我仅用一支激光笔就“干翻”了自动驾驶汽车——对抗攻击从未如此防不胜防......
原创
青暮、陈大鑫
AI科技评论
今天
收录于话题
作者 | 青暮、陈大鑫
攻击
AI
模型有多简单?
一束
激光
就够了!
近日,来自阿里
安全
的专家发布了一项新研究,只要用简单的
激光笔
,就可以让
AI
模型不再有效。在这个研究中,他们
设计
了一种
算法
,可模拟光束对
AI
模型进行“攻击”,
这种
测试
方法还在现实世界中得到了
验证
,且“攻击”极易操作
,对现有基于
AI
的视觉系统更具威胁,例如基于AI视觉的
自动驾驶
。
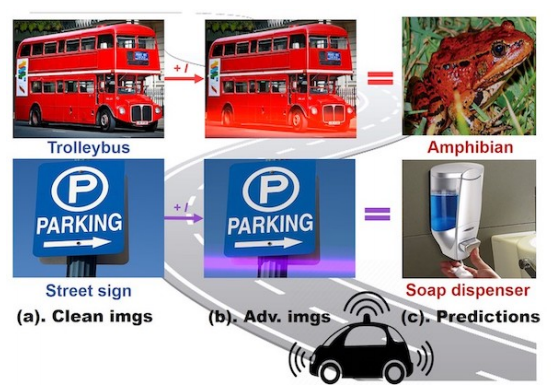
当不同
频谱
的光束打在同一个物体上,
AI
可能将该物体识别错误,比如将停车标识识别成顺利通行。
一束
激光
可能让
自动驾驶汽车
对交通标识识别错误
难以想象,假如一个人正在飞奔的
自动驾驶汽车
上闭眼休息,
AI
将“前方有危险”识别成“通行”后直接坠入万丈悬崖:
或者直接无法识别前方行人,那对于行人而言将是一场噩梦。
还有,
自动驾驶汽车
的摄像头受到
激光
束干扰时,
会将“无轨电车”识别为“两栖动物”,将“路牌”识别为“皂液分配器”。
第一种情况可真是吓人。假设一个人正坐在一辆
自动驾驶汽车
上睡觉,突然横向冲过来一辆无轨电车,
AI
却以为那不过是一只蛤蟆,而它显然没有动物保护意识,也觉得蛤蟆构不成威胁......
“攻击
AI
远非需要人为去制造对抗样本,一支简单的
激光笔
就可以。
我们想通过这个研究揭示
AI
模型一些之前没有被探索过的‘错误’,从而‘强壮’AI,让它未来能抵挡这种‘攻击’,也让相关从业者重视提高AI模型的
安全
性。
”阿里
安全
图灵实验室负责人薛晖说道。
深度学习
图像识别在一定的光照条件下其性能会受到影响,这种现象已经众所周知。但是,
用
激光
干扰
深度学习
的可能性是怎么被发现的呢?
“主要是两方面原因,一方面是之前的物理攻击大多都是通过贴对抗Patch这种引入人工干扰方式使模型识别出错,我们就在思考是不是有其他的攻击形态,能对图像识别有攻击效果(
激光
攻击是在需要攻击的时候发射激光,并不需要贴Patch);另一方面也是在2016年某著名汽车
自动驾驶
系统在强光天气下误识别导致的致命车祸这件事上受到启发,让我思考一些极端光线条件本身是否就会对
人工智能
系统构成威胁。”本论文的第一作者札奇告诉
AI科技评论
,札奇是澳大利亚斯威本科技大学博士三年级在读,目前在阿里
安全
图灵实验室研究实习。
目前阿里
安全
这篇论文已经在不久前被CVPR 2021收录:
论文链接:https://arxiv.org/abs/2103.06504
相信这篇论文出来后,某著名
自动驾驶汽车
公司至少可以避免一次再度“撞上”热搜。
1
把王蛇当热狗
激光
对抗攻击不仅仅是让图像识别出错。通过改变激光的波长,还可以让图像识别结果不断发生变化。比如,一条王蛇在从紫色激光到红色激光的干扰下,依次会被识别为袜子、台子、
麦克风
、菠萝蜜、绿曼巴、玉米......
还有......热狗!!!
阿这?也太骇人了吧
,
你敢让
机器人
保姆拿着蛇当做热狗往你嘴里塞?
据了解,
激光
本身的可控变量不止是波长,还包括激光束的宽度、强度等,它们都会对图像识别的干扰结果有一定影响。
有些错误识别案例也特别有趣。例如上面所说,当使用黄色
激光
束时,王蛇被错误地归类为玉米,而王蛇和玉米的质地之间确实存在一些相似之处。
还有就是,蓝色
激光
束使海龟被错认为水母:
而红色
激光
束则会使收音机被错认为空间加热器。
研究者之后进行了广泛的实验,以评估论文中提出的
激光
束干扰法(AdvLB)。
他们首先在数字模拟环境中黑盒评估
AdvLB——它可以对ImageNet的1000张正确分类的图片实现95.1%的攻击成功率。
具体而言,对于每一张图片,研究人员都进行黑盒查询攻击(无法获取模型),也就是查询一下API,返回结果, 然后根据结果修改
激光
参数并并叠加到图像上,再次进行查询API判断是否攻击成功。这1000张图片中,平均每张图片需要查询834次才能成功。“
因为这种攻击方式属于blackbox setting,所以需要很多次尝试。
”阿里
安全
图灵实验室高级
算法
专家越丰介绍道。最后,有95.1%的图片可以攻击成功,而有4.9%的图片由于搜索空间的限制导致无法攻击成功。
研究人员之后还在现实世界中进行了
测试
,使用了以下这些工具:
工具非常简单
,包括三个小型手持式
激光笔
(功率:5mW)——分别能产生波长为450nm、532nm和680nm的低功率
激光
束、用于拍照的
Google Pixel
4 手机。
在室内和室外
测试
中,研究人员分别实现了100%和77.43%的攻击成功率。
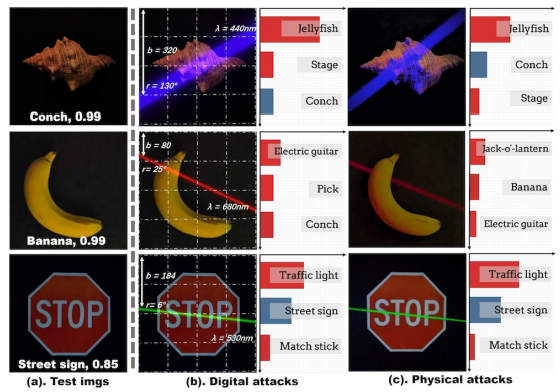
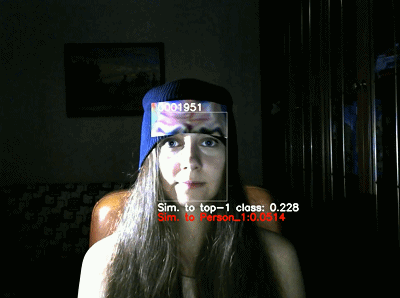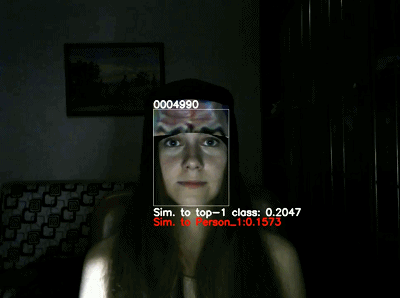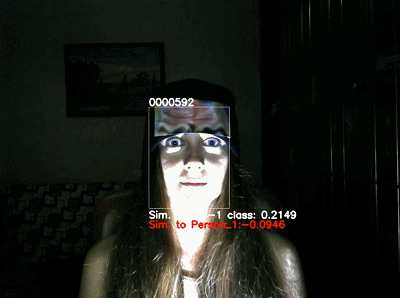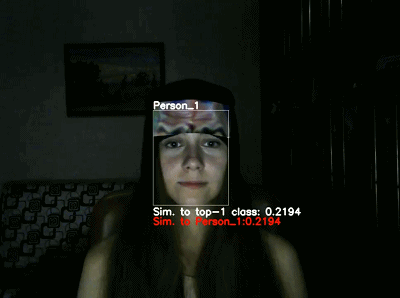
如下图所示,在室内
测试
中,目标对象包括海螺、香蕉和停车标志。其中中间一列图像展示的是数字模拟结果,第三列图像展示的是室内测试结果,可以发现两者的结果是一致的。
接下来是户外
测试
。研究人员使用了停车标志来测试,总体而言,攻击成功率为77.43%,这个成功率估计会让某著名
自动驾驶汽车
汽车撞上天。
以上这些结果都进一步证明了
激光
束对现实世界的威胁。
有些同学可能会觉得困惑,
在现实世界加上
激光
干扰是怎么做到的?
毕竟
激光
具有聚合性,不太容易发生散射,一般而言很难从侧面看到光束轨迹,更不用说像上述图片中那么明显的亮度了。
对此,札奇向我们解释:“一开始我们考虑的是
光的丁达尔效应
,拍摄任意物体过程同时拍到光线轨迹,但这种因为光线轨迹能量很弱,这种情况下确实要求比较暗的环境。另一种方式是
在
激光笔
头部放置一个光缝片
,可以直接打在物体上,因为
激光
聚焦处能量较强,所以只要不是户外光线极强的情况下都有一定效果,类似于白天的红绿灯,虽然比黑天情况下弱一些,但还是有可见性。但是我们确实主要考虑的是‘夜间
安全
’问题。”
例如下图中展示了
激光
在丁达尔效应下从侧面看到的光束轨迹。
在实验过程中团队发现,光束打在一定范围内都有较高成功率(如下动图所示),因此也可以一定程度适应现实世界中的动态环境。
从
安全
角度来说 ,这种攻击方法也可以作为一种模拟检测,
测试
模型在这种条件下是否足够鲁棒。
下图则展示了
激光
经过光缝片打在交通标志上的场景:
然后是白天光照下的室内和室外场景:
研究人员在分析了由
激光
束引起的DNN的预测误差之后发现,
引起误差的原因可以大致分为两种:
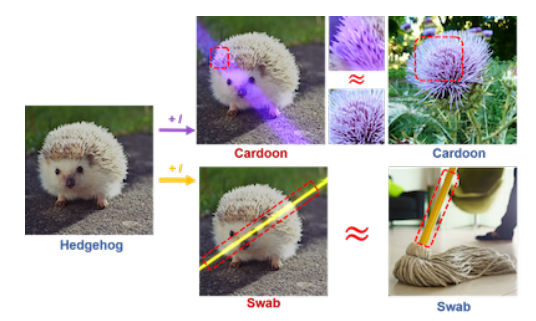
第一种,
激光
束的颜色特征改变了原始图像,并为DNN提供了新的线索。如下图所示,当波长为400nm的激光束照射在“刺猬”上时,
刺猬的刺与
激光
束引入的紫色结合形成了“刺苞菜蓟”的类似特征
,从而导致分类错误。
第二种,
激光
束引入了特定类别的一些主要特征,尤其是与照明相关的类别,例如“蜡烛”。当激光束和目标对象同时出现时,DNN可能会更偏向于由激光束引入的特征,从而导致分类错误。或者像上图那样,
黄色
激光
束本身就和拖把杆子有相似,从而误导DNN识别为“拖把”。
“最重要的影响因素是
激光
的‘强度’,激光越强,越能被拍照
设备
捕捉。”
札奇说道。
2
“chua的一下”,防不胜防
大多数现有的物理攻击方法都采用“粘贴”法
,也就是将对抗性扰动打印为标签,然后将其粘贴到目标对象上。
例如,只需用普通打印机打出一张带有图案的纸条贴在脑门上,就能让
人脸识别
系统出错。
或者用“对抗补丁”让目标检测系统看不出人是人。
当然,上述这些方法都相对比较繁琐,最简单的可能就是在停车标志上贴上黑白小贴纸了。
多模态学习近年来成为了
人工智能
领域的研究热点,但是很快,
针对多模态模型的攻击方式也出现了。
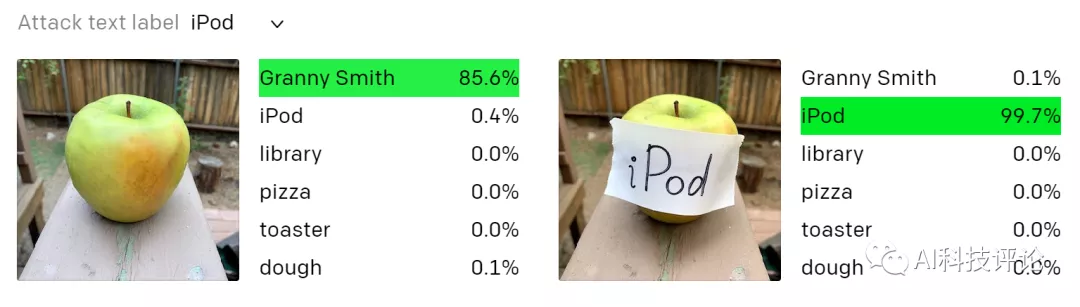
例如,
OpenAI
提出的CLIP模型可以对图片生成文字解释,并且研究发现其网络中存在多模态神经元,可以同时对同一事物的图像和文字激活。例如,当在这个Granny Smith
苹果
贴上一个标有“ iPod”的标签时,模型在零样本设置中将其错误地识别成为iPod。
OpenAI
将这些攻击称为印刷攻击(typographic attacks)。他们认为,如上所述的攻击绝非学术上的考虑。通过利用模型强大的文本阅读功能,即使手写文字的照片也常常可以欺骗模型。像“对抗补丁”一样,这种攻击在野外场景也有效。但与此类攻击不同,
它只需要笔和纸即可。
而基于
激光
的攻击不仅仅具有简便性,光的特性也使其变得更加棘手。
研究人员警告,人们可以在被攻击的目标物体被摄像头捕获之前的瞬间在很远的距离外实施攻击,从而防不胜防!
“
很简单,
激光笔
打光chua的一下,很快啊。
因为其简易便捷,对
人工智能
系统来说更容易成为普遍的威胁。” 札奇说道。
当无人驾驶汽车接近停车标志时,即使在短时间内无法识别停车标志,也可能导致致命事故。
研究人员还指出,这种攻击方式在研究弱光条件下视觉系统的
安全
威胁时特别有用,下图就展示了在光照条件较差时
激光
攻击的优势。可以同时应用于数字和物理环境,也是其优势所在。
所以总结来说,
激光
束攻击具有隐蔽性、瞬时性、弱光性以及多环境适用性的特点。
研究人员指出,
当前这种攻击方法尚存在缺点,其中一个就是它在动态环境上的攻击时仍会受到限制,但未来会发展到什么程度,还很难预料。
图像识别很早也被发现对于位置、角度、光照(自然光照、人工灯光)等条件很敏感,那么
激光
干扰图像识别的本质是更加接近于这种敏感性,还是更加接近于对抗攻击呢?
对此,札奇表示:“
其实这二者并不矛盾
,对抗攻击即能按照攻击者的意图通过干扰的方式定向的影响模型的输出,当攻击的成功率很高时,我们就应该把这种方法纳入到一种
安全
威胁来考虑,来尽可能减小模型将来的安全隐患。我们的攻击本质上更接近于敏感性,或者也叫泛化性,因为哪怕
激光
也是属于光照条件的一种,在攻击过程中我们并没有加其他的人工干扰,仅仅是一束光。”
3
未来规划
最后,自然是灵魂之问:
怎么解决这个
安全
隐患?
研究团队目前尚未找到一个完美的方案,
“其实数据增强也可以一定程度解决这个问题,但是数据增强和对抗训练的本质无异,我们也尚在探索这个问题。”
目前在
AI
模型的
安全
性方面,主要表现在攻击和防御上。这项工作是在图像成像前加入
激光
,从而使得模型在识别加入光线后的图片出错。这说明了目前的
深度学习
模型对光照变化是不鲁棒的。除了光照以外,其实模型对发生模糊、天气变化时也会识别错误。
针对
安全
性问题,越丰接着说道:
“为了提升
AI
模型的
安全
性,我们需要探索鲁棒
机器学习
方案,在数据和模型的各个方面进行鲁棒性的增强,例如更强的数据预处理,探索更加鲁棒的网络结构,增加辅助Loss防止模型过拟合,引入多模态的增强模型的鲁棒性等。鲁棒机器学习并不是一个单一
算法
,更像是一个系统构建,需要从多个维度、多个层面提升
AI
模型的鲁棒性。”
札奇告诉我们,在未来,他们将展开以下的研究计划:
1、改进所提出的对抗性
激光
束(AdvLB),使之更适应真实动态的环境。
2、考虑光强度参数的优化,用模拟的
激光
束创造出更隐蔽的对抗样本。
3、探讨使用其他光模式(如聚光灯)和光源(如自然光)进行对抗性攻击的可能性。
4、将AdvLB应用于其他
计算机视觉
任务,包括目标检测和目标分割。
5、针对此类攻击开展对应有效的防御策略。
AI科技评论
聚焦
AI
前沿研究,关注AI青年成长
1770篇原创内容
公众号
点击“
阅读原文
”,进入直播间预约,避免错过精彩分享!
加入
AI科技评论
顶会交流群
,和同行学者分享学术心得!(请加
AI科技评论
官方微信
aitechreview
,拉您进群)
由于微信公众号试行乱序推送,您可能不再能准时收到
AI科技评论
的推送。为了第一时间收到
AI
科技评论的报道, 请将“
AI科技评论
”设为
星标账号
,以及常点文末右下角的“
在看
”。
预览时标签不可点
收录于话题
#
个
上一篇
下一篇
阅读原文
阅读
分享
收藏
赞
在看
已同步到看一看
写下你的想法
前往“发现”-“看一看”浏览“朋友在看”
前往看一看
看一看入口已关闭
在“设置”-“通用”-“发现页管理”打开“看一看”入口
我知道了
已发送
取消
发送到看一看
发送
我仅用一支激光笔就“干翻”了自动驾驶汽车——对抗攻击从未如此防不胜防......
最多200字,当前共
字
发送中







 ,你敢让机器人保姆拿着蛇当做热狗往你嘴里塞?
,你敢让机器人保姆拿着蛇当做热狗往你嘴里塞?













 ,你敢让机器人保姆拿着蛇当做热狗往你嘴里塞?
,你敢让机器人保姆拿着蛇当做热狗往你嘴里塞?