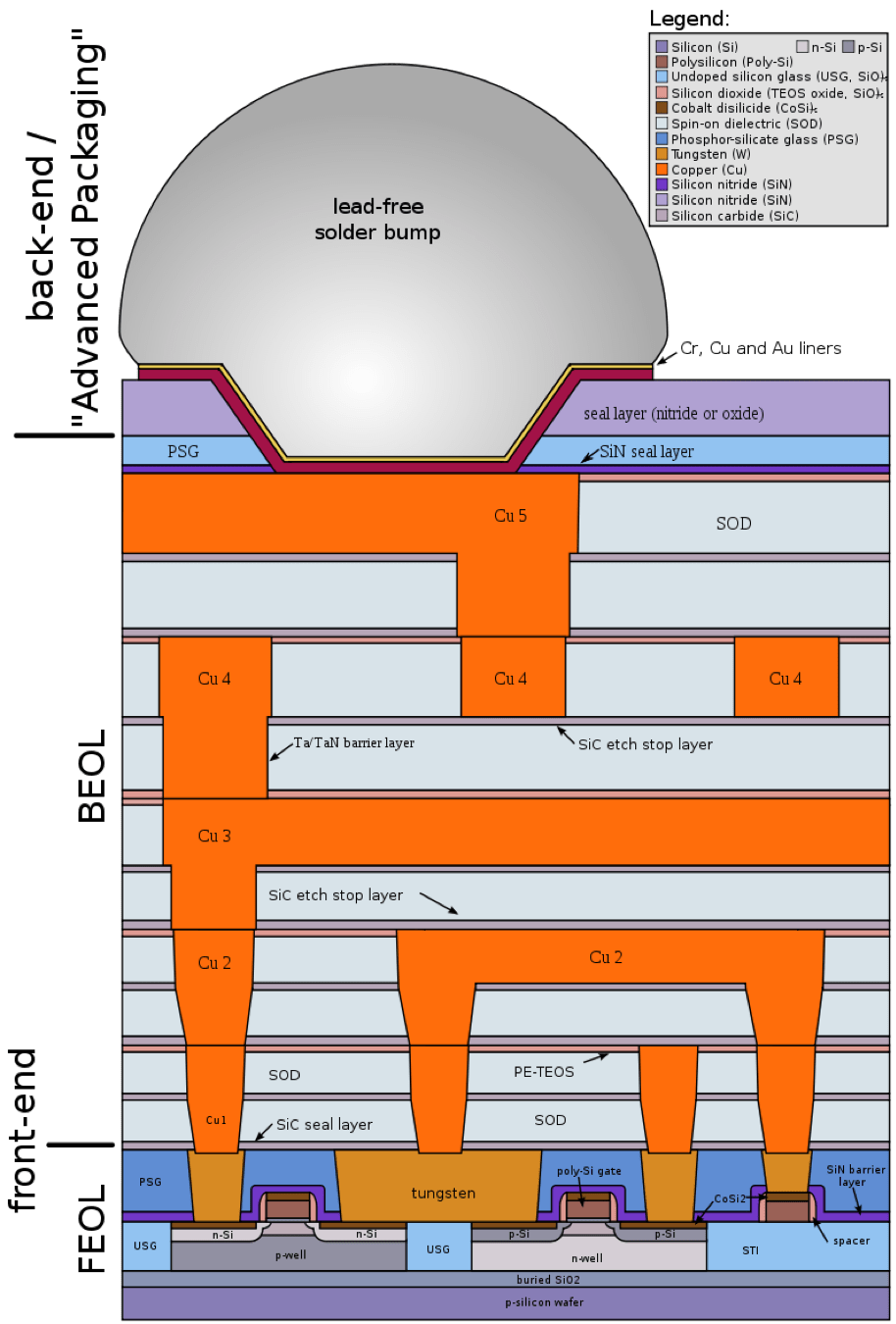
Fig. 1: BEOL (copper interconnect layers) and FEOL (transistor level) Source: Wikipedia
The problems with advanced chips began piling up at 20nm and 16nm/14nm less than a decade ago, when the copper interconnects became more compact within the transistors, causing an unwanted resistance-capacitance (RC) delay in chips. Put simply, it became more difficult to move current through the tiny wires. Over time, chipmakers have been able to scale the transistor and interconnects down to the latest nodes, namely 7nm/5nm. But at each node, the complicated interconnect schemes are contributing to a larger percentage of the delay in chips.
“As transistors shrink in size, so must the metal lines that connect them within the overall high-rise architecture of the multi-level interconnect stack,” explained Nerissa Draeger, director of university engagements at Lam Research. “With successive generations, these local interconnects have become both narrower and closer together to the point where the incumbent copper interconnects are facing significant challenges to further scaling. For example, further decreases to the line width or height would dramatically increase the electrical resistance of the line.”
Many of these issues can be traced back to how the copper interconnects are manufactured. For this, chipmakers utilize the so-called copper dual damascene process in the fab. Developed by IBM in the late 1990s, chipmakers inserted the dual damascene process starting at 220nm/180nm nearly 25 years ago, and have extended the technology since then.
Chipmakers pushed the technology to more advanced nodes with plans to extend it to 3nm. Beyond 3nm, though, the RC delay issues likely will become more problematic, so the industry may need a new solution.
It’s critical to find a next-generation interconnect technology. The interconnects go hand-in-hand with the transistor, and they are essential for chip scaling. But if the industry is unable to develop a next-generation, cost-effective interconnect scheme beyond 2nm, chip scaling as we know it today could grind to a halt.
Currently in R&D are an assortment of new interconnect technologies at 2nm and beyond. Among them:
Hybrid metallization or pre-fill. This combines different damascene processes with new materials to enable smaller interconnects with less delay.
Semi-damascene. A more radical approach using subtractive etch, enabling tiny interconnects.
Supervias, graphene interconnects and other technologies. These are all in R&D as the industry continues to look for a replacement metal for copper.
Each of the proposed R&D technologies faces challenges. Consequently, the industry is hedging its bets and developing alternative approaches to develop new system-level designs. Advanced packaging is one of those approaches, and it is expected to continue gaining traction regardless of what happens with scaling.
From aluminum to copper
In the chip-manufacturing process, transistors are manufactured on a wafer in a fab. This process is conducted in the front-end-of-the-line (FEOL) in the fab. Then, the interconnects and MOL layers are formed in a separate fab facility called the backend-of-the-line (BEOL).
Until the 1990s, chips incorporated interconnects based on aluminum materials. But when leading-edge chips approached 250nm in the late 1990s, aluminum was unable to withstand the higher current densities in devices.
So starting at 220nm/180nm in the late 1990s, chipmakers migrated from aluminum to copper. Copper interconnects conduct electricity with 40% less resistance than aluminum, which helps boost the performance in chips, according to IBM.
In 1997, IBM announced the world’s first copper interconnect process based on a 220nm technology. The process, called dual damascene, became the standard way to manufacture copper interconnects in chips, and is still used today.
Initially, this process enabled chips with six levels of interconnects. At the time, the metal pitch for a 180nm device was 440nm to 500nm, according to WikiChip. In comparison, at the 5nm node, chips consist of 10 to 15 levels of interconnects with a metal pitch of 36nm. The metal pitch refers to the minimum center-to-center distance between interconnect lines, according to TEL.
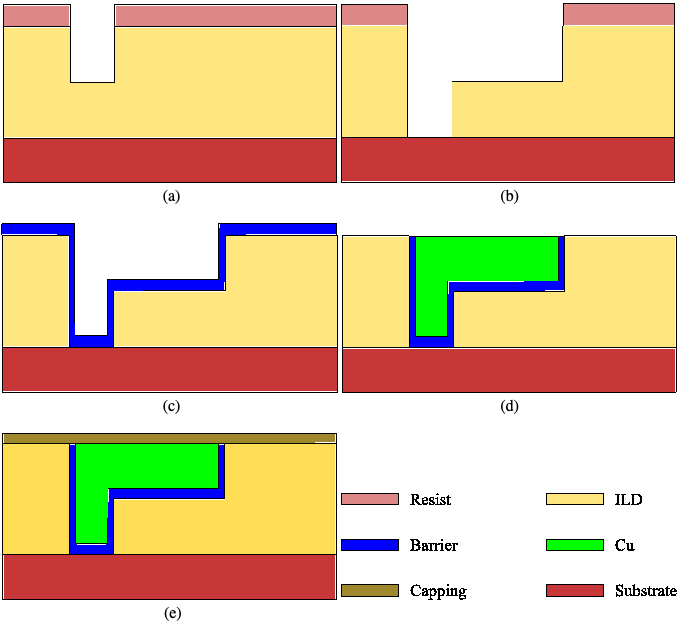
Fig. 2: Dual-damascene fabrication process; (a) Via patterning; (b) Via and trench patterning; (c) Barrier layer deposition and Cu seed deposition; (d) Cu electroplating and excess removal by chemical mechanical polishing; (e) Capping layer deposition. Source: TU Wien/Institute for Microelectronics
In the dual damascene process, a low-k dielectric material is first deposited on the surface of the device. Based on a carbon-doped oxide material, low-k films are used to insulate one part of the device from another.
The next step is to pattern tiny vias and trenches in the dielectric material. The vias/trenches are becoming smaller at each node. So in today’s advanced chips, chipmakers are using extreme ultraviolet lithography (EUV) to pattern the vias.
At future nodes, the vias will require EUV with multiple patterning. “The challenges with EUV multiple patterning are very similar to those encountered during the ArFi (193nm immersion) implementation,” said Doug Guerrero, senior technologist at Brewer Science. “If ArFi or EUV are being used, machine-to-machine overlay will become critical. From the materials point of view, multiple patterning always includes the incorporation of planarization layers. The planarization materials are also referred to as gap fill materials. They must fill and planarize very narrow trenches with high aspect ratios.”
Following that step, the patterned structure is etched, forming a via and trench. Then, using physical vapor deposition (PVD), a thin barrier material based on tantalum nitride (TaN) is deposited inside the trench. Then, a tantalum (Ta) liner material is deposited over the TaN barrier. And finally, the via/trench structure is filled with copper using electrochemical deposition (ECD). The process is repeated multiple times at each layer, creating a copper wiring scheme.
This process worked without any issues until 20nm, when the copper resistivity increased exponentially in the interconnects, causing delays in chips. So starting at 22nm and/or 16nm/14nm, chipmakers began to make some major changes. On the interconnect side, many replaced Ta with cobalt for the liner, which helps lower the resistance in the interconnects.
Also at those nodes, chipmakers moved from traditional planar transistors to next-generation finFETs, which provided more performance at lower power.
Then, at 10nm, Intel took another step to reduce the resistance in chips. Intel’s 10nm process features 13 metal layers. Intel’s first two local interconnect layers, called metal 0 (M0) and metal 1 (M1), incorporate cobalt as the conducting metal, not copper. The remaining layers use traditional copper metal.
Other chipmakers stuck with copper at M0 and M1. At 10nm/7nm, though, all chipmakers moved from tungsten to cobalt materials for the tiny contacts in the MOL, which also reduces line resistance.
Today, leading-edge chipmakers have extended finFETs and copper interconnects to 5nm. To be sure, there is demand for chips at advanced nodes, enabling new and faster systems.
“There’s no question that being able to compute 10X faster than now will be commercially useful and competitively required, even for non-technical markets. There’s virtually no end in sight for the demand for more computing power,” said Aki Fujimura, chief executive of D2S.
Still, there are some troubling signs on the horizon. The benefits of shrinking the transistor are diminishing at each node, and the RC delay issues remain problematic.
“At the 7nm and/or 5nm foundry nodes, copper interconnects will likely consist of a tantalum nitride barrier and cobalt as the liner,” said Griselda Bonilla, senior manager of advanced BEOL interconnect technology research at IBM. “As dimensions shrink, the line resistance increases disproportionately, accounting for a higher fraction of the total delay. The resistance increase is driven by several factors, including reduced conductor cross-section, further-reduced volume fraction of copper due to non-scaled high-resistivity barriers and liner layers, and added resistivity due to lossy electron scattering at surfaces and grain boundaries.”
Moving to 3nm and beyond
That hasn’t stopped the industry from marching to the next nodes, though. Today, leading-edge foundries are shipping 5nm, with 3nm/2nm and beyond in R&D.
At 3nm, Samsung plans to move to a next-generation transistor called gate-all-around FETs. TSMC plans to extend the finFET to 3nm, but will move to gate-all-around at 2nm.
FinFETs approach their practical limit when the fin width reaches 5nm, which equates to the 3nm node. Gate-all-around FETs hold the promise of better performance, lower power, and lower leakage than finFETs, but they are harder and more expensive to make.
At 3nm, the metal pitches will range from 24nm to 21nm, according to Imec. And at 3nm, chipmakers will continue to extend and use the traditional copper dual damascene process with the existing materials, meaning RC delay will remain problematic in chips.
“As we move to the 3nm node, we will see continued BEOL scaling with critical Mx pitches <25nm using multi-patterning EUV,” said Andrew Cross, process control solutions director at KLA. “This continued pitch scaling will continue to impact line and via resistance, as the thickness of barrier material scales slower than the pitch.”
In R&D, the industry continues to explore various new technologies to help solve these and other problems at 3nm and beyond. “At around the 24nm metal pitch, we expect to start seeing a few enabling design and material inflections,” said Scott Hoover, senior director of strategic product marketing at Onto Innovation. “This includes fully self-aligned vias, buried power rails, supervia integration schemes, and a broader adoption of ruthenium liners.”
Developed in the BEOL, power rails are tiny structures designed to handle the power delivery network functions in transistors. Imec is developing a next-generation buried power rail (BPR) technology. Developed in the FEOL, BPRs are buried in the transistor to help free up routing resources for the interconnects.
In addition, the industry has also been exploring the use of ruthenium materials for the liner in the interconnects. “Ruthenium is known for having improved copper wettability and gap fill,” IBM’s Bonilla said. “While ruthenium has superior copper wettability, it suffers from other disadvantages, such as lower electromigration lifetimes and unit process challenges like chemical mechanical polishing. This has curtailed the use of ruthenium liners in the industry.”
Other new and more promising interconnect solutions on the horizon, but they may not appear until 2nm in 2023/2024. Based on Imec’s roadmap, the industry could migrate from today’s dual damascene processes to a next-generation technology, called hybrid metallization, at 2nm. That will be followed by semi-damascene and other schemes in the future.
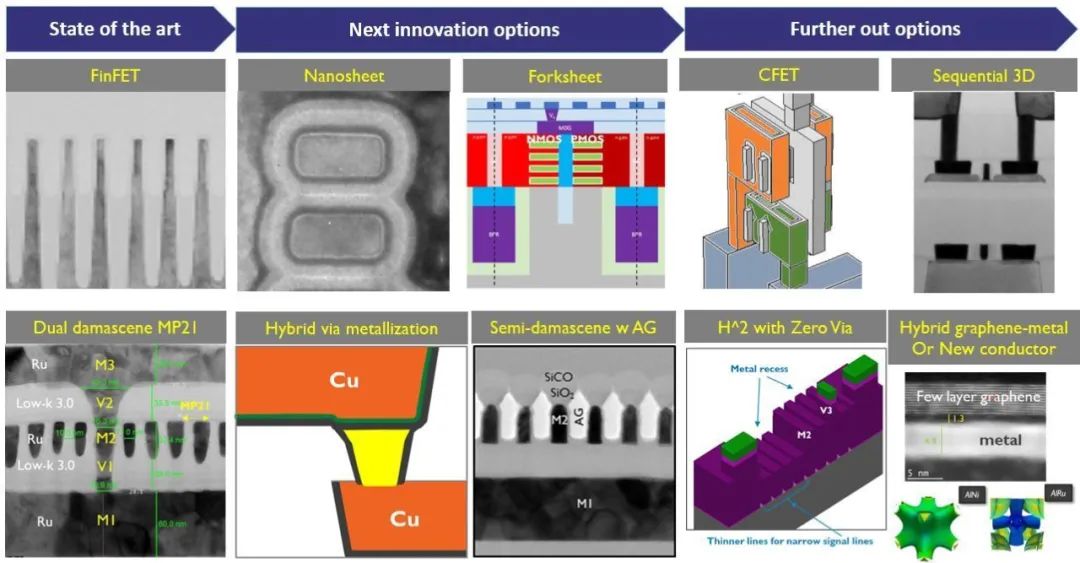
Fig. 3: Roadmap for transistors (top image) and interconnect technologies (bottom image). Source: Imec
All of this depends on several factors, namely the ability to develop new processes, materials and tools. Cost is also critical.
“No one thought the current scheme could be extended so many generations. It was done through incremental improvements and a ton of hard work,” said David Fried, vice president of computational products at Lam Research. “The future holds more significant changes, but I predict they will be introduced in a steady stream of more evolutionary improvements. Clearly, reliability has presented some major barriers to scaling the interlayer dielectric k values much lower, but this has continued to push down. As fill materials change, the requirements on liners (or requirements to even have liners/barriers) will also change. The processes associated with these materials will present advantages and disadvantages for different integration schemes, like dual-damascene, single-damascene, fully-self-aligned integration, and even subtractive metallization. In a few generations, the BEOL could look radically different than it does today, but I would expect this to actually be the product of many of these more incremental changes all happening in concert.”
Nonetheless, for the tightest layers, today’s copper damascene processes will extend to a certain point. “Dual damascene is always a question of pitch. As long as we are above 26nm or 24nm pitch, this is still pretty much the territory of copper and cobalt,” said Zsolt Tokei, program director for nano-interconnects at Imec. “The tipping point is when you go below 20nm pitch. Below 20nm pitch, there are many concerns. It’s not only resistance, but also reliability concerns, especially with copper.”
So roughly at this pitch, which equates to the 2nm node, the industry hopes to make the migration to a technology called hybrid metallization. Some call it a pre-fill process. This technology may get inserted in the tightest layers, but the less critical layers would continue to use the traditional copper processes.
In a basic hybrid metallization flow, you deposit dielectric materials on a substrate. Then, you form tiny copper vias and trenches using the traditional damascene process. Then, you repeat the process, and form tiny vias and trenches.
But instead of using a dual damascene process, “the next step involves a selective deposition of via metal. The empty vias are filled with a metal conductor without using a liner,” Tokei explained. “Molybdenum, ruthenium or tungsten are among the metals that could be used to fill the tiny vias. Finally, you finish with conventional copper metallization, which can be regarded as a single damascene copper metallization.”
Single damascene isn’t a new process in the semiconductor world. “The dual damascene process is a smarter and more cost-effective process flow than the single damascene process. As technology scales, the challenge for dual damascene is defect-free copper metallization in the taller and more constricted line and via combined openings,” said Takeshi Nogami, a principal member of the research staff at IBM. “Single damascene decouples those two patterns for metallization, making it easier to shrink width and pitch dimensions, and raise line aspect ratios, to mitigate the rise in resistance.”
All told, hybrid metallization uses two different metals in the interconnects. “For 2nm, this would make a lot of sense, at least for one layer,” Imec’s Tokei said. “The via resistance compared to a dual damascene is lower. Your reliability will improve. And at the same time, we can preserve the low resistivity of copper in the line.”
Hybrid metallization presents some hurdles, though. There are several different and difficult deposition techniques to enable the gap fill process. “The challenge is to achieve good via fill uniformity without selectivity loss,” said M.H. Lee, a researcher at TSMC, in a paper at IEDM. “In addition, the via sidewall is barrierless, and the potential interaction of via material and the underlayer metals might lead to reliability concerns.”
What is semi-damascene?
Hybrid metallization may get inserted at 2nm, if the industry can solve these problems. But the industry may need another solution way beyond 2nm, if chip scaling is to continue.
Beyond 2nm, the next big step is what many call a semi-damascene process, which is a more radical technology targeted for the tightest metal pitches. In R&D, the industry is exploring semi-damascene for several reasons.
“Within the dual damascene structure, the volume of the line is a limiting factor for copper grain growth,” said Robert Clark, senior member of the technical staff at TEL. “If instead the metal lines were formed by depositing a metal layer, which can be annealed, and then forming the lines by etching, then the grain size could be increased. But for copper, that kind of process is very difficult to realize. A metal like ruthenium is much easier to handle in that kind of process, so it could potentially enable what people are referring to as semi-damascene processing.”
The starting point for semi-damascene is sub-20nm pitches. “We are targeting semi-damascene for 18nm pitch and below. So maybe that’s like in four or five years from now,” Imec’s Tokei said. “This is disruptive for a logic fab. A fab is set up for a copper metallization and dual damascene. Hybrid metallization almost naturally falls into that flow. You need some new capabilities for the via pre-fill itself. But for the rest, you can re-use everything from the fab.”
Semi-damascene requires different process flows with new tools. In simple terms, semi-damascene enables tiny vias with air gaps, which reduces RC delays in chips.
The technology relies on metal patterning using a substrative etch process. Substrative etch isn’t new, and was used for the older aluminum interconnect processes. But there are several challenges to implement this technology at beyond 2nm.
“Semi-damascene processing starts with the patterning of a via opening and etching it into a dielectric film. The via is then filled with metal and overfilled, meaning that the metal deposition continues until a layer of metal is formed over the dielectric. The metal is then masked and etched in order to form metal lines,” Tokei said in recent blog.
In the lab, Imec devised a 12-metal-layer device based on a 64-bit Arm CPU. The device had two levels of metal interconnects using ruthenium materials. Air gaps were formed between the metal lines.
“Air gap shows the potential to improve performance by 10%, while reducing the power consumption by more than 5%,” Tokei said. “The use of high-aspect-ratio wires can reduce the IR drop in the power network by 10% to improve reliability.”
Semi-damascene is far from being ready in production, however. “There are many potential concerns with a semi-damascene scheme, such as alignment, metal etch, LER, leakage, chip package interaction, sealing ring compatibility, plasma damage and routability,” Tokei said in a recent paper.
Conclusion
Other interconnect technologies are in R&D, such as supervias, hybrid metal-graphene interconnects, as well as replacements for copper.
To be sure, though, the industry would prefer to extend copper dual damascene as long as possible, because the next-generation technologies face several challenges.
At some point, the industry may need a next-generation interconnect technology. Chipmakers may find a solution. But if they can’t, traditional chip scaling may be on its last legs, forcing the industry to look for alternative solutions to enable advanced chips.
That’s already happening. Momentum is already building for advanced packaging, an alternative approach that enables the development of system-level designs with the possibility of more customization.
For now, though, the industry is working on both traditional chip scaling approaches, as well as advanced packaging to develop new system-level designs. Both approaches are viable, at least for the foreseeable future.
看完有什么感想?
请留言参与讨论!
