如今,每个AI用例(无论是自动驾驶汽车还是工业分类机)都可以解决特定问题,这使其具有独特性。同样,用于半导体制造和测试的基于AI的系统旨在解决制造厂或封装厂中的特定问题。问题在于,随着条件随着时间的推移而变化,使ML算法(这是AI系统的核心)保持最新状态。机器学习算法和模型需要适应设备以及正在制造和包装的设备的其他变化。“我们可能必须建立持续的培训和监控过程,” Advantest America公司技术和战略副总裁Keith Schaub说。“流程漂移,这意味着数据漂移,这意味着您需要持续监控数据并在流程漂移时触发重新培训。我们知道该怎么做。面临的挑战是要知道要训练多少知识以及多久要进行一次再训练。在我触发再培训之前需要多少漂移?”当使用AI / ML系统创建AI / ML芯片时,整个过程变得非常复杂,并且随着机器用于训练其他机器,整个过程将变得更加复杂。AI中的度量是以概率和分布而不是固定数量报告的,并且在包括包装在内的多个过程步骤中的任何固有变化都可以是增量的和累加的。
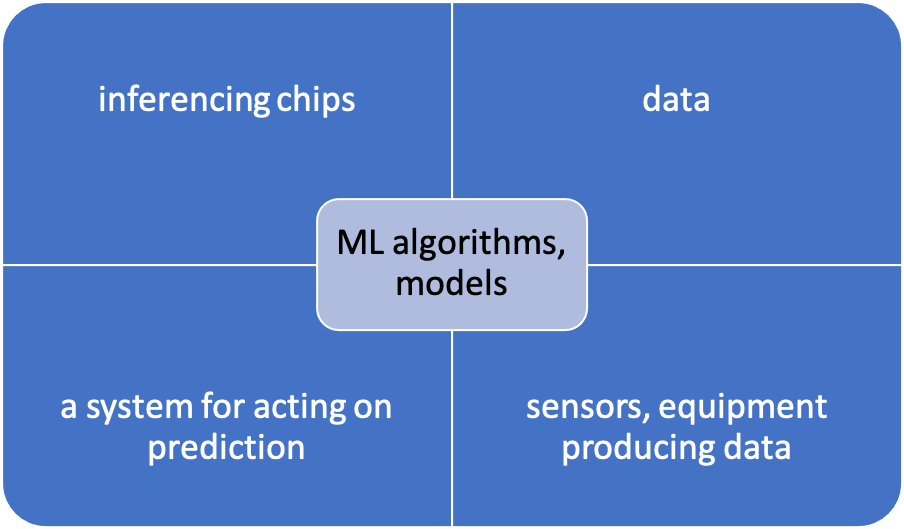
确实存在检查ML算法和AI系统的基本技术,并且有许多方法可以验证ML算法对于制造和测试流程的有效性。乙UT斯达康甚至与那些成熟的技术,成功的AI实现必须考虑到会发生什么随着时间的推移,如在工厂或组装房子的变化。PDF Solutions AI解决方案副总裁Jeff David说:“当您在fab中测试模型时,您想做一个真实的生产仿真,这是对时间的认可。” “我们有多种方法可以在晶圆厂对其进行测试。例如,您有盲目的保持数据集。基本上,这意味着您拥有一个与用于训练或选择模型的数据完全独立的验证数据集。该数据集在训练阶段根本不会公开。您可以通过多种不同方式进行验证。最著名的方法之一是k倍交叉验证,其中k代表任意数量的整数。”因此,可能会有8倍或10倍交叉验证。10倍交叉验证意味着将数据集分成10个块。大卫说:“比方说,您将完全随机的或以某种方式跨越您要选择的地块边界进行分层的数据集分解了。” “您不想对来自同一批次的数据进行训练和测试。那将是作弊,因为在现实世界中,您永远不会遇到可以做到这一点的情况。因此,您的想法是将数据集分成10%的块。块A是数据的10%,当然可以跨批次边界随机选择。然后,您将有10%的块构成整个数据集。十倍交叉验证意味着您将基本上遍历所有这10个块,训练90%的数据,然后在其他步骤上进行测试。剩下的10%就完成了。然后旋转到下一个块,下一个块和下一个块。你这样做十次。您训练并测试了10次。这样一来,您将对该数据集有很好的感觉,或者您的模型对所有这些不同数据的鲁棒性。最大的问题是晶圆厂的条件在物理上和时间上都在变化。工具中的传感器会漂移,并且设备会不断重新校准。另外,许多算法本身都会更新,而并非晶圆厂或装配车间中的所有设备都是相同的。需要在这些模型上叠加模拟以合并所有这些更改,并且在模型中建立这种精度并非易事。David说:“从您的工具中获得的数据将会发生漂移和变化。” 随着时间的流逝,工具设置可能会更改。操作员可能会对测试仪进行更改,从而影响从传感器收集的数据。“这有点逼真的模拟方法,基本上,当您在fab中测试模型时,您想要做的是能够时间识别的真实生产模拟。”处理测试算法中添加的时间成分的一种方法是使用您已有的数据(例如一年的数据)将时间段分成多个块,以时间段模拟训练,然后将其与基本事实进行比较。“在不断地训练和测试模型时,您基本上会在时间上移动,就像在真实的生产模拟中一样。然后您会看到它如何维持下去,因为在这种情况下,您拥有基本事实。”戴维说。过去,这类问题可以通过在制造过程中增加利润来解决。但是,特别是在高级节点以及在某些尖端节点上开发了某些芯片的异构封装中,公差越来越严格,因此需要精度。增加太多的余量,会损害可靠性。添加得太少,产量可能会受到影响。尽管AI / ML可以帮助识别其中的一些问题,但必须在许多可动部件的背景下处理这些系统生成的数据。因此,现在,这些测量需要合并跨不同时间段的模拟,而不是进行即时快照测量。一方面,所有这些都可以分解为可管理的部分。“行业使用培训数据和验证数据集,” Advantest America技术和战略副总裁Keith Schaub说。“验证数据集用于完整性检查ML是否正常工作。”图1:一个基于晶圆厂的基本AI系统。机器学习是一种从数据中学习以创建模型的算法。一旦训练和部署,该模型就可以做出预测。AI系统围绕它构建。
在另一个层面上,此过程中现在存在许多未知数,因此,有一个评估所有这些变化所依据的备份策略也没有什么坏处。在这方面,为制造和测试设备增加更多的灵敏度可以有很大帮助。“首先,在计量学中,第一件事就是您需要具有敏感性,”郝说。“您的工具必须对过程中发生的尺寸变化具有敏感性。没有任何敏感性,机器学习或任何其他技术都无法为您提供帮助。其次,由于灵敏度低和我们要测量的设备的复杂性,使用基于物理的经典建模技术已不再足够。那就是机器学习发挥作用的地方。另一方面,机器学习本身可能不是唯一的解决方案。物理仍然很重要。”
使用AI / ML,事情变得非常混乱,因为AI / ML技术在AI / ML芯片的制造中越来越多地被使用。CyberOptics研发副总裁Tim Skunes表示:“为了测试晶圆厂中的芯片,采用了检测和计量流程来进行缺陷检测。” “在制造过程中,可以以与其他芯片类似的方式检查AI芯片。”但是这些芯片的外观和性能也与其他芯片完全不同。Synopsys的硅生命周期管理市场总监Randy Fish说:“在某些方面,人工智能芯片还只是一个非常复杂的SoC 。但是,从历史上看,这些架构或微架构与我们在SoC中所使用的架构根本不同。”一方面,人工智能通过训练和推理而分叉。“这两个环境的约束条件截然不同。但是就如何测试而言,它来自晶圆厂,您可以从晶圆厂获得一些信息,一些测试信息以及一些晶圆测试材料。然后您进入晶圆级测试,因此您在OSAT上,他们正在执行逻辑BiST或内存BiST或DFT,” Fish说。“我们使用许多AI芯片。对于我们来说,在很多情况下,这是另一个测试挑战。这是非常分层的。一个有趣的方面是,这些芯片中有很多都是阵列结构。因此,您可以通过多种方式来解决测试问题。”在AI芯片中,阵列结构用于创建网络。但是,AI芯片不会生成汇编代码或映射到二进制文件(这在标准处理器中会发生),而是映射到网络。他解释说:“您经历了培训阶段,它会创建一个有权重的网络。” “然后,将这些映射到没有个性的芯片上,直到您提供此网络为止。这是第一种编程。然后,您就可以在该网络上传输数据,并进行推理。这是从中推断出的东西。我们没有在那个级别上进行测试,但是,这类似于在电话上使用应用处理器时,我们没有测试所有这些功能。结构测试和系统级测试本身就是一个完整的领域。”AI芯片可以在测试仪上花费更多的时间,而维修是其中的一部分。“我们参与其中的一些是非常大的,受标线限制的设计,尤其是在培训方面,” Fish说。“测试时间很敏感,因为他们将长期担任测试员。而且也有维修。在这些更大的阵列结构中,您不仅在进行内存修复。实际上,您可以修理处理器,因为在测试期间您可能会忽略处理元素。您可以单独测试处理单元,如果一个单元坏了,就可以将其映射出来。因此,在这一点上,还有更多的宏观测试和维修。”然后进行此类更改可能需要返回并检查软件编译器。Synopsys的产品销售高级总监Johannes Stahl说:“有了这种冗余,或者省去了处理器并重新映射,编译器当然需要了解。” “因此,需要再次通过芯片测试此编译器功能。”放眼来看,芯片正在发生变化,芯片上和测试设备中的算法也在发生变化,利用AI的制造和包装设备传感器也在不断变化。因此,除了全局地看待所有这些问题之外,还必须分别解决不同的问题。Schaub说:“一种支持AI的芯片构建在CPU和/或GPU之上。” 因此,在晶体管级别的测试基本上保持不变。一旦存在嵌入式AI算法(其中算法可能是“黑匣子”),挑战就变成了挑战。我们需要提出一种可靠的方法来确保黑匣子正常运行。”这就需要一种评估这些测试准确性的方法,并且此处将应用机器学习。“并非所有的机器学习系统都是平等的,” CyberOptics的Skunes说。“您希望您的机器学习算法有效。您想迅速获得良好的性能。例如,机器学习算法(例如AI2)可通过显示良好/无缺陷的图像或缺陷的图像进行教学,从而可以改善流程和提高产量。操作员可以快速进行授课,然后进行监控,从结果中学习,并根据需要更新培训集来进行改进和调整。我们设计机器学习算法时要以不逃避的目标为偏见,这样就不会有不良产品出厂。”晶圆厂的最后一步是确保AI芯片或系统能够按预期运行,这是系统级测试的工作。“从晶圆厂到晶圆再到封装(FT),测试仍将在晶体管级别进行,因此在那里没有太大变化。Schaub说:“将在系统级测试中,使软件装有AI算法,一切都会变得有趣起来。” “只要AI / ML是静态的,这就是事实所在,那么在短期内这应该不是什么大问题。一旦我们开始部署自学系统,事情就会变得有趣。借助自我学习系统,我们很可能会看到并行部署的特定AI校准和诊断程序,它们可以持续监视和检查AI本身。”PDF的David同意。“您应该不断地-不断地验证您的系统。您可以确信它可以处理某些过去的数据。但是,展望未来,我是否真的有足够的信心要将产品发布到这个东西上,并相信该系统可以正常工作?” 答案通常是永远不会完全100%信任。
尽管在晶圆厂中需要了解所有这些信息,但也需要将其反馈到设计过程中,在此处可以对其进行仿真并纳入测试计划的设计中。在这方面需要做很多工作。AI软件尚未准备好在AI系统的早期设计阶段进行仿真。Synopsys的Stahl说:“在过去的5至10年中,我们拥有CPU和GPU的规范体系结构以及存储器和外围设备。” “整个设计界都知道如何做到这一点,他们拥有可以在这些可用芯片上运行的软件,例如Android或iOS,或者需要在这些硅芯片上运行的任何软件。因此,问题主要是在硬件上实际启动软件,并尝试在硅片上进行此操作,以确保在现场稍后不会出现意外情况–或稍后在启动后(即制造后)毫不奇怪。业界了解过去10年。在过去的5年中,我们引入了非常快速的仿真技术,以允许此软件在芯片发布之前启动。因此,所有这些操作都是在普通的CPU或基于处理器的芯片上完成的。”AI有所不同,使用AI软件的编译器可能会出现问题。斯塔尔说:“人工智能将这个问题整体上提高了,这就是原因。” “在AI中,该软件不作为标准软件存在。这都是特定于应用程序的。这些软件不仅不存在于每种AI体系结构中,而且这些公司还必须开发新的软件堆栈,即采用任何AI应用程序并可以将其编译为在其目标体系结构上运行的编译器。而且,由于所有这些编译器都是新的,因此它们可能有错误且效率低下。所有这些AI公司都创建了自己的芯片的软件模型,然后开发了基于编译器的基于软件堆栈的软件模型,但最后还不够。因此,当我们几年前与第一家AI公司合作时,我们的目标是什么?他们需要在实际硬件上运行所有这些不同版本的软件编译器,并弄清楚其工作原理。然后,在几代客户中,我们只有一位实际与仿真合作的客户。在一年的时间里,他们优化了软件堆栈,使芯片的性能比开始时高出30倍。您可以看到他们在市场上取得成功所需的潜力,但他们都需要为这些芯片提供最佳性能,以便它们能够在现实生活中发挥作用。这就是我们在过去几年中所做的。” 在一年的时间里,他们优化了软件堆栈,使芯片的性能比开始时高出30倍。您可以看到他们在市场上取得成功所需的潜力,但他们都需要为这些芯片提供最佳性能,以便它们能够在现实生活中发挥作用。这就是我们在过去几年中所做的。” 在一年的时间里,他们优化了软件堆栈,使芯片的性能比开始时高出30倍。您可以看到他们为在市场上取得成功所需要做的事情的潜力,但是他们都需要为这些芯片提供最佳性能,以便它们能够在现实生活中发挥作用。这就是我们在过去几年中所做的。”
AI / ML在半导体制造和测试中仍处于初期。因此,尽管AI / ML能够发掘出潜在的极端情况并发现潜在的缺陷,但它还是100%不能被信赖的。PDF的David建议对AI / ML保持严格控制,而不要监视用于监视其他算法的算法层。“如果您正在创建机器学习算法来进行预测以修复其他机器学习算法,那么它在计算上将变得非常昂贵,” David说。而且总是有安全模式。如果客户对AI系统的预测信心不足,那么在改进ML算法和模型之前,晶圆厂或OSAT总是可以回到没有AI系统的情况下进行工作。“物理模型和机器学习模型都是预测模型,” Onto的Hao说。“我们发现,通过将物理和机器学习结合在一起,我们可以获得最佳性能。机器学习是物理学的补充。它可以帮助物理,但不会取代物理。”
看完有什么感想?
请留言参与讨论!

如侵权请联系:litho_world@163.com