细粒度图像处理再下城:华为诺亚提出TNT, 深入理解图像局域细节

纯Transformer的视觉模型通常将图像视为一系列图像片序列,而忽略了每个图像片元内部的局域相关信息。
为了解决这一问题,来自华为的研究人员提出了一种新颖的Transformer-iN-Transformer (TNT) 架构,使得模型可以更好地关注局域信息,实现了较大的性能提升。
Transformer自从在自然语言处理领域称霸后,已经开始向视觉领域进军,并且在图像分类、检测等领域取得了一系列重大进展,向人们展示了如何在即使没有卷积的情况下利用注意力机制有效处理图像信息。
然而最近纯Transformer的视觉模型通常将图像视为一系列图像片序列,而忽略了每个图像片元内部的局域相关信息。为了解决这一问题,来自华为的研究人员提出了一种新颖的Transformer-iN-Transformer (TNT) 架构,在原始基于图像片元序列Transformer的基础上,对图像片元内部的像素进行序列化实现了像素级的表示。具体来讲,外部的transformer利用了图像片的嵌入表达,而内部的transformer利用了像素级的嵌入表达,这使得模型可以更好地关注局域信息,实现了较大的性能提升。

Transformer开创视觉任务新方式
Transformer是一种典型的自注意力神经网络架构,自从问世就被被广泛应用于自然语言处理领域,造就了著名的BERT和GPT-3模型。而自然语言处理领域的成功也让视觉领域的研究有了新的发展方向,transformer已经开始全面进入图像处理、图像识别、目标检测等视觉领域的核心任务中,例如DETR将目标检测任务视为集合预测任务,并利用transformer架构实现检测;IPT则使用transformer处理多种底层视觉任务。
与CNN模型相比,这些transformer的模型展示了应用于视觉领域的巨大潜力!由于其提供了一种与图像形式无关计算范式,与卷积完全不同的transformer吸引了众多研究人员的关注。
其中iGPT作为这一领域的先驱,使用纯粹的transformer模型和自监督预训练实现了图像识别等相关任务;ViT则创造性地将图像视为patch序列,并利用transformer编码器架构进行分类;DeiT进一步探索了ViT中的数据效率和蒸馏过程。与CNNs相比,transformer模型可以在不引入bias的情况下实现可媲美的结果。
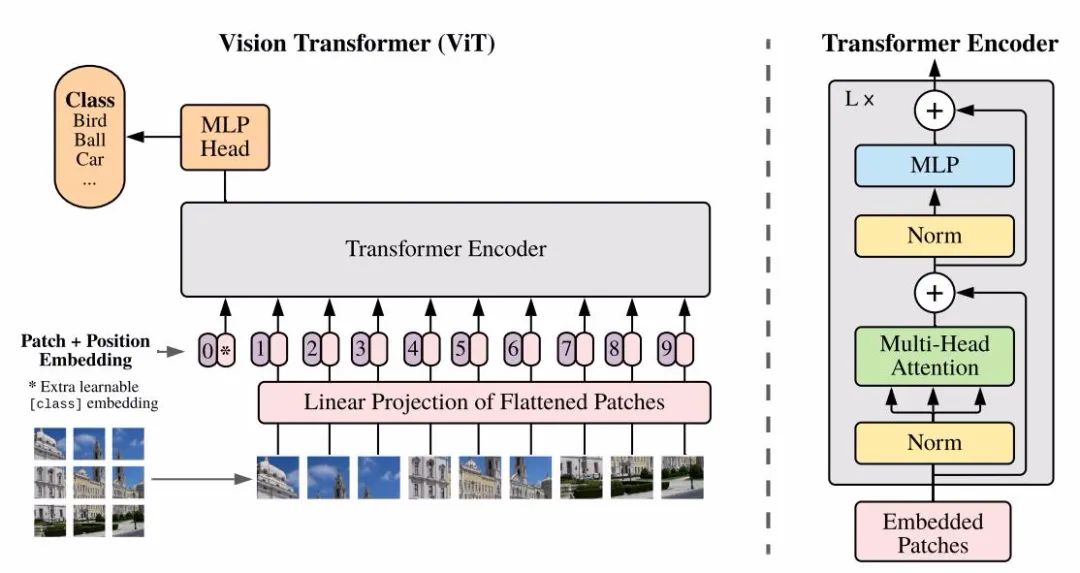
ViT的基本架构,其中使用了典型的transformer
在开始本文的探索之前,让我们先回忆一下这一领域先驱者ViT的思想。它将图像分割为一系列小图像片元序列,每一个片元被转换为一个向量嵌入。这一嵌入通过原始的transformer架构进行处理,使得图形识别问题被转换为了标准的transformer序列处理任务。这一方式成为了视觉transformer的引路人,后续的DeiT, ViT-FRCNN, IPT和SETR都采用了相似的方式。
然而,这种方法有一个明显的缺陷,二维图像的局域信息至关重要,CNN的特性之一就是对局域信息的有效处理。这种图像片元作为序列单元的方式忽略了片元内部有效的局域信息,而这对于视觉任务特别是细粒度的、稠密的生成式任务至关重要。直接向嵌入映射的过程摧毁了内部的空间信息,使得模型难以学习到细粒度特征。
正是在这样的思考下,研究人员基于层次的思想提出了内外两个transformer联合进行学习的新架构TNT,使得模型可以同时学习patch级别的序列特征和内部的像素级的局域细节特征。
Transformer in Transformer
TNT的架构如下图所示,是一种内外两级的层次架构。左图展示了网络的基本架构,右图展示了TNT单元的细节实现。
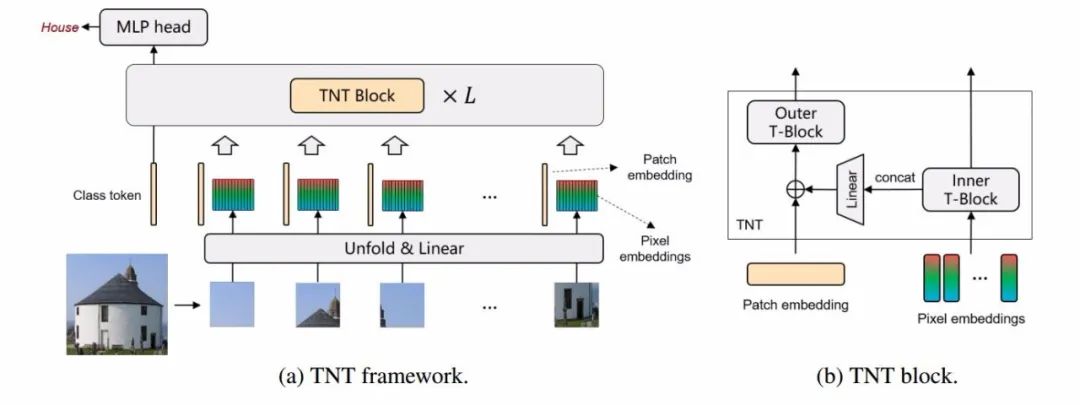
本文提出的架构和模块,其中省略了位置编码。patch和(超)像素嵌入分别用淡黄色和彩色表示。
具体来讲,图像首先被分为一系列的图像片序列,而后每个序列又被细分为更小的(超)像素序列,从而利用transformer将他们分别编码成片元嵌入和像素嵌入两种形式,外部的transformer着眼与对(图像)片元序列的编码得到全局的相关性,而内部的transformer则着眼于对局域信息的编码得到细粒度的信息。在此基础上,局域信息和全局嵌入映射到相同的空间内并加和,实现了在全局patch相关性的同时保持了局域的细节信息。此外,patch和pixel级别的位置编码信息也同时被引入进来以保持空间信息。最终在局域和全局信息的协同下,提升这种新型模型对于图像特征的表达能力,并在ImageNet基准上实现了非常好的实验性能。
在TNT中存在两条数据处理流程,一条针对图像片元间进行操作,而另一条则针对图像内部的像素间进行操作。在像素嵌入上,研究人员使用transformer模块来探索像素间的相关性。
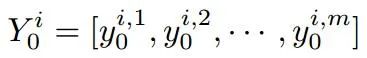
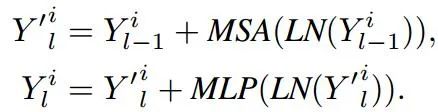
其中Y代表了不同图像片元,而y则代表了像素级的信息。这一过程将构建出每个图片元内部像素间的相关性。
而后在外部的针对图像元序列的transformer上,将内部的像素嵌入转换到图片元嵌入的空间中,并与图像片元的嵌入相加来共同表达:
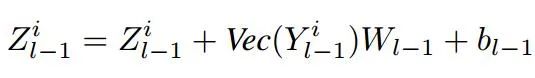
其中Z表示了图像片元的嵌入,中间则是像素嵌入进行线性变换的过程,最终可以表述为标准的transformer过程:
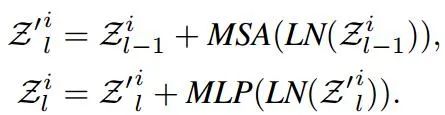
这一外部的transformer可以有效建模图像片元间的相关性。总的来讲,完整的TNT单元同时包含了内部像素嵌入和外部片元嵌入信息:
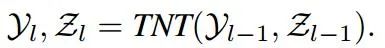
内部着眼于为像素间的相关性建模,外部的则重点考虑片元序列间的信息。通过对TNT单元的多次堆叠,可以构建起完整的transformer-in-transformer结构,对于图像实现更好的特征抽取和学习。
位置编码
在层次transformer的基础上,空间信息对于图像识别任务也具有关键作用。空间编码针对性地解决了这一问题,像素和图像片元的嵌入使用了如下图所示的方法来进行位置编码:
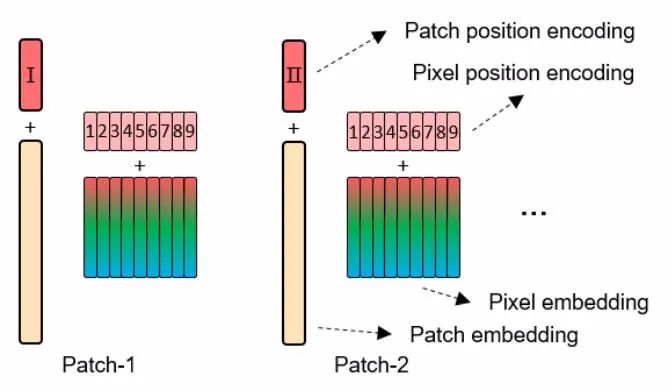
片元级和像素级的位置编码
这里使用了标准的可学习1D位置编码,片元嵌入与位置编码相加,像素嵌入也与相应的位置编码相加。像素级的位置编码在所有的片元内部共享。这样的片元位置编码有效维持了全局空间信息,同时像素位置编码也可以保持局域像素的相对位置关系。
在此基础上,TNT模型与先前的ViT和DeiT模型采用了相同的架构,其片元大小为16x16,片元内部的超像素大小设置为了4x4。为了便于比较,研究人员构建了小型(S)和标准(B)的两种TNT架构,其中多头注意力个数等Transformer参数与先前研究相同。下表描述了两种模型的参数:

TNT的两种变体,其计算量是在224x224的图像上计算得到的。
实验结果
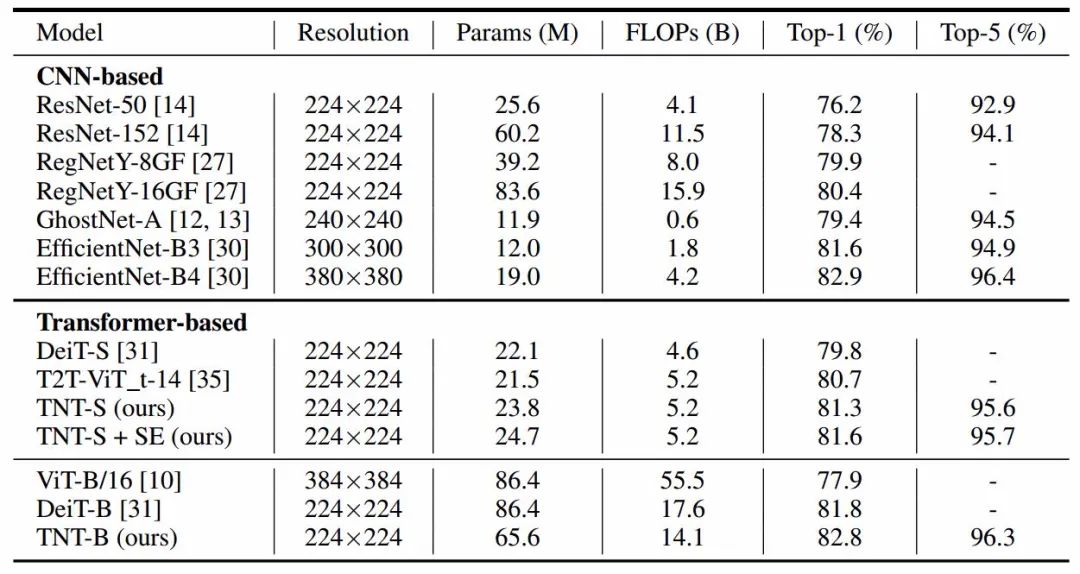
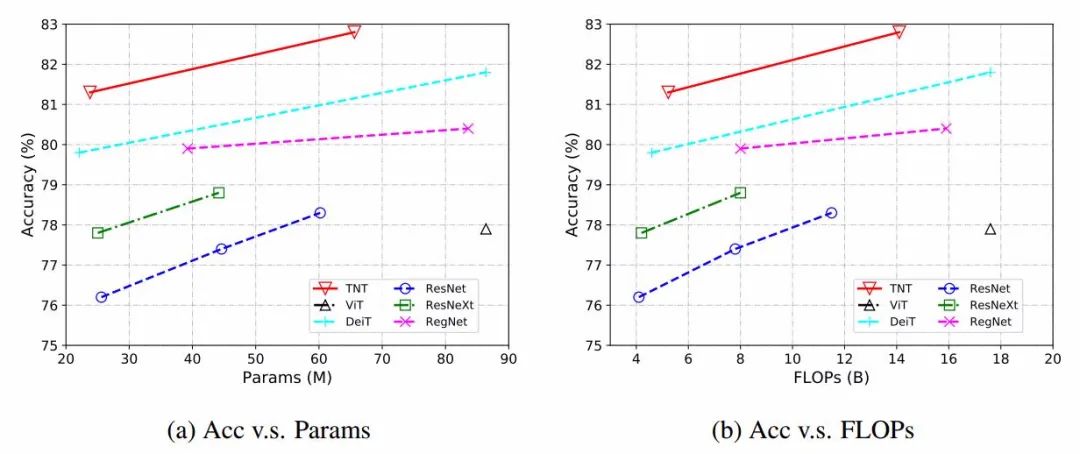
实验表明TNT性能超越了先前的transformer架构,并且可以达到与CNN架构相媲美的效果。在下表中比较了基于CNN模型和基于Transformer模型的两类方法,可以看到TNT-S超过了DeiT-S的Top-1精度1.5%,TNT-B的计算量与EfficientNet-B4接近,达到了相同的效果。
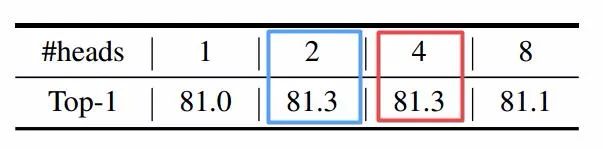
此外还比较了内部transformer多头注意力机制头的数量,发现取值2,4的时候具有最好的性能。
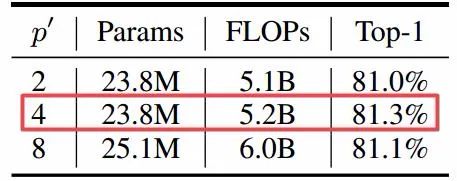
而针对内部(超)像素的大小,研究人员比较了2x2, 4x4, 8x8,可以发现4x4的性能更好。不使用1x1的原因是由于维度太低无法学习到有效的特征。
最后,为了验证学习的有效性,研究人员还可视化了不同层模块的像素级特征图以及patch级别的特征图。在下图中可以看到TNT方法可以保持更多细节的局域特征,比如熊猫的黑白颜色就能在下面TNT的特征图中比ViT有更好的体现。而T-SNE也展示了TNT的特征分布更广泛,具有更强的多样性和表达能力。

而针对patch级别的表示,可以看到随着层级的加深特征变得越来越抽象,与CNN的不同层次的特征具有相似的分布,说明随着TNT模块的堆叠学习到了更高层级的语义特征。

图中浅层block包含更多局域信息,深层则包含了更多抽象信息
这种两层嵌套的transformer结构视觉研究提供了新的思路,也为更细粒度甚至像素级的任务给出了可能的方向,如果想要了解更多详细信息,请参看论文:
作者也将要在不久后放出代码:
https://github.com/huawei-noah/noah-research/tree/master/TNT
From: HuaWei ;编译: T.R
Illustrastion by Oleg Shcherba from Icons8
- The End -

扫码观看!
本周上新!


