PVT:金字塔架构的视觉Transformer,助力稠密视觉任务的高效实现
来自南京大学、香港大学等研究机构的研究人员提出了一种基于Transformer的无卷积主干网络架构,称为金字塔视觉Transformer(Pyramid Vision Transformer,PVT),它克服了传统Transformer所面临的诸多困难,可以作为多功能的主干模型服务于包括图像级与像素级预测等多种形式的下游任务。
更多详情,请访问论文原文和项目主页:

论文链接:
https://arxiv.org/abs/2102.12122
代码链接:
https://github.com/whai362/PVT
 后台回复【210315】可直接下载论文PDF~
后台回复【210315】可直接下载论文PDF~
近十年来,卷积神经网络在计算机视觉领域取得了惊人的成就,同时也成为了几乎所有计算机视觉任务的主干网络。但同时,科学家们还在尝试着从多个角度探索无卷积的计算机视觉模型,以进一步提高模型的泛化性与适应性。
近四年来,Transformer模型在自然语言处理领域实现了巨大的突破,在此启发下,视觉领域的研究人员也开始尝试着利用Transformer解决视觉任务。研究人员将视觉任务视为一个可学习查询的字典查找问题,或者利用Transformer解码器在CNN主干网络的基础上对特定任务进行处理。虽然有一系列工作将注意力机制集成到了CNN中,但根据目前的情况来看,关于用无卷积结构的Transformer来实现稠密图像预测任务的研究还很缺乏。
最近,有研究人员探索了利用Transformer进行图像分类的工作Vision Transformer(ViT),将模型的主干结构替换为了无需卷积的操作,实现了有益的探索和尝试。下图显示了几种不同特征抽取方式的细节和对比。
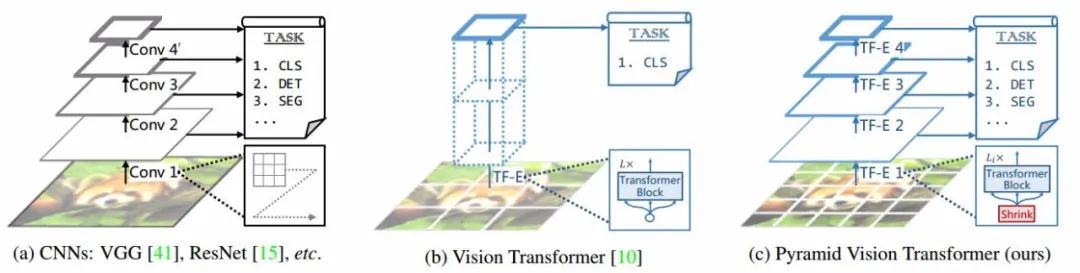
ViT使用柱状结构将粗糙的图像片元作为输入,尽管ViT可以实现图像分类,但却难以实现像素级的稠密预测任务(包括目标检测、图像分割等),这主要是由于其输出特征图仅仅只有单个尺度的低分辨率,同时在通常大小的图像上也需要异常庞大的计算开销。
为了克服这些问题,本文提出了基于Transformer的无卷积主干网络架构,称为金字塔视觉Transformer (Pyramid Vision Transformer,简称PVT),可以作为多功能的主干模型服务于包括图像级与像素级预测等多种形式的下游任务。
具体来讲,不同于ViT,PVT克服了传统Transformer所面临的困难:
通过细粒度的图像片元作为输入,来学习用于稠密预测任务的高分辨率表达;
引入了渐进式的金字塔架构,随着网络深度加深,减小Transformer的序列长度,大幅度减小了计算开销;
采样空间简约注意力层进一步缩减学习高分辨特征图的资源开销。
总体来看,PVT架构可以带来下列优势:
首先,与传统CNN主干网络相比(其感受野随着网络深度加深而扩大),PVT总是可以通过注意力机制对所有小图像片实现全局感受野,比CNN的局域感受野更适合于目标检测和分割等操作。
其次,与上图的ViT相比,PVT先进的金字塔架构可以更为容易地插入其他稠密表示任务的流程中去(包括RetinaNet、Mask-RCNN等模型)。
此外,通过与其他Transformer解码结合,PVT可以构建出适应于多种任务的架构,例如,PVT+DERT用于目标检测,通过完全非卷积的模型实现高性能的目标检测性能。
自注意力与视觉Transformer
由于卷积网络的权重在训练结束后就被固定下来,它对于动态变化的输入缺乏灵活性。因此,许多方法通过自注意力机制来缓解这一问题。
其中,非局域模块尝试为长程时空依赖性建模,提升了视频分类的精度;但非局域操作需要大量的内存开销和计算资源;交错(Criss-cross)方式仅仅通过交叉路径生成稀疏注意力图进一步减少了复杂性;而后独立的自注意力机制利用局域自注意力单元代替了卷积层。AANet则通过自注意力与卷积的操作实现了优秀的结果。DETR使用Transformer解码器来为目标检测建模,将其视为可学习查询的端到端字典查询问题,成功地剔除了非极大值抑制等手工操作。在DETR的基础上,其变种则引入了可变形注意力层聚焦与稀疏纹理元素,实现更为快速的收敛和更高的性能。
近年来,视觉Transformer(ViT)采用了纯粹的Transformer模型,通过将图像分类为一系列图片元序列实现了图像分类任务。DeiT模型通过使用先进的蒸馏方法进一步拓展了ViT。但是,与先前的研究任务不同,本文提出的方法将在Transformer中引入金字塔结构,并设计纯粹的Transformer主干网络用于稠密视觉预测任务(稠密预测任务的目标在特征图的基础上用于实现像素级的分类或回归,其代表性任务是目标检测和语义分割)。
金字塔视觉Transformer (PVT)
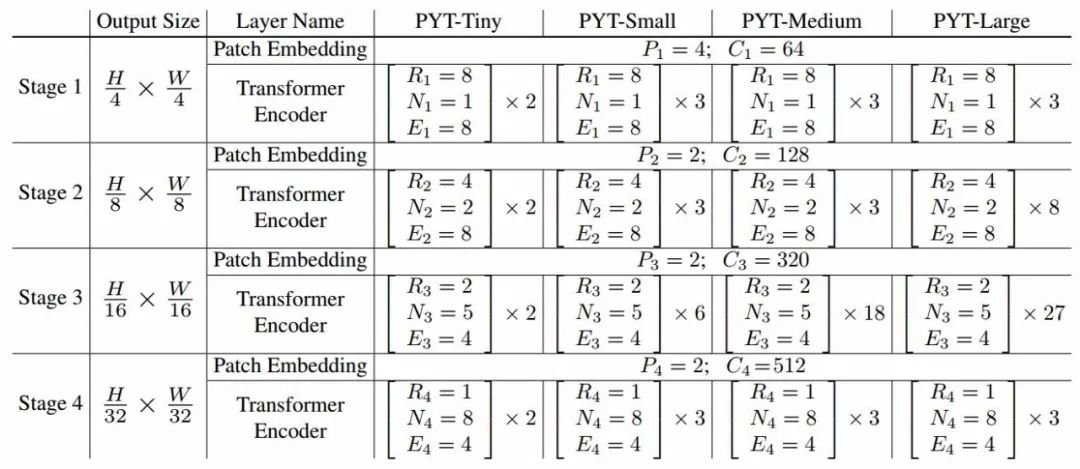
本研究的目标是将金字塔架构引入Transformer中,生成多尺度特征图用于稠密视觉预测任务。PVT的整体架构如下图所示,其中有四层不同尺度的特征图,四层结构共享相同的架构,其中包含了嵌入层和Li层的Transformer编码层。
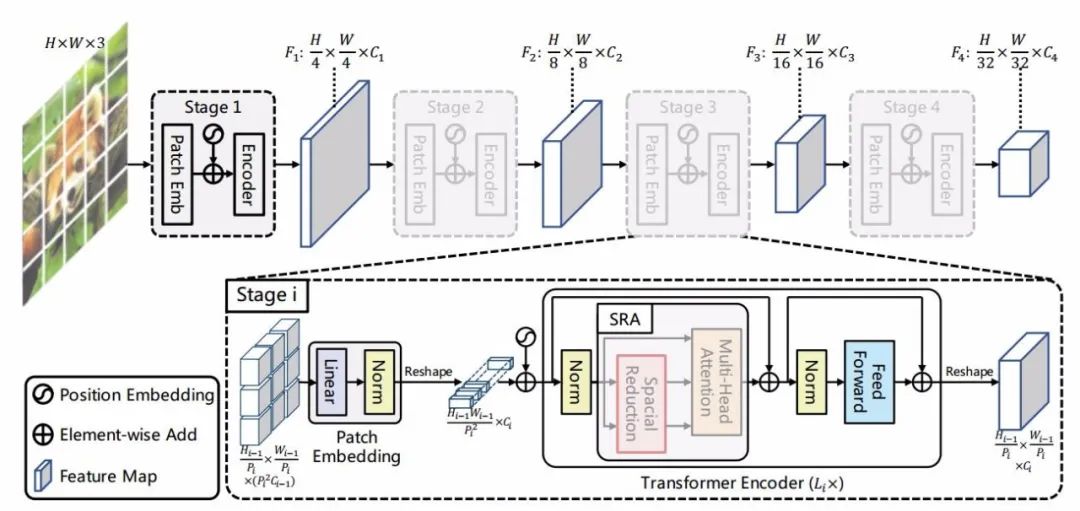
本文提出PVT的整体架构,模型分为四个部分,每个部分由片元嵌入层和transformer编码器构成;随后是尺寸从1/4到1/32的金字塔结构。
在第一阶段,H × W × 3的图像将被分为4 × 4的片元送入模型以获得高分辨率的特征图。随后将展平的图像片元送入线性投射并获取C1通道的嵌入特征片元。然后,嵌入片元和位置嵌入一同送入L1层的Transformer编码器中,输出特征图F1,其尺寸为H/4 × W/4 × C1.在同样的操作下,将前一阶段得到的特征图送入后续阶段得到F2、F3、F4特征图,最终得到不同层级的特征金字塔{F1、F2、F3、F4},可以有效用于下游的视觉任务。
特征金字塔操作
CNN主干网络使用不同的卷积步长得到多尺度特征图,与CNN不同的是,本文提出的PVT方法采用渐进式的压缩策略通过片层嵌入层来控制特征图尺度。第i层的片元尺寸为Pi,首先将前一层特征图分为多个Pi × Pi的片元,而后每个片元被展平并映射到Ci维嵌入上,最终得到了H/Pi × W/Pi × Ci大小的特征图,其尺寸都比输入缩小了Pi倍。通过这样的方式可以灵活地调整每一阶段特征图的尺度,有效构建Transformer的特征金字塔。
Transformer编码器
针对第i阶段的Transformer,其拥有Li个编码层,每个编码层由一个注意力层和前向传播层构成。由于本文需要处理高分辨率特征,所以提出了一种空间缩减注意力层(spatial-reduction attention,SRA)来代替编码器中传统的多头注意力层(multi-head attention,MHA)。
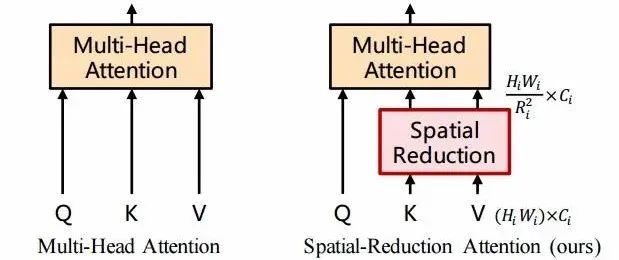
多头注意力与空间减约注意力比较,其中SRA的计算与内存开销比SRA要少,使其更适合于高分辨率特征图的操作。
与MHA类似,SRA同样也需要查询Q,键K和V作为输入,其输出则是优化后的特征。其不同在于SRA会在注意力操作前减小K和V的空间尺度,大幅度减小了计算和内存开销。其表达式如下所示:
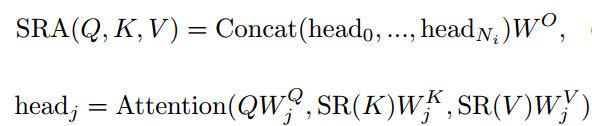
这部分的作用是将K与V的维度缩减,实现平方级数的计算量缩减,让处理大尺度高分辨率的特征图成为可能。为了尽可能比较模型的优劣,研究人员设计了Tiny、Small、Medium、Large等一系列PVT模型进行进一步研究。
对比讨论
研究人员详细对比了ViT和PVT的各方面优劣。它们都是纯粹的不包含卷积的Transformer模型,其主要的不同在于PVT增加了金字塔架构。与传统的Tranformer类型相比,ViT的输出序列长度与输出相同,这意味着ViT只具有一个特征尺度。此外由于资源限制,ViT的输出只能是粗粒度的低分辨率结果(16,32像素的),难以将ViT直接应用于需要高分辨率多尺度特征图的稠密预测任务上。
而PVT则可以通过渐进式的特征图缩减来对Transformer的结果进行路由,可以像传统CNN一样生成多尺度的特征图。此外,研究人员还设计了简单并有效的注意力层SRA,用于高效处理高分辨率特征图,减小计算量和内存的消耗。在这些设计的驱动下,本文提出的方法不仅可以实现更为灵活的多尺度特征图抽取,同时易于与其他已有模块集成广泛应用于不同的下游任务,对于高分辨率输入具有更加友好的计算与存储需求。
实验结果
为了展示新模型的性能,研究人员将这一架构与ResNet和ResNeXt等CNN主干网络进行了比较,同时也分析了ViT和Dei等Transformer模型的性能,并在图像分类、目标检测和语义分割等任务上进行了具体的分析。
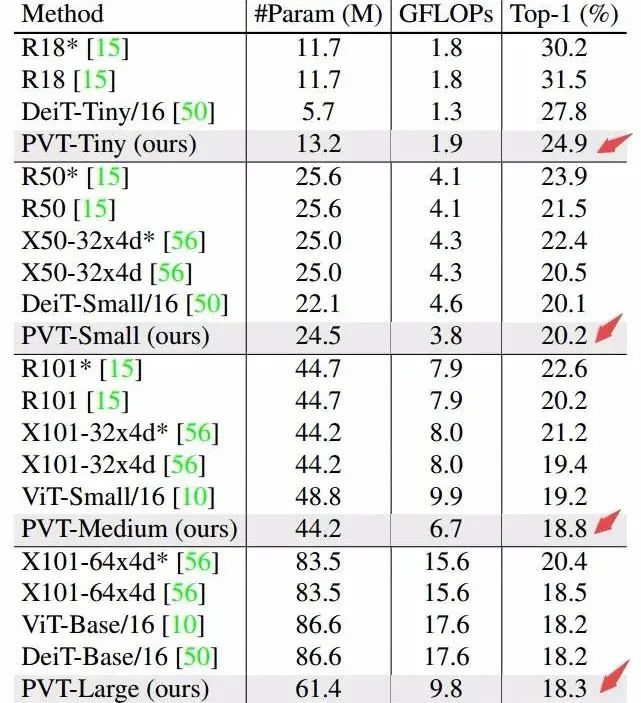
下表展示了PVT模型在相同参数和计算开销的情况下实现达到了更好的性能。金字塔结构对于稠密预测任务提升很大,但对于图像分类任务则提升有限。而ViT和DeiT则因为分类任务而定制,所以在稠密预测任务中表现并不好。
针对目标检测任务,研究人员在coco数据集上对PVT架构进行了测试,在参数规模相似的情况下,PVT架构可以在目标检测任务上取得优异的结构,这证明了PVT可以有效替代CNN结构。
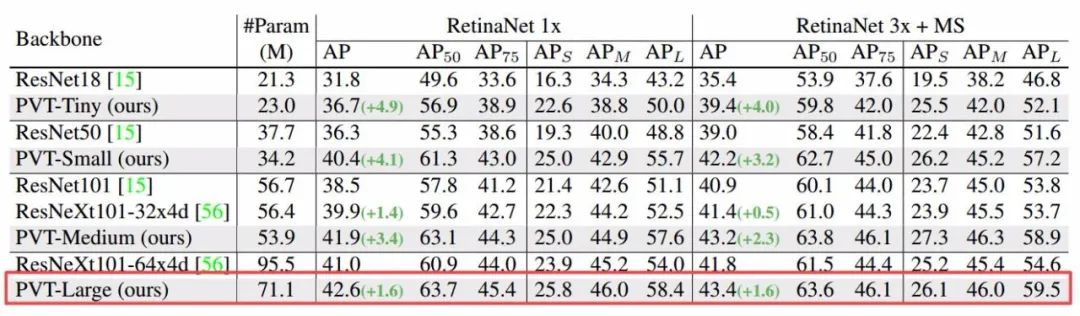
同样,在实例分割任务上,Mask R-CNN+PVT-Tiny架构比ask R-CNN+ResNet18高出3.9个点,甚至比ask R-CNN+ResNet50还高出0.7个点。Mask R-CNN+PVT-Large实现了最高40.7的mAP性能。
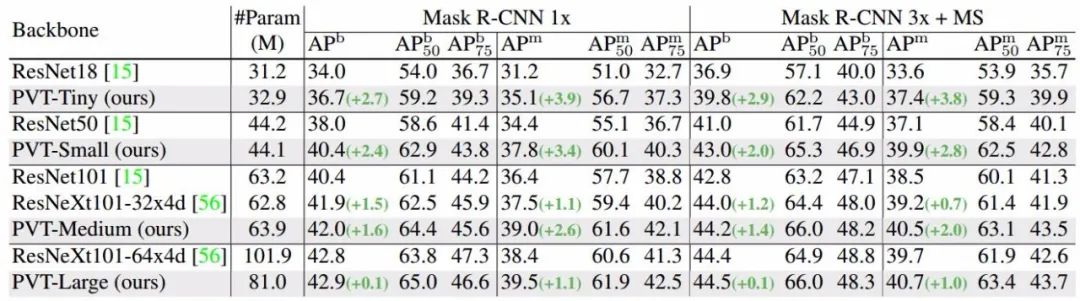
此外,在语义分割上,PVT架构也显示出了强大的能力。FPN+PVT-Large在参数量小20%的情况下直接比FPN+ResNeXt101-64x4d高出了1.9mIo,证明它可以利用全局的注意力机制抽取比CNN更优异的特征。
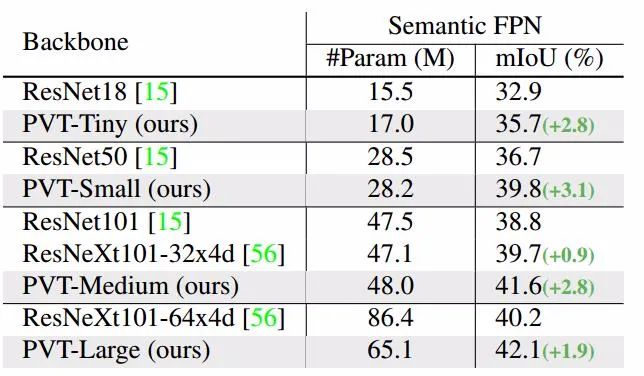
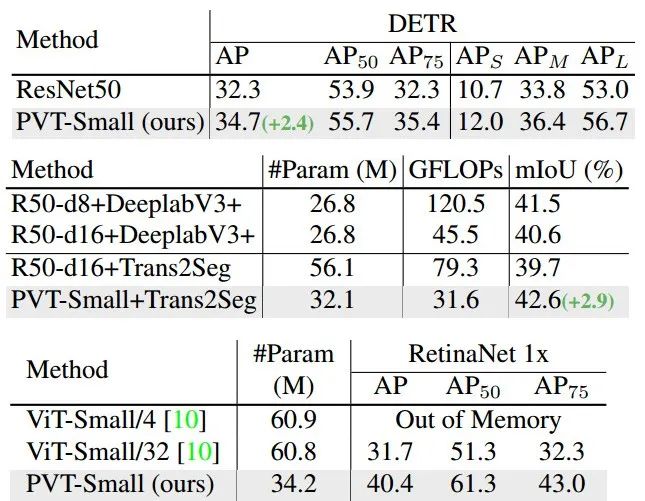
最后,研究人员还利用纯粹的Transformer架构进行稠密视觉任务,包括目标检测和分割任务。
From: 南京大学等研究机构;编译:T.R
Illustration by Oleg Shcherba from Icons8

扫码观看!
本周上新!

关于我“门”
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com

点击右上角,把文章分享到朋友圈

扫二维码|关注我们
微信:thejiangmen
bp@thejiangmen.com
点个“在看”,分享好内容